#datascience
Hej Mirki, tak sobie dlubie proste ETL w #pandas #numpy #python i glowkuje jak tu skrocic czas ladowania trzech duzych (1GB kazdy 900k x 200) CSV. Jedyne co przychodzi mi jeszcze do glowy to dorzucenie multiprocesingu bo duzo sie dzieje, z %pruna widze ze w tej chwili CPU jest waskim gardlem. Probowalem w prymitywny sposob zaladowac to w multi rozrzucajac kazdy plik na osobny
Hej Mirki, tak sobie dlubie proste ETL w #pandas #numpy #python i glowkuje jak tu skrocic czas ladowania trzech duzych (1GB kazdy 900k x 200) CSV. Jedyne co przychodzi mi jeszcze do glowy to dorzucenie multiprocesingu bo duzo sie dzieje, z %pruna widze ze w tej chwili CPU jest waskim gardlem. Probowalem w prymitywny sposob zaladowac to w multi rozrzucajac kazdy plik na osobny
















{kind=link}
W skrócie:
- Robię listę wszystkich plików w zdefiniowanym folderze
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę całkowitą znajdującą się przed literą R (to identyfikator baterii)
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę stałoprzecinkową (powiedzmy, że zawsze z 1 miejscem po przecinku) -> to identyfikator napięcia
- Przeszukuję tę listę plików, aby znaleźć ostatnią liczbę całkowitą -> to
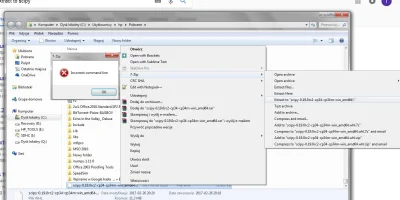
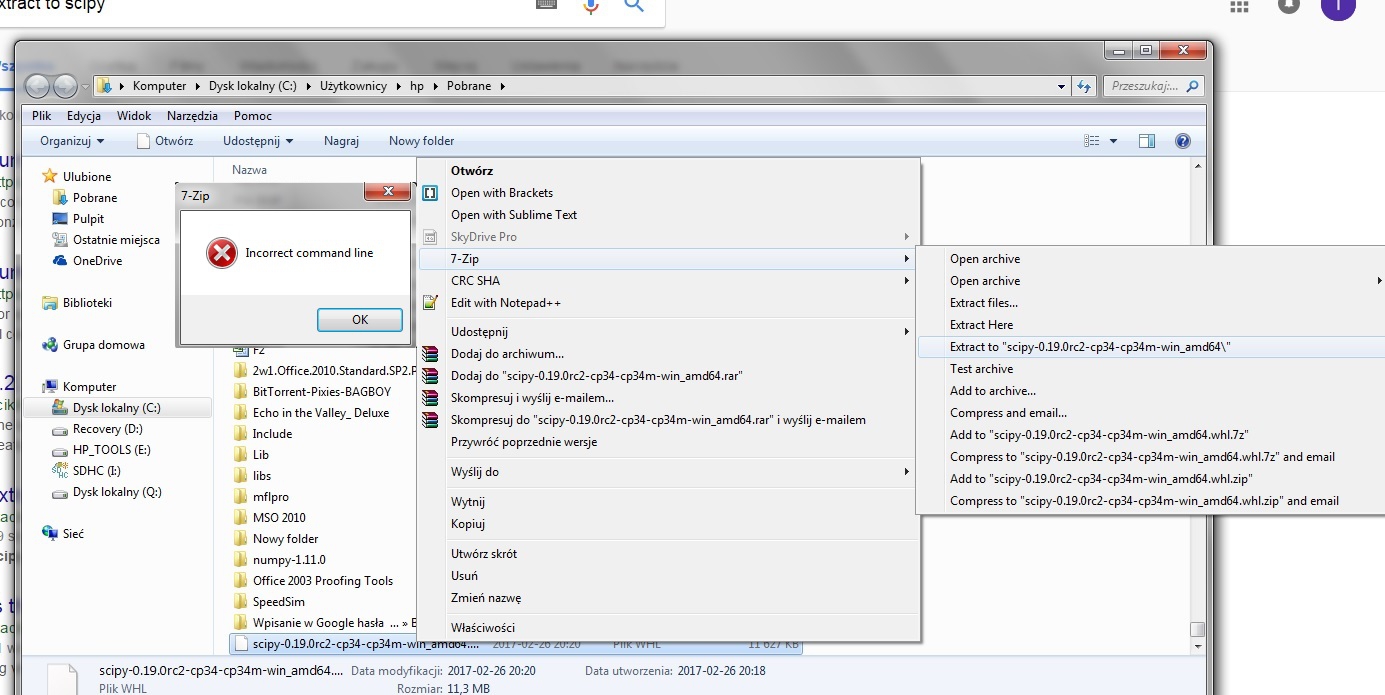
@Davidvia0: zacznijmy od tego że nie wrzucasz kodu na pastebina
jak wrzucisz co konkretnie się dzieje to może ktoś pomyśli
@IamHater: no wali sie, wyciaga reke z mlotkiem i sie wali po sobie