
Dzień po dniu, wciąż się dzieje życia cud... ale tak mijają te dni bezbarwnie, że postanowiliśmy zrobić mały #konkurs! Szczęśliwie okoliczności sprzyjają, ponieważ dzisiaj Dzień Dziecka, a wiemy, że w każdej Mirabelce i w każdym Mireczku znajdzie się odrobina podrostka ( ͡° ͜ʖ ͡°)
No to jak, pytanko? Brzmi ono następująco: Jaka jest najprzydatniejsza rzecz na juniora w IT do 100 złotych i dlaczego?
Wybierzemy pięć osób,
No to jak, pytanko? Brzmi ono następująco: Jaka jest najprzydatniejsza rzecz na juniora w IT do 100 złotych i dlaczego?
Wybierzemy pięć osób,



Jaka jest najprzydatniejsza rzecz na juniora w IT do 100 złotych i dlaczego?
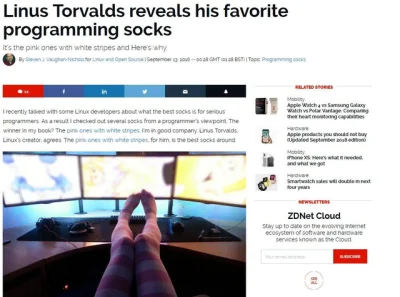
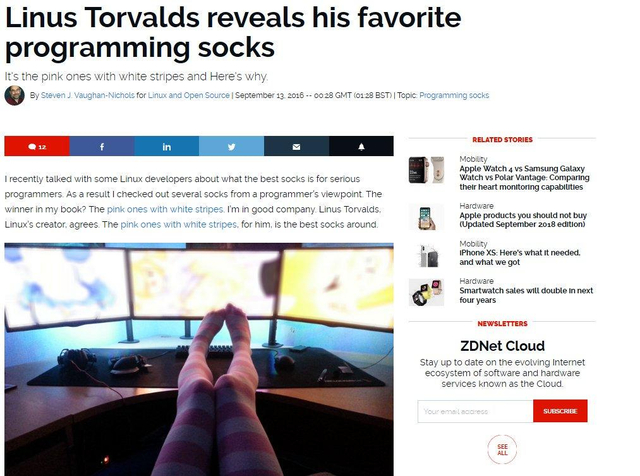
@JustJoinIT: zakolanówki do programowania. A dlaczego, to nie wiem, może żeby było fajnie ciepło czy coś ( ͡° ͜ʖ ͡°)




























{kind=link}
{kind=link}
{kind=link}
(f'\n\n\n ---------------------------{test}------------------------------- \n\n\n')
Gdzie test to jakiś losowy tekst, każdy znak możliwy. Znaków '-' jest po 26 na stronę. Ułożyłem coś takiego:
re.split('^\s-{26}.+-{26}\s$', data_one)
Ale nie działa :/ Jaki regex by tutaj się lepiej sprawdził?
#python
@Bocislaw: ( ͡° ͜ʖ ͡°)
Wyszukałem odpowiedź na stackoverflow:
https://stackoverflow.com/a/54373630/175911
Zamiast
val==seprobiszsep_re.match(val).Potrzebujesz tego tekstu z nawiasów klamrowych?
sep_re = r'-+\{\w+\}-+'