
Cześć, tak się zastanawiam który przykład sprawdzania co zwróci funkcja jest bardziej poprawny.
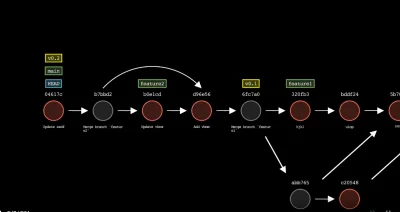
Na zdjęciu są pokazane dwa przykłady użycia tej samej funkcji ale według trochę innej procedury.
Sposób 1 górny:
Funkcja startprogram() jest odpalana, potem w środku od razu funkcja connect() w której dzieje się jakiś kod, jeśli wszystko się wykona pomyślnie to do zmiennej connectionstatus jest przypisana logiczna jedynka. Program wraca do funkcji bazowej i tam sprawdza status
Na zdjęciu są pokazane dwa przykłady użycia tej samej funkcji ale według trochę innej procedury.
Sposób 1 górny:
Funkcja startprogram() jest odpalana, potem w środku od razu funkcja connect() w której dzieje się jakiś kod, jeśli wszystko się wykona pomyślnie to do zmiennej connectionstatus jest przypisana logiczna jedynka. Program wraca do funkcji bazowej i tam sprawdza status


@imthehighestintheroom: Żodyn z powyższych, użyj ContextManagera.
@ZabiliMiZolwia: @zarev: thx, nie słyszałem o tym jeszcze. Sprawdzę




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
mam coś takiego:
1 2020-01-02 00:00:00 -132 2020-01-02 01:00:00 22
3 2020-01-02 02:00:00 65
4 2020-01-02 03:00:00 -17
5 2020-01-02 04:00:00 -4
6 2020-01-02 05:00:00 5
i chcę uzyskać nowy dataframe, który będzie wyglądał tak:
1 2020-01-02 00:00:00 -58 <--suma wartości godzinowych z tego dniadanych jest dużo, na kilkanaście lat. jakieś pomysły jak mogę to zrobić?
#python #sql #pandas
Druga opcja to zrobić temp tabele/cte z zagregowanymi danymi dla niedziel.
I nastepnie polaczyc ja z twoja tabela glowna w ten sposob ze laczysz po tabelaglowna.dzien - 1 = tabelazniedziela.dzien (czyli dla kazdego
@maciekXDDD: Mając już dane w pandas napisałbym sobie funkcję sprawdzającą czy dany dzień jest niedzielą i zamienił ten dzień na poniedziałek, co z resztą powyżej już wskazano.
from datetime import datetime as dtfrom datetime import timedelta as tddef is_sunday(date):if date.isoweekday() == 7:return date+td(days=1)else:return datei dalej już w dataframe:
df['nowadata'] = df.loc[:,'nazwakolumnyzdata'].map(is_sunday)