Wszystko
Najnowsze
Archiwum
QRD SPARK N5 Recenzja wszechstronnego bezprzewodowego kontrolera z efektem Halla

Jeśli szukasz kontrolera do gier z dodatkowymi łopatkami z tyłu i fajnymi przyciskami ten może być dla ciebie!
z- 0
- #
- #
- #
- #
- #
- #


Humble Bundle z książkami wydawnictwa Apress. Głównie o technologiach związanych z .NET, ML.NET, Cpłotek, TypeScript, Azure, Github.
26 książek za £14!
Pełna lista:
26 książek za £14!
Pełna lista:
Practical
@Hektorrr: Dodam, że zestaw tych wszystkich książek normalnie wyceniony jest na £1,119.85.
Tak więc £14 funtów to prawie jak za darmo a jak wiadomo za darmo to uczciwa cena.
Tak więc £14 funtów to prawie jak za darmo a jak wiadomo za darmo to uczciwa cena.



Nie używaj Sparka do Machine Learning
https://bulldogjob.pl/readme/nie-uzywaj-sparka-do-uczenia-maszynowego
#machinelearning #programowanie #naukaprogramowania #spark
https://bulldogjob.pl/readme/nie-uzywaj-sparka-do-uczenia-maszynowego
#machinelearning #programowanie #naukaprogramowania #spark

Dobry clickbait, artykuł powinien nazywać się nie uzywaj PySparka ( ͡° ͜ʖ ͡°)
@Bulldogjob: ehhh, dałem się złapać na clickbajtowy tytuł. Argumenty przeciw sparkowi są prawdziwe ale w praktyce należy je pominąć z rozważań. Zwłaszcza argument o syntax pysparka vs pandasa

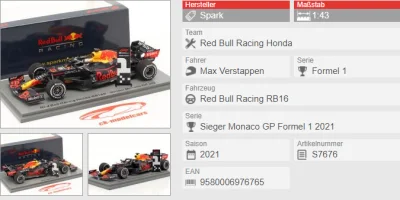
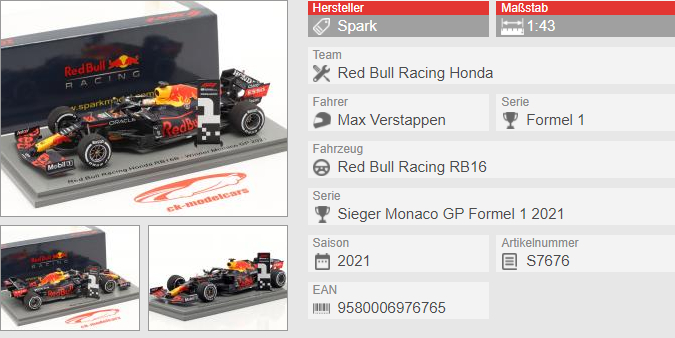
Szukam prezentu dla fana #f1 i pomyślałem o modelu bolidu Maxa Verstappena. Czy znacie może producenta modeli #spark ? A może jakaś inna firma lepsza? #modelarstwo
#f1
#f1
źródło: comment_1639218715EjL0LWiUlgEfspjuUoFUfb.jpg
Pobierz
@mlodymedyk: W skali 1:43 Spark oraz Minichamps oferują bardzo podobną jakość, różnią się mankamentami. Moim jednak skromnym zdaniem Minichamps bardziej zakorzeniło się w świadomości kolekcjonerów, mają ogromną kolekcję gdzie występują kierowcy zarówno z wyścigów, treningów jak i poszczególnych wydarzeń. Natomiast jeżeli kolega nie zbiera modeli to pewnie nie robi mu to większej różnicy, a nawet jak zbiera to raczej firmą Spark nie pogardzi. Modele jak na swoją skalę są bardzo
@mlodymedyk: Jasne. Gdybyś jeszcze się zastanawiał czy Spark, Minichamps czy nawet ewentualnie Bburago z innej półki cenowej to na yt oraz forach tematycznych jest sporo recenzji czy porównań.

używał ktoś aplikacji #spark do kupowania biletów na a4?
wszystko działa nie ma przypału? bo tam w porównaniu do etolla po prostu kupuje się bilet bramka A -> bramka B i tyle?
#polskiedrogi #a4 #etoll
wszystko działa nie ma przypału? bo tam w porównaniu do etolla po prostu kupuje się bilet bramka A -> bramka B i tyle?
#polskiedrogi #a4 #etoll


Cześć, dostałem mały projekt w pracy w pysparku. Mała transformacja danych i wrzucenie wyników do nowej tabeli. W punktach opiszę co trzeba zrobić:
1. 4 uniony
2. Pobrać tabelę z mappingiem
3. Zrobić joina (te 4 uniony i mapping)
5. Przerobić 2 kolumny na podstawie wartości, i dodać dwie puste kolumny
4. Wykonać prostą agregacje danych -> groupby po 5 kolumnach.
1. 4 uniony
2. Pobrać tabelę z mappingiem
3. Zrobić joina (te 4 uniony i mapping)
5. Przerobić 2 kolumny na podstawie wartości, i dodać dwie puste kolumny
4. Wykonać prostą agregacje danych -> groupby po 5 kolumnach.
@PiotrokeJ: 7k rekordów w sparku? Jebnij im to w sql, pandas albo excelu.
Apache Ambari
@PiotrokeJ: To już jest kwestia samego zarządzania (wybacz ale nie mam pojęcia jak to inaczej ubrać w słowa) translacją samego SQL na MapReduce na Hadoopie.
W tym przypadku Hadoop trochę inaczej ogarnia takie zapytanie niż spark. Dlatego jak odpalasz coś bezpośrednio na hadoopie to możesz dostać wyniki (błędne lub dobre), a w sparku już
Hey #scala
Macie może jakieś dobre tutoriale, dokumentację odnośnie implementacji ZIO ze #spark ?
Na głównym repo ziverge od zio-spark nie mogę dużo znaleźć, a znowu film Pana Leo Benkela bardzo mnie zaciekawił i chciałbym trochę bardziej zgłębić temat:
#apachespark #databricks
Macie może jakieś dobre tutoriale, dokumentację odnośnie implementacji ZIO ze #spark ?
Na głównym repo ziverge od zio-spark nie mogę dużo znaleźć, a znowu film Pana Leo Benkela bardzo mnie zaciekawił i chciałbym trochę bardziej zgłębić temat:
#apachespark #databricks
@gabonczyk: Jak przepisze mojego JOBa, o którym wspomniałem to podziele się tutaj statystykami. :D
Chyba, ze mnie uprzedzisz i uda Ci się zrobić dobry benchmark przede mną.
To wołąj wtedy mirku.
Chyba, ze mnie uprzedzisz i uda Ci się zrobić dobry benchmark przede mną.
To wołąj wtedy mirku.
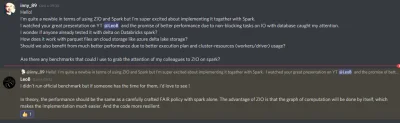
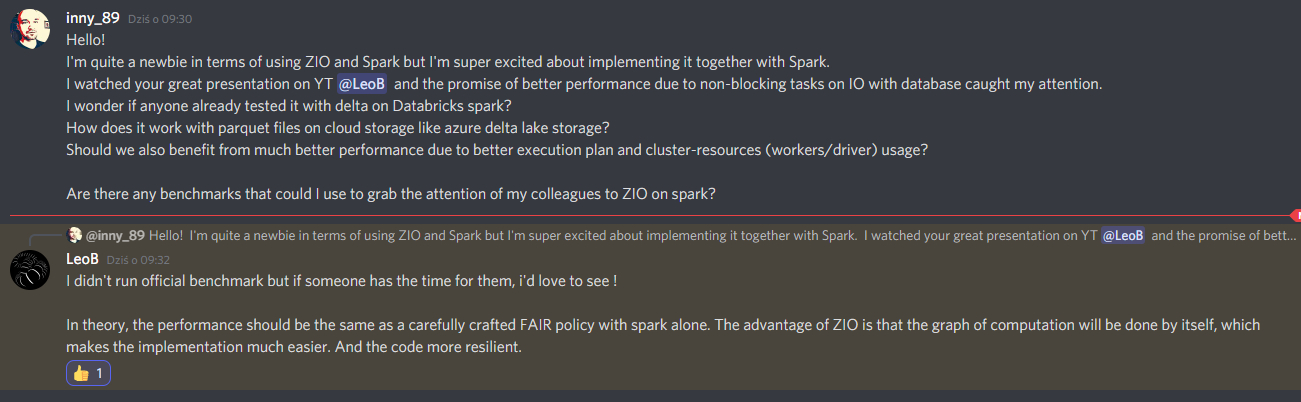
@gabonczyk: Jeszcze CIę tutaj zawołam bo muszę przyznać, że szybko się nie zabiore za ogarnięcie tego przykłądowego pipeline (a przynajmniej nie przez następne 2 tygodnie) ale zagadałem do tego Leo na oficjalnym doscordzie ZIO.
Poniżej jego odpowiedź odnośnie performencu na IO więc trochę może dać to pogląd dlaczego ZIO na SParku może mieć sens.
Aczkolwiek martwi mnie, ze on takich benchmarków wcześniej nie zrobił xD
Poniżej jego odpowiedź odnośnie performencu na IO więc trochę może dać to pogląd dlaczego ZIO na SParku może mieć sens.
Aczkolwiek martwi mnie, ze on takich benchmarków wcześniej nie zrobił xD
źródło: comment_1636121185N4s0Pmud1Qz7b7i3UG7SnK.jpg
PobierzApache Spark & Docker – Local Cluster Mode – Data Science In Action

Apache Spark jest to platforma umożliwiająca przetwarzanie ogromnych zbiorów danych w środowisku rozproszonym. Okazuje się jednak, że równie łatwo możemy korzystać ze Sparka na lokalnym komputerze. Oprócz trybu lokalnego możemy również zbudować własny klaster przy pomocy kontenerów Docker'a.
z- 0
- #
- #
- #
Słuchajcie mam zagadkę. Z zakresu troche fanaberii i sci-fi.
Raczej mniej istotne tło problemu:
Tworzę sobie Wheela w #pythonie i do pełnego wykorzystania tej libki, którą zbuduje jest potrzebna inna libka udostępniana jako plik .JAR.
Lokalnie jak sobie z tym pracuje i odpalam kod w ramach mojego develpmentu na sparku to mam zwyczajnie załączony ten JAR w odpowiedniej lokalizacji i wskazuje go podczas budowania SparkSession. Tak jak na uproszczonym przykłądzie poniżej:
Raczej mniej istotne tło problemu:
Tworzę sobie Wheela w #pythonie i do pełnego wykorzystania tej libki, którą zbuduje jest potrzebna inna libka udostępniana jako plik .JAR.
Lokalnie jak sobie z tym pracuje i odpalam kod w ramach mojego develpmentu na sparku to mam zwyczajnie załączony ten JAR w odpowiedniej lokalizacji i wskazuje go podczas budowania SparkSession. Tak jak na uproszczonym przykłądzie poniżej:

@inny_89 init scriptem
@Kura_Wasylisa zapomniałem dać znać, że
@ProfesorBigos naprowadził mnie na rozwiązanie. Wystarczy dołączyć zależności do wheela, razem zbudować i je później wykorzystać. Dziękuję Panie Profesorze!
@ProfesorBigos naprowadził mnie na rozwiązanie. Wystarczy dołączyć zależności do wheela, razem zbudować i je później wykorzystać. Dziękuję Panie Profesorze!
Kurcze mam dane 145 kolumn, 100k wierszy. Wrzucam do glue/sparka i mam kilkadziesiat krokow. W wiekszosci cos w stylu a*b itd (testuje sobie).
Większość kodu to funkcje np jak poniższa:
Większość kodu to funkcje np jak poniższa:
def handle(gc: GlueContext, df: DynamicFrame) -> DynamicFrame:
return ApplyMapping.apply(frame=df, mappings=t)def t(rec: DynamicRecord) -> DynamicRecord:@inny_89: I chyba juz znalazłem winowajce.
Mam jedna regułe która ma policzyc srednia dla calego zbioru...
Wszystkie joby wcześniejsze są ładnie rozrzucone na executory.
Wszystkie joby po średniej - już idą na jednym executorze.
Dziwne, bo robie sobie kopie ramki, obliczam co mi trzeba i potem dodaje tylko kolumne do oryginalnej ramki. Ale zaraz sie upewnie wywalajac ten krok czy wszystko bedzie ladnie rownolegle dzialac.
Mam jedna regułe która ma policzyc srednia dla calego zbioru...
Wszystkie joby wcześniejsze są ładnie rozrzucone na executory.
Wszystkie joby po średniej - już idą na jednym executorze.
Dziwne, bo robie sobie kopie ramki, obliczam co mi trzeba i potem dodaje tylko kolumne do oryginalnej ramki. Ale zaraz sie upewnie wywalajac ten krok czy wszystko bedzie ladnie rownolegle dzialac.
@inny_89: Ok, to sobie rozpoznam - wygląda to na dosyć dużę czasy GC, jakby to zmniejszyć to też dobry kwałek ugram.
PS. Wielkie dzięki - wskazówki z dag (AWS ma to pod nazwą to Spark UI) były super pomocne. Tak to bym pewnie w ciemno błądził co jest nie tak. A tak w dzień rozpykane i teraz 100k wierszy robie w 8 min zamiast w 1h.
Problematyczne przekształcenia (średnia i
PS. Wielkie dzięki - wskazówki z dag (AWS ma to pod nazwą to Spark UI) były super pomocne. Tak to bym pewnie w ciemno błądził co jest nie tak. A tak w dzień rozpykane i teraz 100k wierszy robie w 8 min zamiast w 1h.
Problematyczne przekształcenia (średnia i



Potrzebuję zrobić #hurtowniedanych w #sqlserver ale jako narzędzie do #etl służy mi #spark, a konkretnie #pyspark
Macie może jakieś dobre materiały albo przykładowe kody, żeby podejrzeć jakieś dobre praktyki?
Jak ogarnąć slow changing dimension? Metadane itp.?
Macie może jakieś dobre materiały albo przykładowe kody, żeby podejrzeć jakieś dobre praktyki?
Jak ogarnąć slow changing dimension? Metadane itp.?
@inny_89: Z doświadczenia to całe zasilanie powinno się odbywać w dwóch krokach Source - Extract, Extract - Stage. Oczywiście mówię o hurtowni zasilanej raz na dobę nocną porą.
1. Source - Extract - truncate docelowych tabel i zasilenie ze źródła. Tak jest najszybciej. Nawet jak masz tabele do 100 mln rekordów. Z produkcji zasilamy dane tak szybko jak to jest możliwe.
2. Extract - Stage - zasilenie przyrostowe. I tu już można
1. Source - Extract - truncate docelowych tabel i zasilenie ze źródła. Tak jest najszybciej. Nawet jak masz tabele do 100 mln rekordów. Z produkcji zasilamy dane tak szybko jak to jest możliwe.
2. Extract - Stage - zasilenie przyrostowe. I tu już można
@inny_89: https://stackoverflow.com/questions/38487667/overwrite-specific-partitions-in-spark-dataframe-write-method
Ustawia się to jedną linijką w configu:
Ustawia się to jedną linijką w configu:
spark.conf.set("spark.sql.sources.partitionOverwriteMode","dynamic")Wybacz też wysoki poziom abstrakcji przy opisywaniu

{kind=link}
{kind=link}
#spark #scala #programowanie
Nie działa mi 1 przykład z dokumentacji sparka: https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
val df = spark
.readStream
Nie działa mi 1 przykład z dokumentacji sparka: https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
val df = spark
.readStream
Tak to jest się uczyć z książki w której przykłady nie działają, bo są bez konfiguracji.
Próbuję zapodać przykładowy structured streaming sparkiem do kafki i same problemy. Większość już rozwiązałem, teraz mam na drodze ten:
org.apache.spark.AnalysisException: value attribute unsupported type bigint. value must be a(n) string or binary;
at org.apche.spark.sql.kafka010.KafkaWriter ...
kod:
Próbuję zapodać przykładowy structured streaming sparkiem do kafki i same problemy. Większość już rozwiązałem, teraz mam na drodze ten:
org.apache.spark.AnalysisException: value attribute unsupported type bigint. value must be a(n) string or binary;
at org.apche.spark.sql.kafka010.KafkaWriter ...
kod:
Po odpaleniu joba, po jakims czasie dostaje bład jak niżej...
I nie wyglada to na coś złego, normalnie wszystko się przetwarza (screen)
jakieś pomysły co zrobiłem nie tak?
An error occurred while calling o5466.resolveChoice. Job aborted due to stage failure: Task 6 in stage 53.0 failed 4 times, most recent failure: Lost task 6.3 in stage 53.0źródło: comment_1664571841Ud2Sv5K0T42G0UlrKLuX0w.jpg
Pobierz