
Postanowiłem zrobić porównanie szybkości uczenia sieci na różnych urządzeniach i przy użyciu dwóch popularnych frameworków - Pytorch i Tensorflow. Na moim dość starym laptopie mam jedynie GPU AMD i postanowiłem też sprawdzić czy mogę to jakoś wykorzystać. Okazało się, że da się to zrobić jedynie poprzez Tensorflow przy użyciu PlaidML, ale jest to problematyczne i da się wykorzystać jedynie pojedynczy wątek karty podczas gdy przy użyciu CPU domyślnie używane są wszystkie 8.
Wszystko
Najnowsze
Archiwum

@Bejro: robiłeś kiedyś eksperyment czy da się wytrenować speech-to-text z własnych nagrań?
@Oo-oO: Nie bawiłem się jeszcze nigdy w dźwięki. Chciałem zrobić coś takiego w wolnym czasie ale raczej text-to-speech. I wtedy pewnie wziąłbym jakąś dużą bazę i przeprowadził tylko fine tuning na własnych danych.
Mckinsey data science intern Warszawa. Ktoś? Coś? Jak wyglada rekrutacja i jaki ogolnie jest oczekiwany poziom?
#datascience #programowanie #programista15k #machinelearning #pracait
#datascience #programowanie #programista15k #machinelearning #pracait

Szanowny Biznesie, nigdy, NIGDY, N I G D Y nie pozwól, aby Twoją sztuczną yntelygencyje Óczyli brogramiści XD. Nawet na testowym a o UATach już nie wspomnę XD
#programista15k #programowanie #humorinformatykow #pracait #informatyk #sztucznainteligencja #ai #machinelearning
#programista15k #programowanie #humorinformatykow #pracait #informatyk #sztucznainteligencja #ai #machinelearning

źródło: comment_1654034595djf4sDPg5rCQKg52Hif5Hs.jpg
Pobierz@lycaon_pictus: NIe mogę, klauzula sumienia.... to nie jest śmieszne to jest SMUTNE XD LOL

@binarny_pasek: opowiedz historię tego ekranu

Zastanawiam się jak w tym kraju ma być dobrze, skoro firmy w PL chcą mieć pracowników w innowacyjnych działach za 40-60zł za godzinę netto? ( ͡° ͜ʖ ͡°) Przecież taki pracownik przyjedzie tylko po to, żeby zdobyć trochę doświadczenia i przy pierwszej lepszej okazji, jeśli ma trochę rozumu ucieknie do pracy remote w firmie za granicą.
Niedużo mniej zarabia pracownik fizyczny w niektórych miastach (pensja + pod stołem
Niedużo mniej zarabia pracownik fizyczny w niektórych miastach (pensja + pod stołem
@s---k:
od noszenia pustakow nie, ale od pierdzenia w fotel tak
po to, żebyś po 20 latach nie narzekał, że masz zniszczony kręgosłup od noszenia pustaków.
od noszenia pustakow nie, ale od pierdzenia w fotel tak
Treść przeznaczona dla osób powyżej 18 roku życia...

Spójrz, dwa dolary, znakomicie, w mgnieniu oka wyjdziemy z naszego deficytu walutowego.
Czy to nie wspaniałe, Spike?
Nie, nie jestem zwolennikiem inflacji, ale jeśli ty ją lubisz, to rób swoje.
Daj spokój, przestań być takim jastrzębiem.
Tak, papierowe pieniądze to najlepsza rzecz od czasu wynalezienia krojonego chleba.
Pomyśl, ile rzeczy moglibyśmy kupić.

#informatyka #studbaza #doktorat #sztucznainteligencja #machinelearning #datascience #nauka
Hej, kończę właśnie pierwszy rok inżynierki z informatyki, interesują mnie zagadnienia związane ze sztuczną inteligencją stąd też chciałbym się rozwijać w tym kierunku, jednak trochę bardziej w stronę uprawiania nauki niż jedynie poznawania i aplikowania różnych technik. Widzę siebie w przyszłości jako pracownika R&D w sektorze prywatnym, wiem że są to
Hej, kończę właśnie pierwszy rok inżynierki z informatyki, interesują mnie zagadnienia związane ze sztuczną inteligencją stąd też chciałbym się rozwijać w tym kierunku, jednak trochę bardziej w stronę uprawiania nauki niż jedynie poznawania i aplikowania różnych technik. Widzę siebie w przyszłości jako pracownika R&D w sektorze prywatnym, wiem że są to

@arthrilled: Nie wiem na jakiej uczelni studiujesz, ale najlepiej moim zdaniem zagadać do któregoś doktora, profesora na uczelni, który jest aktywny naukowo i spytać, czy mógłbyś asystować przy takich badaniach. To jedna opcja. Druga opcja, to zgłosić się do jakieś instytucji badawczej, może do jakiegoś instytutu PAN i tam podpytać. Do publikacji naukowych itd. powinieneś mieć chociaż inżynierski tytuł, choć i z tym może być ciężko.
Powodzenia :)
Powodzenia :)

@arthrilled: Polecam przyłożyć się po prostu do nauki i do dobrych ocen, próbować napisać fajną inżynierkę i aplikować na staż do CERN / ESA / Maxa Plancka / Fraunhofera itd.

Jaki temat pracy inżynierskiej z #machinelearning mogę se wymyślić? Fajnie jakby nie był zbyt skomplikowany, ale dosyć ciekawy, żebym znalazł promotora.
#programowanie
#programowanie
@BotRekrutacyjny: Recognition of Everyday Activities through Wearable Sensors and Machine Learning

@BotRekrutacyjny: Identyfikacja gatunków kwiatów na podstawie długość i szerokość kielicha oraz płatków ( ͡° ͜ʖ ͡°)
Treść przeznaczona dla osób powyżej 18 roku życia...

@Sinity: zajebiste XD wcześniej nie widziałem

Ktoś miał styczność z DataWorkshop
Jakieś opinie, wrażenia?
#python #machinelearning #datascience #programowanie #programista15k #naukaprogramowania
Jakieś opinie, wrażenia?
#python #machinelearning #datascience #programowanie #programista15k #naukaprogramowania

@Gorthin: brałem udział w darmowych szkoleniach od nich i bylem zadowolony, ale nie zapłaciłbym za nie. Z tego co wiem to ten klub to dostęp do konkursów kaggle od data workshop z przeszlosci.
Lepiej odpal kursy kaggle które są fajnie opracowane i masz je za darmo.
Lepiej odpal kursy kaggle które są fajnie opracowane i masz je za darmo.
@Gorthin mogę powiedzieć, że takie sobie... nie wiem jak zmienił się materiał, ale co jest tam pokazane można znaleźć dzisiaj na medium.
Jeśli nie umiesz nic w data to możesz iść, na pewno poznasz innych ludzi i coś się nauczysz. W przeciwnym wypadku polecałbym coś bardziej z udacity np mle, ds, de albo edx np. ml fundamentals z sandiego. Dużo teorii, ale na pewno poznasz działanie algorytmów od środka i będziesz
Jeśli nie umiesz nic w data to możesz iść, na pewno poznasz innych ludzi i coś się nauczysz. W przeciwnym wypadku polecałbym coś bardziej z udacity np mle, ds, de albo edx np. ml fundamentals z sandiego. Dużo teorii, ale na pewno poznasz działanie algorytmów od środka i będziesz


Elon, jego nowa strona, która pomaga zdobyć niezależność finansową ( ͡° ͜ʖ ͡°)
#kryptowaluty #ethereum #machinelearning
#kryptowaluty #ethereum #machinelearning


@ForTheEvulz: Na Elona bym się nie dał nabrać, ale jak już Saylor promuje, to raczej legit ( ͡° ͜ʖ ͡°)


Kolejny dzień zabawy Google Colab. Tym razem ""200000 people at a music festival, Gustave Doré purgatory and paradise, zdzislaw beksinski" #machinelearning #sztucznainteligencja #sztuka #discodiffusion.

źródło: comment_16524655939izms930NjLveBqxarSvAK.jpg
Pobierz
@kartofel: @szczepan-szczypawa:
No właśnie nie, z Disco Diffusion.
Tutaj są szczegóły:https://www.reddit.com/r/DiscoDiffusion/
Aż sobie kupiłem na miesiąc Google Colab Pro żeby fajniej szło :)
No właśnie nie, z Disco Diffusion.
Tutaj są szczegóły:https://www.reddit.com/r/DiscoDiffusion/
Aż sobie kupiłem na miesiąc Google Colab Pro żeby fajniej szło :)

źródło: comment_16524672254MdQvWCGyhY6aQPfuZAS7B.jpg
PobierzUczenie maszynowe dla przestępców komputerowych
https://silencedevs.com/images/Czyli trochę o tym, jak cyberprzestępcy mogą wykorzystać uczenie maszynowe do popełniania wyrafinowanych przestępstw komputerowych.
z- 0
- #
- #
- #
- #
- #
- #

DALL-E 2... tylko jedno słowo przychodzi mi na myśl żeby opisać możliwości tego modelu.... WOW
AI które generuje grafikę na podstawie opisu tekstowego.
#technologia #sztuka #ai #machinelearning #sztucznainteligencja
AI które generuje grafikę na podstawie opisu tekstowego.
#technologia #sztuka #ai #machinelearning #sztucznainteligencja

Przykład: "a raccoon wearing a hoodie working on his laptop late into the night"
Jak dla mnie kurła niesamowite.
Jak dla mnie kurła niesamowite.

źródło: comment_1651685011s7GCKG0rRUom404HKUtYrK.jpg
Pobierz@Kresse: tu masz kanał kolesia który omawia sprawę bardziej technicznie ogólnie ma dość ciekawy kanał o AI, ML (przynajmniej dla mnie laika w temacie).


Hej! Potrzebuje pomocy speców od #machinelearning #deeplearning #ai #ml
Mam do zrobienia projekcik na zaliczenie, i są to dla mnie totalnie nowe tematy - zaimplementowanie ai w grach. Zacząłem robić reinforcement learning, na podstawie tutoriala snake'a (https://www.youtube.com/watch?v=PJl4iabBEz0&list=PLqnslRFeH2UrDh7vUmJ60YrmWd64mTTKV&index=2). I mam sobie stany do uczenia modelu i w snaku to wygląda tak ze mam:
Mam do zrobienia projekcik na zaliczenie, i są to dla mnie totalnie nowe tematy - zaimplementowanie ai w grach. Zacząłem robić reinforcement learning, na podstawie tutoriala snake'a (https://www.youtube.com/watch?v=PJl4iabBEz0&list=PLqnslRFeH2UrDh7vUmJ60YrmWd64mTTKV&index=2). I mam sobie stany do uczenia modelu i w snaku to wygląda tak ze mam:
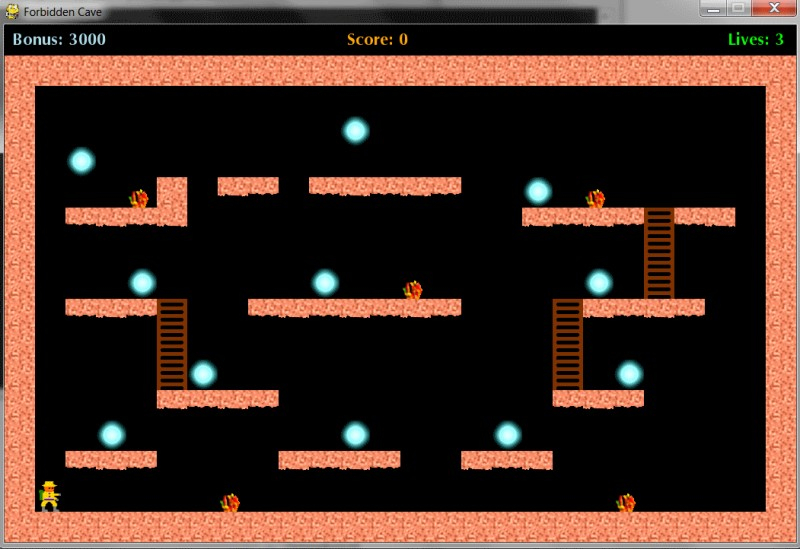
state [dangerstraight, dangerright, dabgerleft, direction left, direction right, direction up, direction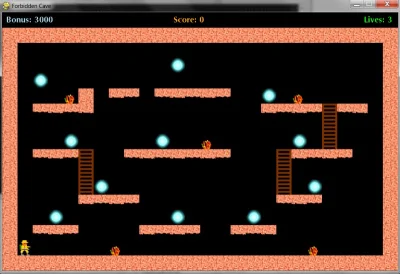
źródło: comment_1651335526WsxlTtN58sYwypjrnKYKN8.jpg
Pobierz
@TheRickestRick
jeśli w forbidden cave np. wciśnięcie strzałki lewo sprawia, że postać przemieszcza się jednorazowo, o taką samą odległość w lewo bez względu na to, w którą stronę była wcześniej zwrócona, to tak
Ale ja mam grę ze zdjęcia (forbidden cave) i przy mojej postaci chyba nie będzie kierunku tak?
jeśli w forbidden cave np. wciśnięcie strzałki lewo sprawia, że postać przemieszcza się jednorazowo, o taką samą odległość w lewo bez względu na to, w którą stronę była wcześniej zwrócona, to tak
@TheRickestRick Powinno być wszystko to, co może mieć wpływ na efekt podjęcia akcji, czyli na przykład
obstacle_left, bo jeśli będąc na pozycji widocznej na screenie klikniesz strzałkę w lewo to zakładam, że nic się nie stanie. Pewnie jakiś wpływ ma też drabinka, więc również ladder_up
czy to normalne że framework Darknet zwiększa learning rate z biegiem iteracji zamiast zmniejszać? Pierwszy raz się z czymś takim spotykam
#machinelearning #machinelearning
#machinelearning #machinelearning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Spotkaj gwiazdy światowej i polskiej sceny IT na Infoshare F3
Udział jest całkowicie ZA DARMO ( ͡° ͜ʖ ͡°) (chyba, że masz ochotę wesprzeć Ukrainę, kupując bilet Premium)
https://bulldogjob.pl/readme/spotkaj-gwiazdy-swiatowej-i-polskiej-sceny-it-na-infoshare-f3
#programowanie #naukaprogramowania #sopot #testowanieoprogramowania #devops #backend #frontend #machinelearning
Udział jest całkowicie ZA DARMO ( ͡° ͜ʖ ͡°) (chyba, że masz ochotę wesprzeć Ukrainę, kupując bilet Premium)
https://bulldogjob.pl/readme/spotkaj-gwiazdy-swiatowej-i-polskiej-sceny-it-na-infoshare-f3
#programowanie #naukaprogramowania #sopot #testowanieoprogramowania #devops #backend #frontend #machinelearning

źródło: comment_1651068429DbZgrZBpGSNpa1NNhFauar.jpg
Pobierz{kind=link}
Witam was Mirki, mam pilne pytanie.
Czy kategoria "melanocytic nevi" ze zbioru danych HAM10000 to ta sama kategoria, albo podkategoria podobnej zmiany skórnej "Nevus" ze zbioru danych ISIC2020?
Pytam, ponieważ próbuję stworzyć klasyfikator rozróżniający różne zmiany skórne i się zastanawiam, czy rozdzielanie "melanocytic nevi" i "Nevus" na dwie kategorie ma sens. Po dodaniu ósmej kategorii(Nevus), do modelu parametr "accuracy" mocno spadł. Bez kategorii "Nevus" po jednym przejściu(1 epochs, 150 steps) klasyfikator uzyskiwał taki wynik:
loss:
Czy kategoria "melanocytic nevi" ze zbioru danych HAM10000 to ta sama kategoria, albo podkategoria podobnej zmiany skórnej "Nevus" ze zbioru danych ISIC2020?
Pytam, ponieważ próbuję stworzyć klasyfikator rozróżniający różne zmiany skórne i się zastanawiam, czy rozdzielanie "melanocytic nevi" i "Nevus" na dwie kategorie ma sens. Po dodaniu ósmej kategorii(Nevus), do modelu parametr "accuracy" mocno spadł. Bez kategorii "Nevus" po jednym przejściu(1 epochs, 150 steps) klasyfikator uzyskiwał taki wynik:
loss:
@varchar12: nie znam, po prostu mnie zaciekawiłeś tematyką projektu, więc co z tym złego/dziwnego, że zadaję pytania?
@masterix: Dzięki, zachęciłeś mnie aby wrzucić tutaj później ten projekt. Zamierzam we flasku dopisać do tego jakiś prosty interfejs i udostępnić w darmowej domenie, więc podeślę linka tutaj. Aktualnie mam spory problem z niezbalansowanymi danymi. W klasie liczącej najwięcej danych jest ich 6000 a w najmniejszej 100, co trochę psuje cały model. Poczytałem gdzieś, że dostosowanie wag mogło by w tej sytuacji pomóc. Ale nie pomaga. Zastosowałem tutaj automatyczne obliczenie
Szukam obecnie materiałów do nauki modułów ML w Pythonie (sklearn, Tensorflow). Aspekt teorytyczny jest mile widziany, ale nie jest priorytetem, ponieważ mam od tego przedmiot na uczelni. Zależy mi na tym, aby było dużo praktyki i weryfikacji wiedzy - zadań lub projektów. Zna ktoś może odpowiednie książki/kursy/serie na YT? Osobiście znalazłem ze dwie/trzy sensownie wyglądające serie na youtube oraz dwie książki na PWN Uczenie maszynowe z użyciem Scikit-Learn i TensorFlow oraz Python
Dzięki!
@szczepan-szczypawa: Dzięki!
Jest tu jakiś programista machine learning? Jak zacząć naukę od zera? Mam już kilka lat doświadczenia w programowaniu i teraz chciałbym poduczyć się czegoś "na topie". Polecacie jakąś książkę czy może cisnąć np. udemy ?
#programowanie #machinelearning #sztucznainteligencja #programista15k #rozwojosobisty
Tutaj przykładowy kurs na aws