Wszystko
Najnowsze
Archiwum

@blacktyg3r: to nie to ale na prowadziłeś mnie jakoś pokrętnie na rozwiążanie. .loc zwraca ALBO raw value albo pd.series. Do mojej funkcji poprawnie nadaje się metoda .at z takim samym argumentem jak loc, która gwarantuje zwrócenie floata i nigdy pd.series
Dziękuję
Dziękuję
@blacktyg3r: zaraz pewnie rzucisz słuszny komentarz że nie powinienem korzystać z pandas do takich rzeczy zwłaszcza jeśli korzystam z typów
dopiero bawię się z tym jak ma każda baza danych wyglądać więc łatwiej żonglować dfami. potem to przepiszę do sql jakiegoś gdzie bazy danych będą jasno opisane i miały określone poprawne typy.
dopiero bawię się z tym jak ma każda baza danych wyglądać więc łatwiej żonglować dfami. potem to przepiszę do sql jakiegoś gdzie bazy danych będą jasno opisane i miały określone poprawne typy.

https://www.youtube.com/watch?v=EmALxO7V7y0&list=PLbmr31Ozd_E6VGQ8hJGLqxYaA-IJDoMPq&index=2
6:30
dlaczego
6:30
dlaczego
(dataset.loc[5:10, 'x'])

Nie mam jak obejrzeć, ale zgaduje że chce kolumny od 5 do 10 (czyli 5, 6,7,8,9 z wyłączeniem 10) oraz kolumnę 'x', stąd w rezultacie 6 kolumn.
@jakismadrynickpolacinsku: Po prostu zaczyna od pozycji numer 6 do 11, taki przedział sobie wybrał. 0:5 zwróciłoby od 1 do 6.

Poszukuję kontaktu do specjalisty od PANDAS dla dziecka.
Ktoś coś? Szukam lekarza specjalistę a nie wypisywacza recept i zwolnień.
W USA wystarczy że wpisze miasto i są adresy specjalistycznych przychodni od PANDAS.. ale w PL zero nie ma nic i nikogo ;/
#pandas #choroby #lekarze #pytanie #zdrowie #medycyna #leki #leczenie
Ktoś coś? Szukam lekarza specjalistę a nie wypisywacza recept i zwolnień.
W USA wystarczy że wpisze miasto i są adresy specjalistycznych przychodni od PANDAS.. ale w PL zero nie ma nic i nikogo ;/
#pandas #choroby #lekarze #pytanie #zdrowie #medycyna #leki #leczenie

#python #programowanie #programista15k #python3 #pandas #ghostscript
Czy ktoś może mi pomóc z kodem konwersji pliku PDF na XLSX?
Męczę się już kilka godzin i nie otrzymuję oczekiwanego rezultatu czyli przeniesienia zawartości PDF 1:1 do XLSX, ciągle otrzymuję zły format
To co otrzymuje na ten czas
Moj kod
W zdjeciach na imgur przedstawil co jest zawarte w pliku PDF, a co
Czy ktoś może mi pomóc z kodem konwersji pliku PDF na XLSX?
Męczę się już kilka godzin i nie otrzymuję oczekiwanego rezultatu czyli przeniesienia zawartości PDF 1:1 do XLSX, ciągle otrzymuję zły format
To co otrzymuje na ten czas
Moj kod
W zdjeciach na imgur przedstawil co jest zawarte w pliku PDF, a co

to raczej nie jest możliwe, tzn - nie bez dużych nakładów czasowych - rozumiem że nie podoba ci się że tracisz formatowanie, kolory itd, to przeważnie nie są rzeczy które łatwo się przenosi

@harnasiek: W kodzie chyba wiele nie poprawisz, bo on parsuje tylko surowe, tekstowe dane, rozbija na linijki a potem na pojedyncze wyrażenia. Nie ma tu miejsca na formatowanie, grafikę, itp.
Są jakieś komercyjne rozwiązania, które nawet sobie radzą z tabelami, ale dość drogie:
https://docs.aspose.com/pdf/python-net/convert-pdf-to-excel/
Można też spróbować napisać jakiegoś bota, który wykorzysta taki zaawansowany konwerter online.
Są jakieś komercyjne rozwiązania, które nawet sobie radzą z tabelami, ale dość drogie:
https://docs.aspose.com/pdf/python-net/convert-pdf-to-excel/
Można też spróbować napisać jakiegoś bota, który wykorzysta taki zaawansowany konwerter online.
Muszę powiedzieć, że #chatgpt zaskakująco dobrze radzi sobie z #pandas. Właśnie sobie klepię notebooka, trochę pozapominałem Pandasa, znacząco mi przyspiesza robotę. Czasem go trzeba trochę nakierować i trzeba wiedzieć jak to w miarę dobrze zrobić, ale ogólnie na plus
#python #programowanie #datascience
#python #programowanie #datascience

@ElMatadore To fakt Mirku, znacznie przyspiesza pisanie kodu który byś w końcu napisał sam, ale trzeba by chwilę nad dokumentacją spędzić. Z innymi bibliotekami, czy nawet PySpark też daje nieźle radę.
Treść przeznaczona dla osób powyżej 18 roku życia...

Cześć, mam problem z taką oto listą:
QTY Part number Part name Zone
2 1486E87-7 Wheel - Test B13
Specimen
2 1589E56-99 Bar - Non Test C18
źródło: Zrzut ekranu 2023-09-26 210802
Pobierz
@arct2: bo tam jest bałagan, trzeba ręcznie - przeczytać drugą linijkę (pierwszą można pominąć dać nazwy ręcznie)
rozdzielić po długości czyli liczbie znaków na 4 pola
potem przeczytać następną linijkę i jeżeli pierwsze pole jest puste, to to co jest w trzecin dopisać na końcu tego co jest w 3 polu
potem przeczytać następną i dopiero jeżeli pierwsze pole nie jest puste to traktować to jak nowy rekord
rozdzielić po długości czyli liczbie znaków na 4 pola
potem przeczytać następną linijkę i jeżeli pierwsze pole jest puste, to to co jest w trzecin dopisać na końcu tego co jest w 3 polu
potem przeczytać następną i dopiero jeżeli pierwsze pole nie jest puste to traktować to jak nowy rekord

@heniek_8: Ło panie, to by trzeba ręcznie kod pisać. Mamy XXI wiek przecież, są do tego narzędzia, a nie jak neandertalczyk jakiś algorytmy samemu budować.
Wie ktoś dlaczego mimo zdefiniowania filtra nadal wyrzuca mi cały arkusz w konsoli zamiast wyfiltrowanych wartości?
import pandas as pd
df = pd.readexcel(r'C:\Users\User1\Downloads\dane.xlsx', sheetname='Tabele Przestawne 6',
import pandas as pd
df = pd.readexcel(r'C:\Users\User1\Downloads\dane.xlsx', sheetname='Tabele Przestawne 6',

mam współrzędne obiektów w data frame w krotce
potrzebuję to rozparsować na oddzielne pola x, y
zrobiłem
import pandas as pd
dane = pd.DataFrame({'coord':[(52.232,21.006)]})potrzebuję to rozparsować na oddzielne pola x, y
zrobiłem
@heniek_8: https://stackoverflow.com/questions/32468402/how-to-explode-a-list-inside-a-dataframe-cell-into-separate-rows
kilka pomysłów ¯\_(ツ)_/¯ ale pewnie explode() najlepszy będzie
kilka pomysłów ¯\_(ツ)_/¯ ale pewnie explode() najlepszy będzie

@heniek_8: jak odpowiednio zwrócisz z apply() to możesz od razu w dwie kolumny zapisać.
Zobacz tutaj w sekcji „ … jedną kolumnę podzielić na kilka”, ten blok „Szybko” ;)
https://uczymymaszyny.pl/hej-pandas-chce/
Zobacz tutaj w sekcji „ … jedną kolumnę podzielić na kilka”, ten blok „Szybko” ;)
https://uczymymaszyny.pl/hej-pandas-chce/
Mam taki problem, że próbuję sobie posegregować dane i zapisać je w jednym pliku CSV.
W skrócie:
- Robię listę wszystkich plików w zdefiniowanym folderze
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę całkowitą znajdującą się przed literą R (to identyfikator baterii)
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę stałoprzecinkową (powiedzmy, że zawsze z 1 miejscem po przecinku) -> to identyfikator napięcia
- Przeszukuję tę listę plików, aby znaleźć ostatnią liczbę całkowitą -> to
W skrócie:
- Robię listę wszystkich plików w zdefiniowanym folderze
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę całkowitą znajdującą się przed literą R (to identyfikator baterii)
- Przeszukuję tę listę plików, aby znaleźć pierwszą liczbę stałoprzecinkową (powiedzmy, że zawsze z 1 miejscem po przecinku) -> to identyfikator napięcia
- Przeszukuję tę listę plików, aby znaleźć ostatnią liczbę całkowitą -> to


mam dane godzinowe i chcę je zsumować do pełnych dni.
mam coś takiego:
mam coś takiego:
1 2020-01-02 00:00:00 -13
2 2020-01-02 01:00:00 22@maciekXDDD: nie wiem jak wyglądają twoje dane ale na logikę potrzebujesz niedzielę oznaczyć jako poniedziałek i na tym zagregować/zgrupować. W zależności jakiego dialektu sql używasz mozesz uzyc funkcji np. Datename w sql serverze które ci zwróci dzień tygodnia.
Druga opcja to zrobić temp tabele/cte z zagregowanymi danymi dla niedziel.
I nastepnie polaczyc ja z twoja tabela glowna w ten sposob ze laczysz po tabelaglowna.dzien - 1 = tabelazniedziela.dzien (czyli dla
Druga opcja to zrobić temp tabele/cte z zagregowanymi danymi dla niedziel.
I nastepnie polaczyc ja z twoja tabela glowna w ten sposob ze laczysz po tabelaglowna.dzien - 1 = tabelazniedziela.dzien (czyli dla
natomiast potrzebuje wartości z niedzieli dodać do wartości poniedziałkowej.
@maciekXDDD: Mając już dane w pandas napisałbym sobie funkcję sprawdzającą czy dany dzień jest niedzielą i zamienił ten dzień na poniedziałek, co z resztą powyżej już wskazano.
from datetime import datetime as dtfrom datetime import timedelta
@przecietnyczlowiek: no w głównej wersji być może. Ale stara dalej może mieć taką funkcjonalność ¯\_(ツ)_/¯
@przecietnyczlowiek: tak
#datascience
Hej Mirki, tak sobie dlubie proste ETL w #pandas #numpy #python i glowkuje jak tu skrocic czas ladowania trzech duzych (1GB kazdy 900k x 200) CSV. Jedyne co przychodzi mi jeszcze do glowy to dorzucenie multiprocesingu bo duzo sie dzieje, z %pruna widze ze w tej chwili CPU jest waskim gardlem. Probowalem w prymitywny sposob zaladowac to w multi rozrzucajac kazdy plik na osobny
Hej Mirki, tak sobie dlubie proste ETL w #pandas #numpy #python i glowkuje jak tu skrocic czas ladowania trzech duzych (1GB kazdy 900k x 200) CSV. Jedyne co przychodzi mi jeszcze do glowy to dorzucenie multiprocesingu bo duzo sie dzieje, z %pruna widze ze w tej chwili CPU jest waskim gardlem. Probowalem w prymitywny sposob zaladowac to w multi rozrzucajac kazdy plik na osobny
@hoszak: zobacz na rozwiązania w tym wątku: https://stackoverflow.com/questions/6475328/how-can-i-read-large-text-files-line-by-line-without-loading-it-into-memory

@hoszak: Spróbuj Polars, sporo szybsza biblioteka, wrapper Rust-a.
https://www.pola.rs/
Ewentualnie Pyarrow - https://arrow.apache.org/docs/python/generated/pyarrow.csv.read_csv.html
https://www.pola.rs/
Ewentualnie Pyarrow - https://arrow.apache.org/docs/python/generated/pyarrow.csv.read_csv.html

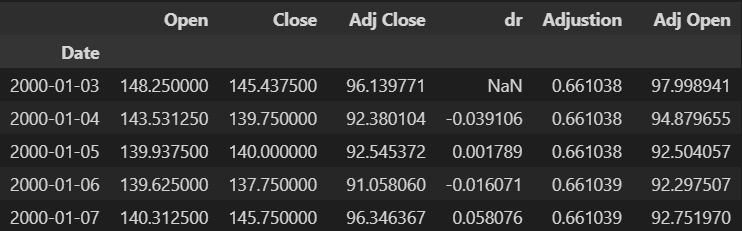
mam plik csv, taki jak na screenie. Mój cel to utworzenie nowej kolumny, której wartości będą wynikiem formuły: (Adjusted Open - Adjusted Close z poprzedniego wiersza)/Adjusted Close z poprzedniego wiersza. W jaki sposób najłatwiej to osiągnąć? Najlepiej nie zmieniając indeksu na numeryczny. Muszę pętlą czy da się jakoś inaczej? #python #pandas
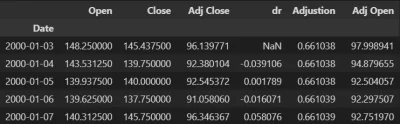
źródło: comment_16574738721qrCQevM6J8oAYmf75VySb.jpg
Pobierzmam dwa pliki csv, oba mają takie same kolumny. Powiedzmy, że jednen z nich składa się z wierszy a i b a drugi z wierszy b i c. Jak mogę połączyć te dwa pliki tak, żeby nie duplikowało mi wiersza b, który w tych dwóch plikach jest taki sam? Kombinowałem różnie z pd.concat, ale cały czas te powtarzające się wiersze duplikują się. #python #pandas
źródło: comment_1656869901EruoGvPBc9yLUjC4ZbL7l6.jpg
Pobierz@Oake może po prostu z drop_duplicates() na koniec?
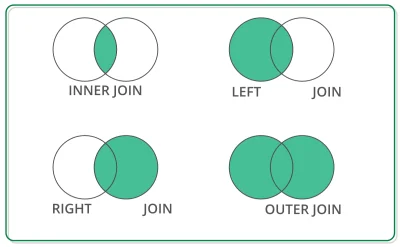
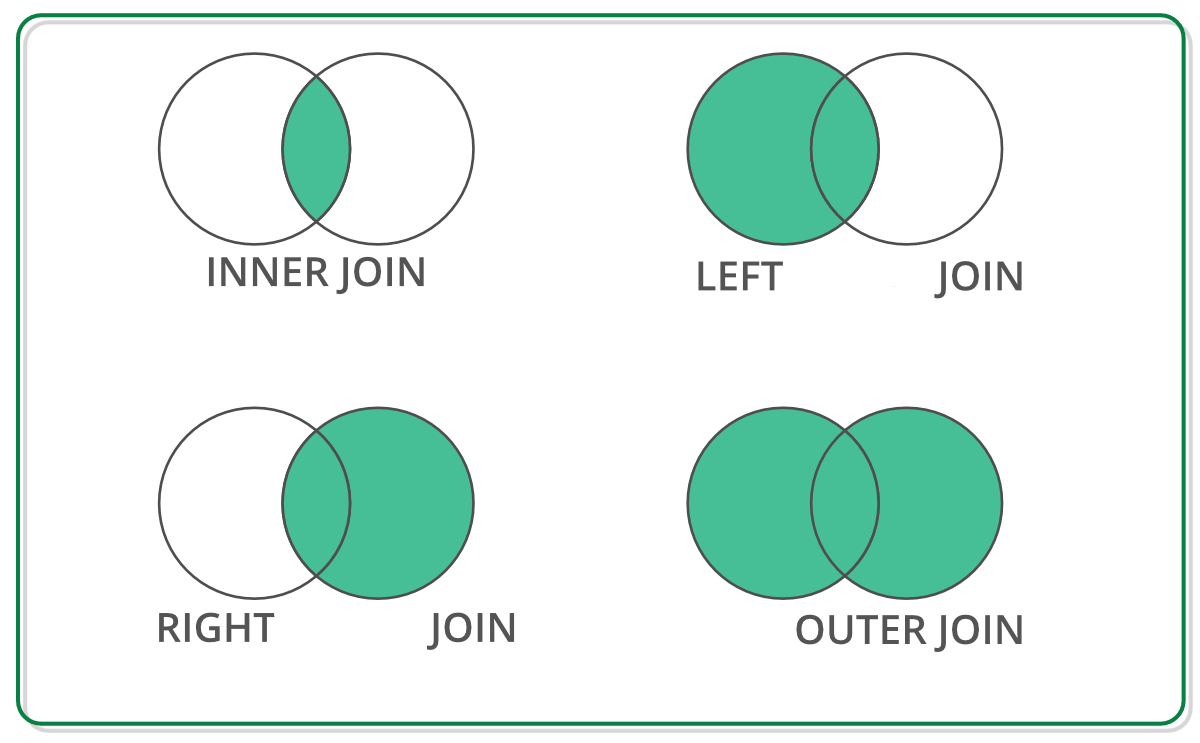
poleca ktoś jakiś kurs/ćwiczenia gdzie można się podszkolić w operacjach na tabelach typu dataframe? chodzi mi o nabranie wprawy w joinach, groupby i innych transformacjach. Fajnie by bylo poznać jakieś zaawansowane techniki itp itd.
#python #pandas #numpy #dataengineering
#python #pandas #numpy #dataengineering

Próbuję otworzyć plik w pandas:
import pandas as pd
df = pd.readcsv('D:\podglad\podglad.xlsx', encoding='Windows-1250', onbad
import pandas as pd
df = pd.readcsv('D:\podglad\podglad.xlsx', encoding='Windows-1250', onbad

@scorpio18k: spróbuj utf-16

Potrzebuję w pliku excel zhashować kolumny password i pesel. W pycharm taki kod wpisuję i po uruchomieniu wyrzuca jakieś errory i nic. Plik users.csv rozumiem, że ma być w tym folderze co projekt pycharmowy z plikiem python?
Help pls
Nie zajmuję się programowaniem więc proszę mieć to na uwadze.
import pandas as pd
import hashlib
Help pls
Nie zajmuję się programowaniem więc proszę mieć to na uwadze.
import pandas as pd
import hashlib


#pandas Jak unikacie wielokrotnego uzywanie .loc
np.
tabela.loc[warunek, kolumna]=tabela.loc[warunek, kolumna]+tabela.loc[warunek, kolumna_inna]
Jestem pewien, ze kiedys widzialem jakies sprytne obejscie, ale nie pamietam jakie ;)
np.
tabela.loc[warunek, kolumna]=tabela.loc[warunek, kolumna]+tabela.loc[warunek, kolumna_inna]
Jestem pewien, ze kiedys widzialem jakies sprytne obejscie, ale nie pamietam jakie ;)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
#python
Może po prostu nie zapisuj tego w formacie daty tylko jako text
Ręcznie zrobiłbym to tak: dla listopada i grudnia dodaję rok i od numeru miesiące odejmuję 10. Dla okresu od stycznia do października do numeru miesiąca dodaję 2. Tutaj jest opis ze strony IMGW:
Dane hydrologiczne są opracowywane i udostępniane w układzie lat hydrologicznych.Rok hydrologiczny zaczyna się 1 listopada poprzedniego roku kalendarzowego, a kończy 31 października, np. rok hydrologiczny 2016