
Mirasy, Wielka Czwórka szuka, ale iłaj[EY] GDS polecam motzno, bo spółka nie jest audytowa, tylko techniczna. Skupia programersów, testerów, consulting, security, usługi techniczne, finansowe i inne dla spółek audytowych właśnie.
( ͡°( ͡° ͜ʖ( ͡° ͜ʖ ͡°)ʖ ͡°) ͡°)
Wiadomo, że spółka wchodzi w skład #big4 i jest to #korposwiat ale zdecydowanie na co dzień atmosfera, specyfika projektów godne polecenia, no i dobre hajsy
( ͡°( ͡° ͜ʖ( ͡° ͜ʖ ͡°)ʖ ͡°) ͡°)
Wiadomo, że spółka wchodzi w skład #big4 i jest to #korposwiat ale zdecydowanie na co dzień atmosfera, specyfika projektów godne polecenia, no i dobre hajsy
![D3lt4 - Mirasy, Wielka Czwórka szuka, ale iłaj[EY] GDS polecam motzno, bo spółka nie ...](https://wykop.pl/cdn/c3201142/comment_ZxsevX1rm06UfbmXMn4Rw9qWWypUsi5k,w400.jpg)



















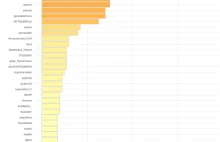









{kind=link}
{kind=link}
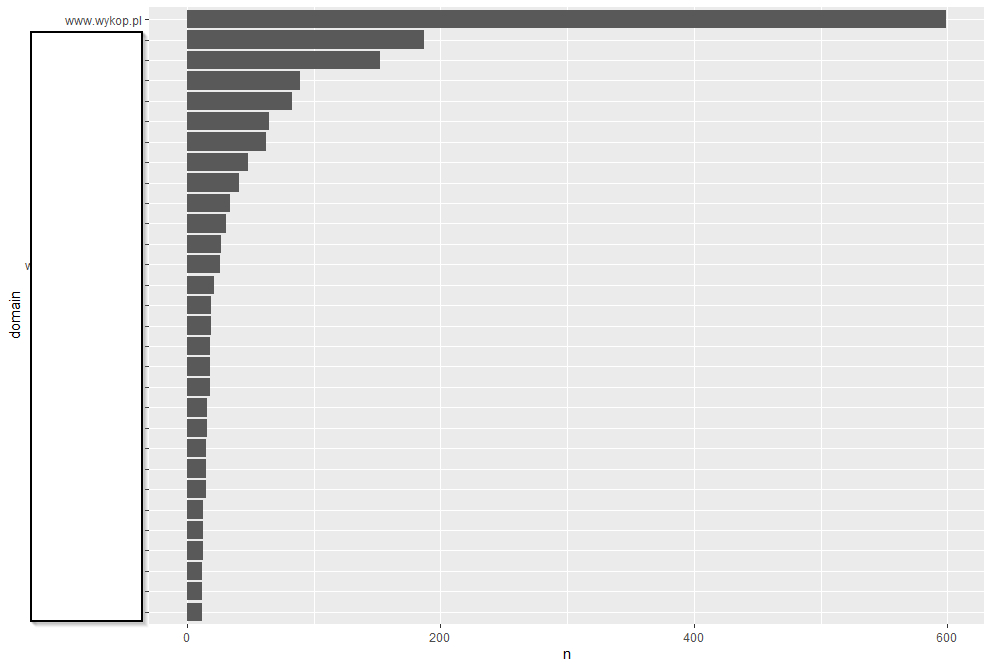{kind=link}
{kind=link}
{kind=link}
{kind=link}
@AnonimoweMirkoWyznania: wiesz dobrze tak jak ja ze ta dziedzina to statystyka(+trochę matmy ogólnie), trochę programowania i teorii. I dla większości jest to nie do przeskoczenia i ich projekty w domu to wrzutka wszystkich danych(bez obróki) w sieci NN i to tyle.