

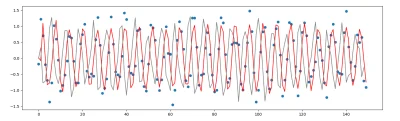
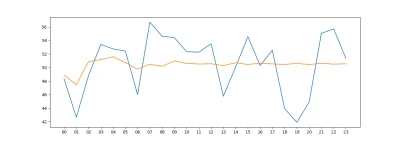
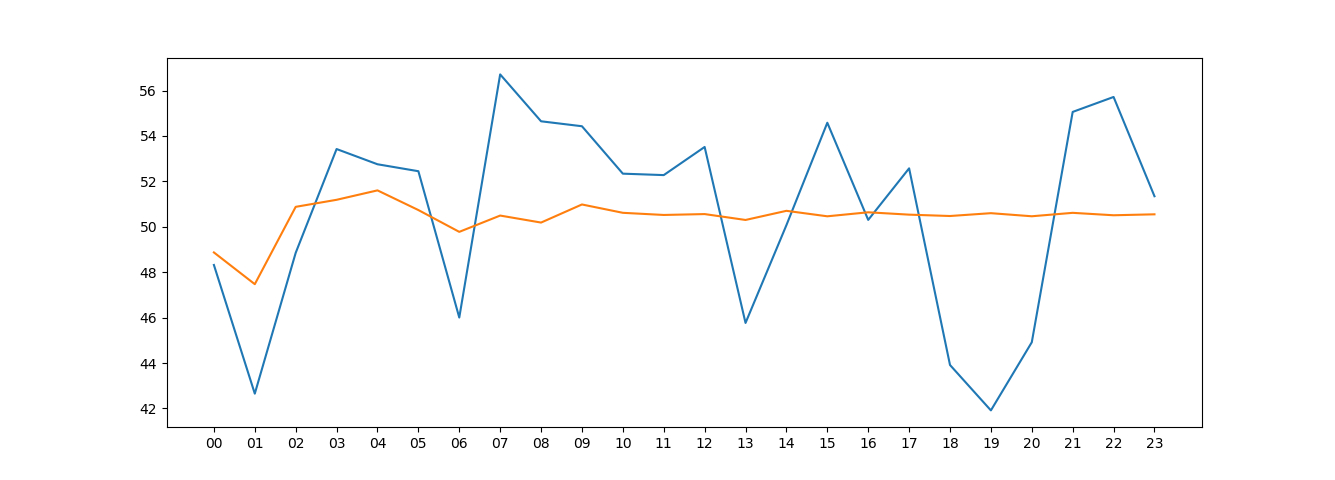
Ma może jakiś mireczek pomysł dlaczego mój model ARIMA wydaje się być "za szybki" ? ARMA prezentuje się o wiele lepiej. Implementację przeprowadziłem w ten sam sposób w obu wypadkach.
Wartość kryterium kwadratowego dla:
ARMA - 15.547208104591215
ARIMA
Wartość kryterium kwadratowego dla:
ARMA - 15.547208104591215
ARIMA



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Co oznacza interfejsowanie w branży IT / data?
Takie sformułowania:
"Logika