
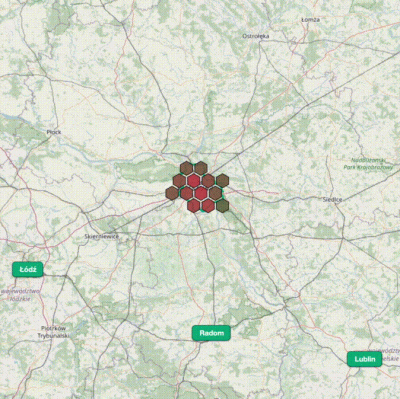
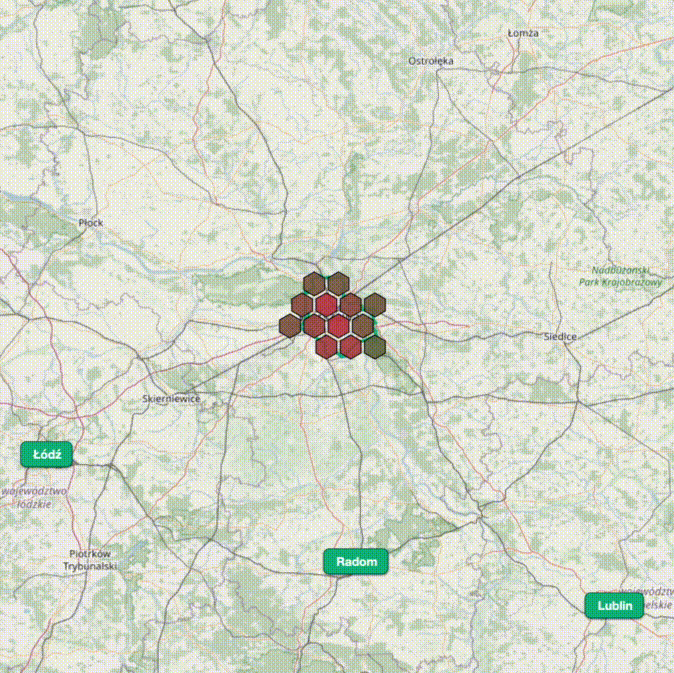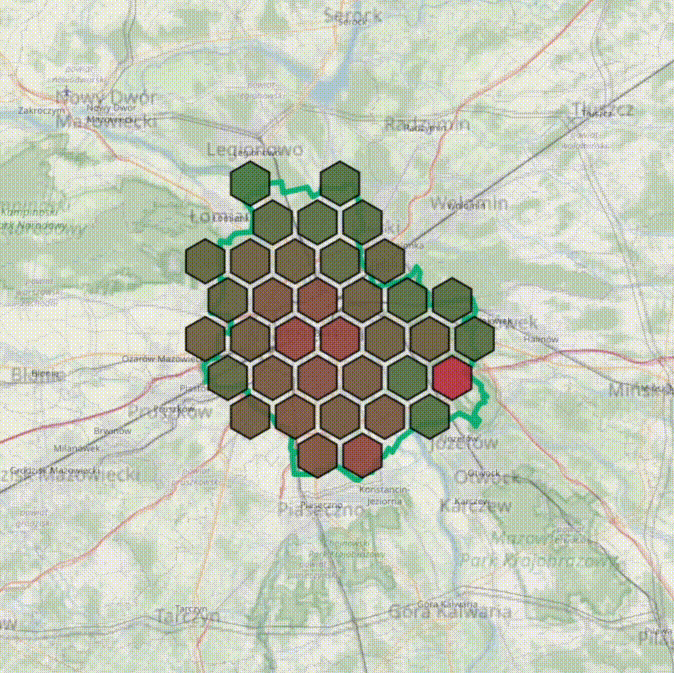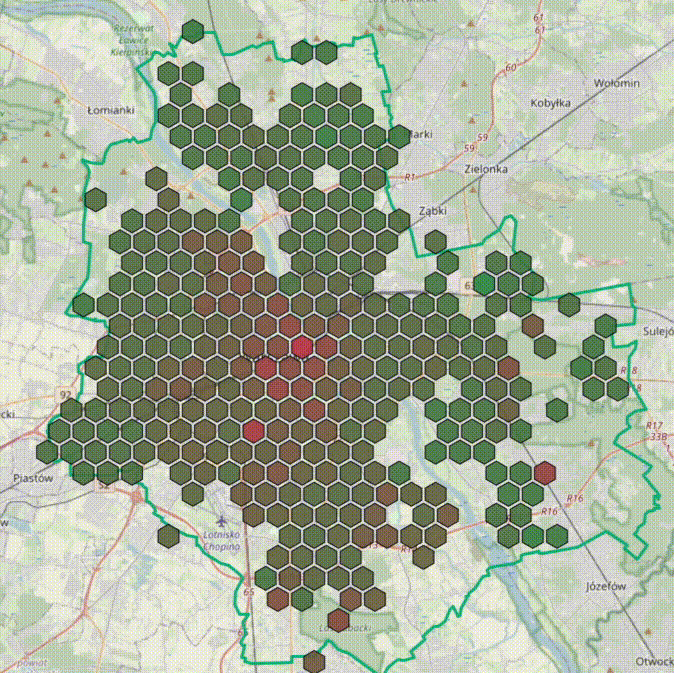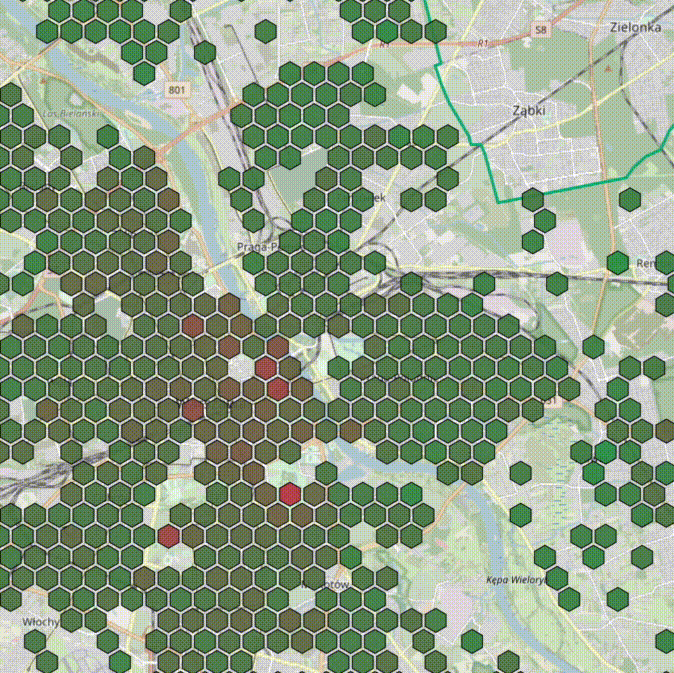
8 miesięcy temu zaczęliśmy pracę nad hexmapą - nowym narzędziem analitycznym w zametr.pl. Jutro będzie dostępna w serwisie.
#zametr #nieruchomosci #warszawa #datascience
#zametr #nieruchomosci #warszawa #datascience
Wszystko
Najnowsze
Archiwum
źródło: comment_1659218937AahAaW9PksZs8WCxaBPxi9.gif
Pobierzwszystkie z tych rozmow byly na data engineera

źródło: comment_1659016916SLp6Z6VrBFJIqYMVGVaCBt.jpg
Pobierz
Sprawdź, jakie zjawiska mogą w nadchodzącym czasie zdominować zaawansowaną analitykę danych.
z
źródło: comment_1658487421ityKX6Hn3VBNDGQkhU06N0.jpg
Pobierz
źródło: comment_16581572002fLuNRzWxIlkppwY5eoaWx.jpg
Pobierz
źródło: comment_16573896439cWMCG3lzH4GWsSRp0Lo08.jpg
Pobierz
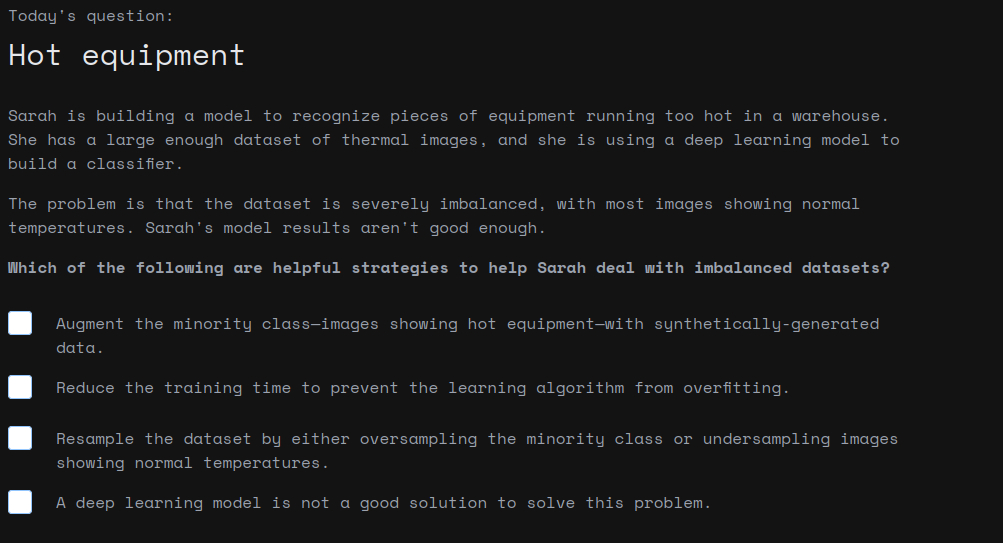
Codzienne pytania z machine learningu, data science i sztucznej inteligencji, razem z wyjaśnieniami i darmowymi materiałami do zgłębienia tematu. Oparte na praktyce, np. jakie działania można podjąć żeby ulepszyć dany model, co może być problemem itp.
z
źródło: comment_16576340653YLvMTraGDP1XO7a9ZNDQU.jpg
Pobierz




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#seo #it #programista10k #zarobki #datascience
Cześć! Mam 30 lat, 3 lata pracuje jako SEO Specjalista i zarabiam 4.500zł netto. Jeszcze 3 lata temu taka pensja była w miarę ok, ale ze względu na inflację czuję, że powinienem zarabiać przynamniej tysiąc złotych więcej. Chciałbym zarabiać docelowo 7k/8k na rękę lecz zastanawiam się czy w tej branży jest to możliwe. W porównaniu
SEO to fajny początek do zarządzania całym marketingiem bo jest to najbardziej analityczny początek
---
Zaakceptował: Eugeniusz_Zua