Szukam obecnie materiałów do nauki modułów ML w Pythonie (sklearn, Tensorflow). Aspekt teorytyczny jest mile widziany, ale nie jest priorytetem, ponieważ mam od tego przedmiot na uczelni. Zależy mi na tym, aby było dużo praktyki i weryfikacji wiedzy - zadań lub projektów. Zna ktoś może odpowiednie książki/kursy/serie na YT? Osobiście znalazłem ze dwie/trzy sensownie wyglądające serie na youtube oraz dwie książki na PWN Uczenie maszynowe z użyciem Scikit-Learn i TensorFlow oraz Python
Wszystko
Najnowsze
Archiwum
pustelnikk
pustelnikk
Dzięki!
pustelnikk
@szczepan-szczypawa: Dzięki!

Zdjęcia satelitarne i Machine Learning, czyli jak stworzyć apkę dla rolników
Poznaj rolnictwo XXI wieku, czyli drony, satelity, ciągniki z autopilotem i dedykowane aplikacje
https://bulldogjob.pl/readme/zdjecia-satelitarne-i-machine-learning-czyli-jak-stworzyc-apke-dla-rolnikow
#machinelearning #programowanie #naukaprogramowania #rolnictwo #technologia #bulldogjob
Poznaj rolnictwo XXI wieku, czyli drony, satelity, ciągniki z autopilotem i dedykowane aplikacje
https://bulldogjob.pl/readme/zdjecia-satelitarne-i-machine-learning-czyli-jak-stworzyc-apke-dla-rolnikow
#machinelearning #programowanie #naukaprogramowania #rolnictwo #technologia #bulldogjob

źródło: comment_1650449986bKJx54EsD4Sh82Mw5a1tGQ.jpg
Pobierz
Kilka dni temu był wypuszczony kolejny przełom jeśli chodzi o AI; model DallE2, któremu można dać tekst " “Rick and Morty on a planet made of giant strawberries, digital art" na wejście, i daje taki obraz jak niżej. ( ͡° ͜ʖ ͡°)
Albo "35mm macro shot a kitten licking a baby duck, studio lighting", czy "A photo of a Samoyed dog with its tongue out hugging a white Siamese cat" Tutaj
Albo "35mm macro shot a kitten licking a baby duck, studio lighting", czy "A photo of a Samoyed dog with its tongue out hugging a white Siamese cat" Tutaj

źródło: comment_16502057171Zl7oNkDxXTbszK58dOHum.jpg
Pobierz
@Sinity: Niech już ten skynet p--------e
@Sinity: a tak na poważnie, już lata temu myślałem, że będziemy mogli sobie tworzyć własne filmy i seriale. Będzie wystarczyło podać np "Wygeneruj mi proszę film w kanonie Star Trek Next Generation na podstawie i tu link do pdf'a z jakimś fanfic story przy użyciu oryginalnych aktorów."
10 lat myślę, max
10 lat myślę, max
Automatyzacja w obszarze Machine Learning dzięki MLOps

W pewnym momencie trwania projektu ML trzeba przejść z eksperymentowania do wdrożenia. Czy takie przejście wykonywane jest tylko raz? Czy możemy automatyzować wdrażanie rozwiązania ML, od danych do wdrożonego rozwiązania? Czym jest MLOps i jak może nam pomóc automatyzować mądrze?
z- 0
- #
- #
- #
- #
- #
- #
Jaki kierunek studiów wybrać: matematykę czy informatykę, jeśli wiążę swoją karierę zawodową z Data Science? Mam wybór pomiędzy studiami informatycznymi na słabszych warszawskich uczelniach typu SGGW czy WAT, a studiami matematycznymi na MiNI PW lub MIMUW. Co mi da lepsze perspektywy w tej branży? Czy lepiej iść na słabszą uczelnię i uczyć się samemu czy starać się na dobrej uczelni? Olimpijczykiem nie jestem, więc też pytanie czy dam sobie radę na tych
konto usunięte via Android
@init5: Studia niczego nie uczą. Bierz informatykę, bo na matmie tylko zmarnujesz czas i będziesz mieć bezużyteczny dyplom okupiony godzinami nauki i wyrzeczeń.

@init5: matematyke. Predzej nauczysz sie kucowac jako matematyk niz kuca matematyki
Informatyka pod wzgledem jakosci to gowniane studia, nic z nich nie wyniesiesz
Informatyka pod wzgledem jakosci to gowniane studia, nic z nich nie wyniesiesz
Znacie jakieś ciekawe czasopisma, blogi czy kanały, na których pojawiają się nowości ze świata #bigdata #machinelearning #datascience ?
@mk321: opowi pewnie chodzilo o cos w stylu towardsdatascience gdzie sa artykuly w stylu DLACZEGO NIE UZYWAC T-TESTU DLA PROB ZALEZNYCH a ty wyskakujesz z tematami o hipergraficznych sieciach neuronowych ( ͡° ͜ʖ ͡°)

@sidsfd: Na twitterze społeczność DS/ML jest bardzo aktywna. Część z nich to autorzy książek, twórcy kursów itd. Ostatnio jest trochę syfu ze względu na wojnę i kilku gości odjechało od tematu, ale polecam kilka profili:
- fchollet
- aureliengeron
- pythonengineer
- omarsar0
- fchollet
- aureliengeron
- pythonengineer
- omarsar0

#machinelearning
nie ogarniam jak się tworzy nomogramy dla np modelu regresji logistycznej który był trenowany na danych ma covid/ nie ma covidu
i z tego nomogramu mamy scoring który dla 0.05 mówi że przejdzie łagodnie, dla wartości do 0.5 że średnio a powyżej 0.5 że ciężko.
jak to się tworzy?
nie ogarniam jak się tworzy nomogramy dla np modelu regresji logistycznej który był trenowany na danych ma covid/ nie ma covidu
i z tego nomogramu mamy scoring który dla 0.05 mówi że przejdzie łagodnie, dla wartości do 0.5 że średnio a powyżej 0.5 że ciężko.
jak to się tworzy?
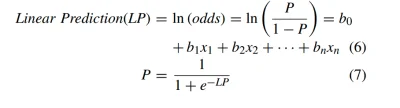
@yras8: https://www.coursera.org/lecture/machine-learning/classification-wlPeP masz za free, cały moduł dotyczący regresji logistycznej. Gdzie Andrew wyprowadza nawet wzory

@yras8: Bierzesz sobie proszę ja Ciebie taki współczynnik b1, liczysz exp(b1) i mówisz ze wraz ze wzrostem x1 o jednostkę (ciągła) lub przy wystąpieniu x1 w porównaniu do niewystąpienia (dyskretna) szanse zachorowania rosną o exp(b1) %

#anonimowemirkowyznania
Czy rynek dla DS i MLE jest rzeczywiście tak biedny, jak sugerują portale z ofertami typu Just Join IT czy No Fluff Jobs? Prawie nic dla juniorów, stawki mega przeciętne w porównaniu z resztą IT, oferty w stylu "minimum 5 lat doświadczenia na podobnym stanowisku, mile widziany doktorat z nauk ścisłych" z widełkami, które może rzucić crudziarz po bootcampie z 4-letnim doświadczeniem. O ile dobrze pamiętam, jeszcze 2 lata
Czy rynek dla DS i MLE jest rzeczywiście tak biedny, jak sugerują portale z ofertami typu Just Join IT czy No Fluff Jobs? Prawie nic dla juniorów, stawki mega przeciętne w porównaniu z resztą IT, oferty w stylu "minimum 5 lat doświadczenia na podobnym stanowisku, mile widziany doktorat z nauk ścisłych" z widełkami, które może rzucić crudziarz po bootcampie z 4-letnim doświadczeniem. O ile dobrze pamiętam, jeszcze 2 lata
@AnonimoweMirkoWyznania: niestety tak to wygląda. ML dostaje pensje juniora zanim się nie nauczy (3-4 lata).

@AnonimoweMirkoWyznania: Wydaję mi się, że firmy nie potrzebują już juniorów DS/MLE. Okazało się, że ML w notebookach to nie jest rozwiązywanie problemów biznesowych tylko zabawa. Co więcej, koszty zespołu DS rosną wykładniczo, wraz ze skomplikowaniem projektu. Nie wyobrażam sobie dać juniorowi zadanie do przygotowania modelu pod trening, który może kosztować nawet kilka tysięcy $. To samo tyczy się przygotowania danych, analizy, rozmowy z klientem i tak dalej.
Problem moim zdaniem jest
Problem moim zdaniem jest
Ukraina używa rozpoznawania twarzy do powiadamiania rodzin zabitych żolnierzy

Zdjęcia zabitych rosyjskich żołnierzy są, za pomocą oprogramowania do rozpoznawania twarzy, zestawiane z bazą milionów profili w mediach społecznościowych. Przy dopasowaniu, rodzina, znajomi zabitego są informowani, że ten zginął na Ukrainie. W ten sposób rosjanie poznają prawdziwy obraz wojny.
z- 5
- #
- #
- #
- #
- #
Treść przeznaczona dla osób powyżej 18 roku życia...

@Popcornn1: a czy można z licencjatem iść na podyplomowe? jeżeli tak, to zamiast się męczyć na jakimś zarządzaniu, zrobiłbyś coś np. ze statystyki (jeżeli chodzi o AI czy ML to pewnie studia w PL nie nadążają z programem, na kursach w necie znajdziesz świeższy kontent)

@heniek_8: na cześć podyplomówek wystarczy licencjat
Czy jak normalizuje feature w traning set to czy muszę też znormalizować ten feature w secie, który służy do predykcji?
#uczeniemaszynowe #machinelearning #datascience #sztucznainteligencja
#uczeniemaszynowe #machinelearning #datascience #sztucznainteligencja

Treść przeznaczona dla osób powyżej 18 roku życia...
I po co zaśmiecasz tag takim wysrywem? Zgłoś jeśli ci się nie podoba i pewnie poprawią
@robo_bobo: generally

Zapraszamy na krótki przegląd ofert z kategorii #datascience i #dataengineering, dla chętnych na przeprowadzkę do #szwajcaria lub #niemcy ( ͡º ͜ʖ͡º)
(SwissDevJobs.ch | LinkedIn | Twitter | Facebook)
(GermanTechJobs.de | LinkedIn | Twitter |
(SwissDevJobs.ch | LinkedIn | Twitter | Facebook)
(GermanTechJobs.de | LinkedIn | Twitter |

źródło: comment_1646820592QwqQ6VLD4OTjBYP507yOdP.jpg
Pobierz@SwissDevJobs: Mam tak właśnie od dwóch tygodni, że ani w domu, ani w pracy nie programuję. Właściwie dzięki wojnie jestem chwilowo bezrobotny. Czuję już, że wyparuje mi z głowy trochę wiedzy

Jakieś dwa lata temu oglądałem filmik, gdzie gość dostroił model języka angielskiego z wykorzystaniem dialogów Jamesa Bonda i wykorzystał go do rozmów na #tinder żeby zautomatyzować zdobywanie numerów. Nie mogę go odnaleźć niestety, może ktoś kojarzy i mógłby podesłać?
#ai #sztucznainteligencja #programowanie #machinelearning
#ai #sztucznainteligencja #programowanie #machinelearning

Treść przeznaczona dla osób powyżej 18 roku życia...

@dplus2: piękne :)
konto usunięte via Wykop Mobilny (Android)


Hej!
Mam pytanko. Gdzie mogę znaleźć algorytmy które zostały niedawno opracowane?
Szukałem na wiki, po pracach naukowych które zostały wypuszczone od 2018 roku, oczywiście też wpisywałem mnóstwo fraz w google ale nic konkretnego nie udało mi się znaleźć ( ͡° ʖ̯ ͡°). Pewnie będę musiał szukać w #machinelearning ale też jeszcze chciałem z innej dzieciny takie algorytmy poznać.
#programowanie #algorytmy i w
Mam pytanko. Gdzie mogę znaleźć algorytmy które zostały niedawno opracowane?
Szukałem na wiki, po pracach naukowych które zostały wypuszczone od 2018 roku, oczywiście też wpisywałem mnóstwo fraz w google ale nic konkretnego nie udało mi się znaleźć ( ͡° ʖ̯ ͡°). Pewnie będę musiał szukać w #machinelearning ale też jeszcze chciałem z innej dzieciny takie algorytmy poznać.
#programowanie #algorytmy i w


#machinelearning #deeplearning #webscraping #datascience #prawo
Mirki, czy wiecie jak obecnie w Polsce wygląda dokładnie prawo autorskie w kontekście gromadzenia treści na potrzeby naukowe? Mam konkretnie na myśli czy tworząc bazę danych obrazów (i ją nieodpłatnie udostępniając) w celu przetrenowania sieci nie łamię prawa? Czy na potrzeby akademickie jest to legalne? Co jeżeli bym gromadził zdjęcia z wyszukiwarek? Badał ktoś ostatnio taką kwestię?
Mirki, czy wiecie jak obecnie w Polsce wygląda dokładnie prawo autorskie w kontekście gromadzenia treści na potrzeby naukowe? Mam konkretnie na myśli czy tworząc bazę danych obrazów (i ją nieodpłatnie udostępniając) w celu przetrenowania sieci nie łamię prawa? Czy na potrzeby akademickie jest to legalne? Co jeżeli bym gromadził zdjęcia z wyszukiwarek? Badał ktoś ostatnio taką kwestię?

Czym jest Uczenie Maszynowe? Dlaczego Machine Learning jest tak istotny? Poznaj szczegóły! https://thestory.is/pl/journal/czym-jest-machine-learning/ #machinelearning #ux #thestory #uczeniemaszynowe #ai

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@thestory: przestańcie spamować tagi, tylko wrzućcie set artykułów w jednym
Jakieś dwa lata temu chwaliłem się stworzeniem strony archiwizującej opóźnienia pociągów PKP i generującej proste prognozy opóźnienia na kolejny dzień.
Dziś chwalę się drugi raz, bo zaktualizowałem serwis do wersji 2.0 (na razie w wersji beta). Wersja ta zawiera dużo nowych funkcjonalności, całkowicie nowy UI oraz stworzony od podstaw model machine learning prognozujący opóźnienia pociągów na podstawie szeregu czynników, w tym opóźnień z poprzednich dni, różnych cech pociągu oraz danych pogodowych. Co więcej,
Dziś chwalę się drugi raz, bo zaktualizowałem serwis do wersji 2.0 (na razie w wersji beta). Wersja ta zawiera dużo nowych funkcjonalności, całkowicie nowy UI oraz stworzony od podstaw model machine learning prognozujący opóźnienia pociągów na podstawie szeregu czynników, w tym opóźnień z poprzednich dni, różnych cech pociągu oraz danych pogodowych. Co więcej,
@jabl: Pewnie! Inspiracją do projektu był projekt Infopasażer Archiver (http://ipa.lovethosetrains.com/) oraz powiązane z nim repozytorium https://github.com/tmaciejewski/ipa. Moja część to modyfikacje kodu tak, aby działał efektywniej i pobierał dane dla wszystkich, albo przynajmniej zdecydowanej większości pociągów, modelowanie danych oraz opakowanie wszystkiego w jak najbardziej przyjazny użytkownikowi UI.
Sam serwis jest oparty na Django + baza w Postgresie. Zintegrowany jest z Infopasażerem poprzez wspomnianą wyżej i zmodyfikowaną bilbiotekę ipa, a także
Sam serwis jest oparty na Django + baza w Postgresie. Zintegrowany jest z Infopasażerem poprzez wspomnianą wyżej i zmodyfikowaną bilbiotekę ipa, a także
@cohontes: Obecny model został wytrenowany na danych obejmujących okres 24 miesięcy i staram się utrzymać ten interwał chociażby po to, żeby model "nauczył się" interpretować miesiące czy też pory roku. Chociaż oczywiście to nie jest koniec i będę próbował też innych podejść.
Sprawdzam na bieżąco faktyczną realizację prognoz (generuję prognozy na wszystkie kombinacje pociąg+stacja) na około północy i sprawdzam potem w trakcie dnia jaki performance miał model na rzeczywistych opóźnieniach.
Sprawdzam na bieżąco faktyczną realizację prognoz (generuję prognozy na wszystkie kombinacje pociąg+stacja) na około północy i sprawdzam potem w trakcie dnia jaki performance miał model na rzeczywistych opóźnieniach.