Darmowy ebook na temat zarobkow w sektorze Big Data na rynku amerykanskim.
2014 Data Science Salary Survey
Tools, Trends, What Pays (and What Doesn't) for Data Professionals
[epub,
2014 Data Science Salary Survey
Tools, Trends, What Pays (and What Doesn't) for Data Professionals
[epub,
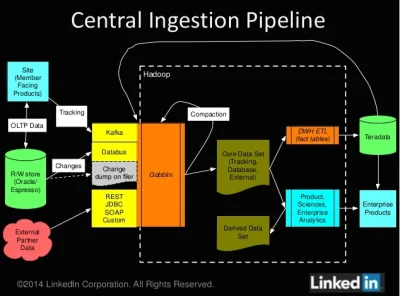



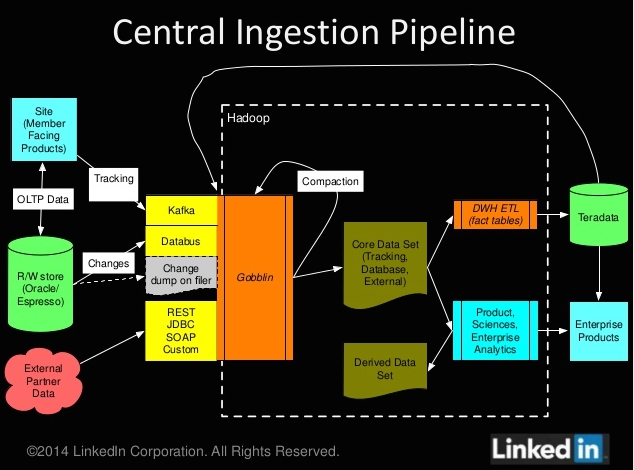{kind=link}
{kind=link}
{kind=link}
A trio of MIT researchers has developed a machine learning model that might help humans make better sense of big data by helping us make better sense of the patterns it discovers. Its creators call it the Bayesian Case Model, but a simpler description might be the example-creator.
https://gigaom.com/2014/12/08/researchers-build-pattern-recognition-model-that-acts-like-a-human/
#