Zainteresowanych #mirkopromocje zainteresować może fakt, ze w najbliższych dniach księgarnia Helion obchodzić będzie okrągłe 32 urodziny. Świętowanie zaczyna od rozdawnictwa - w zamian za zapisanie się na newslettera księgarni, możemy otrzymać e-booka bądź jeden z 2 kursów video:
- Witold Wrotek Elektronika. Leksykon kieszonkowy e-book
- Konrad Jagaciak Python na start. Twórz gry w PyGame! kurs video
- Mateusz Staniak Machine learning i język R. Pierwsze kroki z pakietem mlr kurs video
#
- Witold Wrotek Elektronika. Leksykon kieszonkowy e-book
- Konrad Jagaciak Python na start. Twórz gry w PyGame! kurs video
- Mateusz Staniak Machine learning i język R. Pierwsze kroki z pakietem mlr kurs video
#






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#jezykr #programowanie #kiciochpyta
Demo:
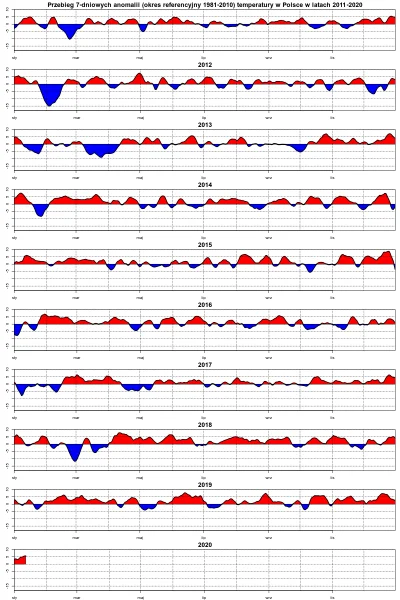
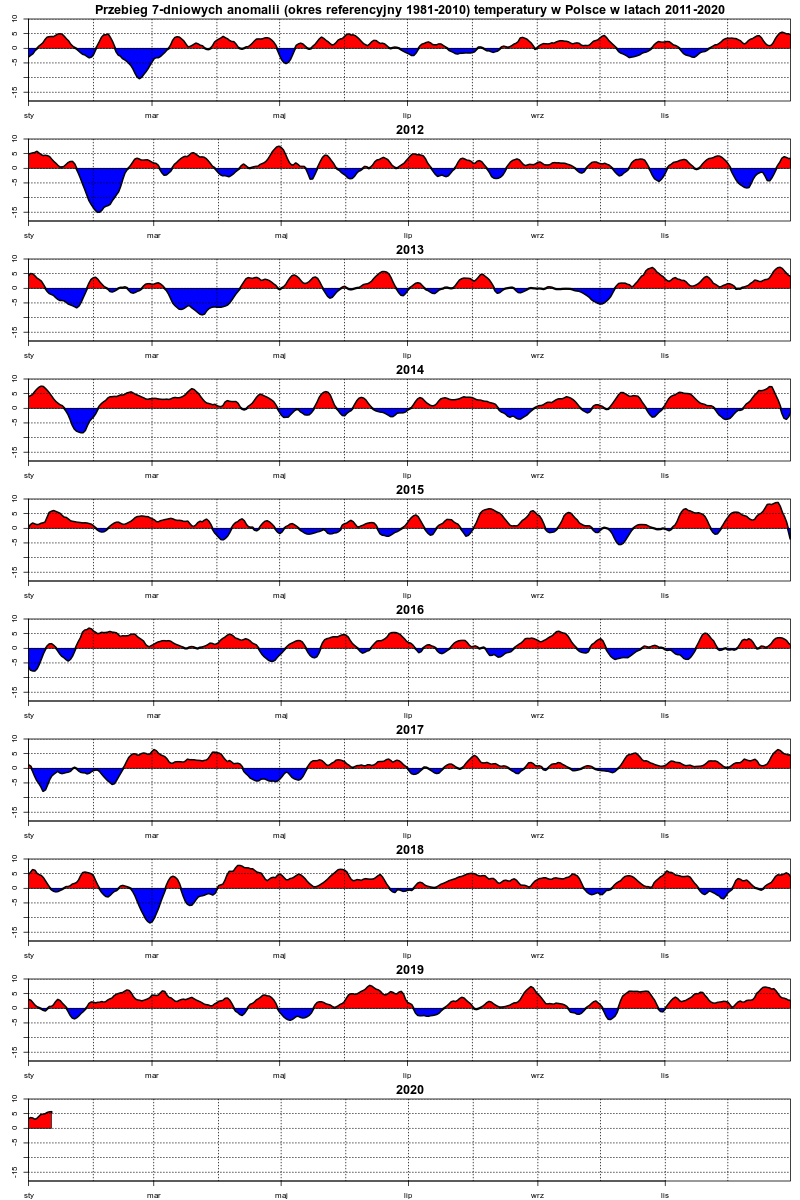
źródło: R1
PobierzJak widac po moich danych to one wygladają mniej więcej tak
[1] słowo1 numer1
[2]
library(dplyr)
demoFreq = data.frame ( word = c('oil','said','prices'), freq=c(85, 73, 48))
row.names(demoFreq) = demoFreq$word
head(demoFreq)