Mirki #programowanie #python mam pytanie dotyczące polskiego słownictwa: jak mówimy zainstaluj python to jaki produkt mamy na myśli? Co jest potrzebne do uruchomienia program.py?
Wszystko
Najnowsze
Archiwum

piwuch
Moron
@piwuch: jak mówimy zainstaluj python to oznacza to zainstaluj python. Python downloads i tyle.

yupitr
@piwuch: dokładnie tak jak @Moron prawi - zainstaluj Pythona to po prostu zainstaluj Pythona. Wpisujesz install Python Windows (bo normalne systemy mają to już z automatu zainstalowane) i tyle ¯\_(ツ)_/¯
Mając private key - mogę utworzyć nowy adres? Żeby każdy nowy wygenerowany adres był unikalny.
#bitcoin #kryptowaluty #python #programowanie
#bitcoin #kryptowaluty #python #programowanie



Czy da się opakować "Hello Adam" w gwiazdki na górze i na dole? Teraz return kończy działanie funkcji i *** printują się tylko na górze.
def upper_case(func):
def wrapper(*args, **kwargs):
print("*" * 15)
return func(*args, **kwargs).upper()

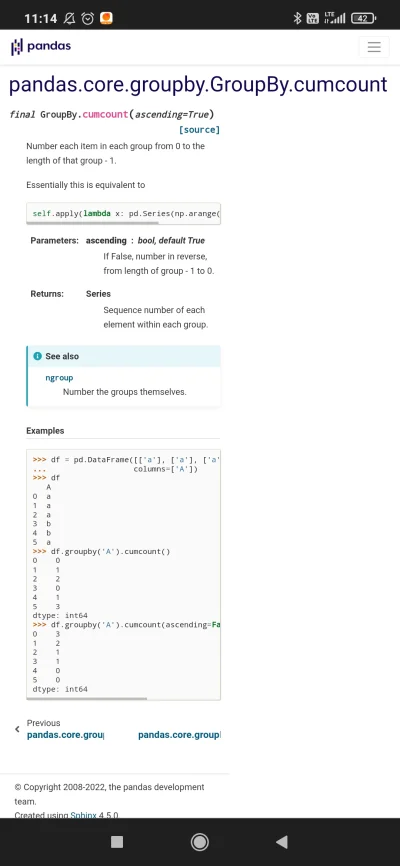

hej #python ale mam kod, można wygrać miliony! ( ͡€ ͜ʖ ͡€)
[3, 13, 15, 24, 27, 30]
Jak coś, to nie zapomnijcie dzięki komu wygraliście ( ͡° ͜ʖ ͡°)
[3, 13, 15, 24, 27, 30]
Jak coś, to nie zapomnijcie dzięki komu wygraliście ( ͡° ͜ʖ ͡°)



#programowanie #flask #python #programista15k #informatyka
Czy jeśli przykładowo mam takie pliki, to mogę je wrzucić do
if _name == 'main_': ?
Czy jeśli przykładowo mam takie pliki, to mogę je wrzucić do
if _name == 'main_': ?
źródło: comment_1650920406YshaAYdYwkloQI7xnwPich.jpg
Pobierz
Załóżmy, że zapisuję takie wywołanie funkcji: funkcja( arg1 = "Jan" ).
Podczas takiego wywołania funkcji fachowo na arg1 mówimy parametr, a na "Jan" argument?
#naukaprogramowania #python
Podczas takiego wywołania funkcji fachowo na arg1 mówimy parametr, a na "Jan" argument?
#naukaprogramowania #python
@kazber95: parametr jest w definicji funkcji, a argument jest podawany przy jej wywoływaniu.
@8kWq5N8fmyQRCClShgBD3pySODQqjXU: tak zasadzie to w obu przypadkach można użyć slowa argument, w definicji jest to argument formalny, a w wywołaniu jest to argument aktualny
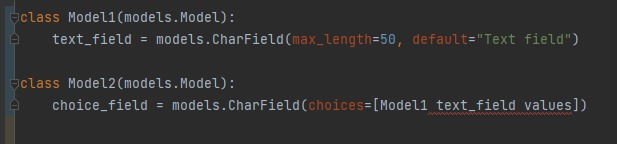
Czy można już na poziomie modelu zdefiniować pole, które będzie wyliczone z innych pól? Coś w tym stylu:
#django #python #programowanie
#django #python #programowanie

źródło: comment_1650899624SHt0Z6YuFuM0piXi9FKpu8.jpg
PobierzKomentarz usunięty przez autora
@Spofity: nie uzywaj floatow do trzymania kasy
https://dzone.com/articles/never-use-float-and-double-for-monetary-calculatio
uzyj tego
https://docs.djangoproject.com/en/4.0/ref/models/fields/#decimalfield
https://dzone.com/articles/never-use-float-and-double-for-monetary-calculatio
uzyj tego
https://docs.djangoproject.com/en/4.0/ref/models/fields/#decimalfield
Koduje od 15 lat w #java a obecnie prawie w ogóle bo wywaliło mnie zbyt wysoko w strukturze korpo, ale planuję złapać kontakt z gruntem w najbliższej przyszłości.
Moja domena to rozproszone systemy wysokiej wydajności - 100% backend.
Dla sportu, ale i pragmatycznie chce nauczyć się nowego języka i rozważam teraz tylko dwa już.
Pomóżcie,
Moja domena to rozproszone systemy wysokiej wydajności - 100% backend.
Dla sportu, ale i pragmatycznie chce nauczyć się nowego języka i rozważam teraz tylko dwa już.
Pomóżcie,
Jakiego języka anonek ma się nauczyć
- Kotlin 53.5% (54)
- Python 46.5% (47)
@kobrys13: kotlin bo dobry keczup mają
jak wygląda to z perspektywy architektury i potencjalnych zastosowań?
@StalowyRoman: Generalnie to systemy gdzie przychodzi dużo danych wejściowych w postaci eventów businessowych, a my musimy je procesować w kolejności, a processing jest stanowy (jest wiele eventów dla tego samego ID).
W dodatku wynik procesingu jest uzależniony od tego co przychodzi jak i tego co do tej pory udało się już przeprocessować i wysłać.
Processing jest wielokrokowy i komunikacja jest wielokierunkowa - coś jakby

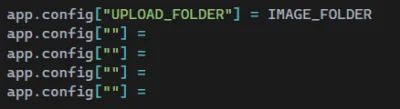
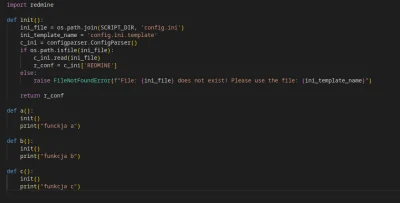
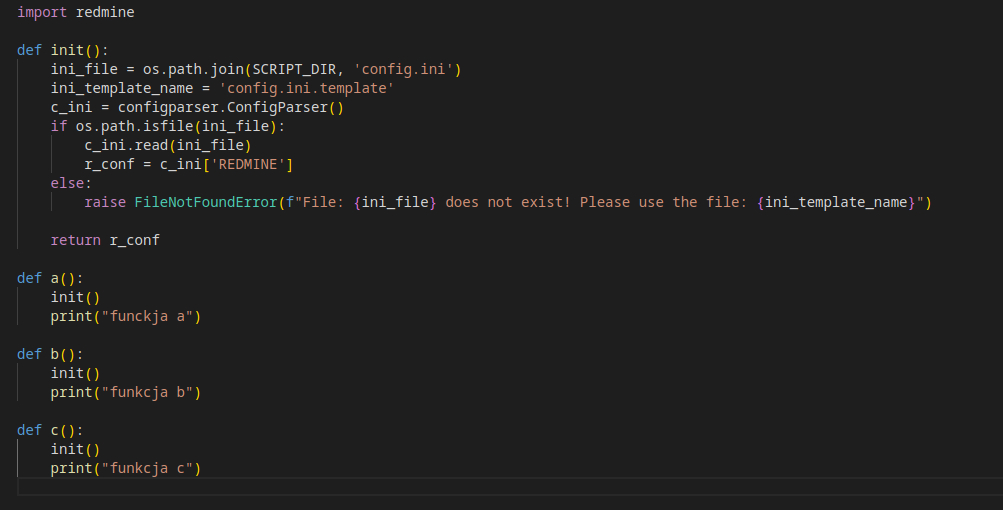
Mam sobie plik 1.py - z niego potrzebuje wołać konkretne funkcje z pliku 2.py, jednak chciałbym żeby za każdym razem przy wywołaniu funkcji z 2.py wywołała się funkcja init() w której mam configparsera.
Da się to obejść bez wywoływania za każdym razem init() w funkcji którą chcę wywołać?
#python #programowanie
Da się to obejść bez wywoływania za każdym razem init() w funkcji którą chcę wywołać?
#python #programowanie
źródło: comment_1650874504YuLKrXOUJE22gFF5j0BqLV.jpg
Pobierz
@NewEpisode: może po prostu zrób z tego klasę i ładuj config w
__init__?@NewEpisode: już
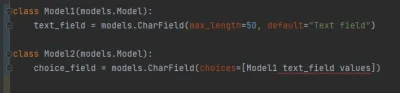
Czy da się stworzyć model w #django, który będzie miał opcję wyboru opcji z pola innego modelu? Cięzko mi wytłumaczyć co chcę zrobić, może ten fragment kodu coś rozjaśni
#programowanie #python
#programowanie #python
źródło: comment_1650824028oUVnR17lalUM6rXECD5xnz.jpg
Pobierz

Jak zapisać plik .py z notatnika? Widziałem, że niektórzy mogą po prostu wybrać format z rozwijanego okna ale u mnie nie ma nic po instalacji 3.10.
#python
#python

@ZmyslonyNick: W windows w eksploatorze klikasz "widok" i naznaczasz "rozszerzenia nazw plików".

@ZmyslonyNick: To nawet nie jest pytanie o programowanie i pythona, tylko o to jak mało wiesz o swoim systemie operacyjnym.

#anonimowemirkowyznania
Cześć, pytanie do starszej części wykopu (35+), wiem, że tu jesteście! :D
Tl;dr
Pieniądze szczęścia nie dają?
Mam
Cześć, pytanie do starszej części wykopu (35+), wiem, że tu jesteście! :D
Tl;dr
Pieniądze szczęścia nie dają?
Mam

@AnonimoweMirkoWyznania: uuuu trudne się wylosowalo xD

@AnonimoweMirkoWyznania: rób to co lubisz, olej opinie innych. Jesteś w mega komfortowej i rzadkiej sytuacji.
#flask #informatyka #python #programista15k #programowanie
FLASK
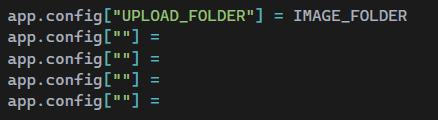
jak naprawić ten kod, żeby mój css pobierał do pliku strony? Mam tak zdefiniowane i nic sie nie dzieje
FLASK
jak naprawić ten kod, żeby mój css pobierał do pliku strony? Mam tak zdefiniowane i nic sie nie dzieje
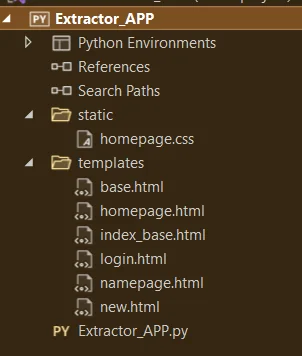
źródło: comment_16507476119dQsXQWq7ZST06MIERvt1Y.jpg
Pobierz@harnasiek: https://flask.palletsprojects.com/en/2.1.x/tutorial/static/
header templatki zamienia na adres bezwzgledny pliku css
header templatki zamienia na adres bezwzgledny pliku css
Zdzisław Beksiński: "Nadzieja na zgliszczach". Obrazy AI w hołdzie dla...

Zdzisław Beksiński. Obrazy sztucznej inteligencji z motywami wiosny i Ukrainy. Te obrazy stworzył algorytm. Są wspaniałe!
z- 86
- #
- #
- #
- #
- #
- #
#anonimowemirkowyznania
Tl;dr
Cześć. Pracuje w #ksiegowosc 5 lat, a na samodzielnym stanowisku od 3 lat, mam również magistra z finansów i II SKWP.
Myślałam, że to moja branża. Chciałam się w niej rozwijać, ale coś we mnie pękło i teraz czuję tylko niechęć. Myślę o przebranżowieniu się na analityka, ale nie wiem jakiego xD
Tl;dr
Cześć. Pracuje w #ksiegowosc 5 lat, a na samodzielnym stanowisku od 3 lat, mam również magistra z finansów i II SKWP.
Myślałam, że to moja branża. Chciałam się w niej rozwijać, ale coś we mnie pękło i teraz czuję tylko niechęć. Myślę o przebranżowieniu się na analityka, ale nie wiem jakiego xD
@AnonimoweMirkoWyznania: firmy bardzo różnie definiują stanowiska. Takie porównanie, nie ma sensu.

@AnonimoweMirkoWyznania: odezwij się na priv, może coś wymyślę :)

Mam do zrobienia program w pythonie, będzie on służył do przeprowadzenia testów automatycznych wykorzystując API. Ogólnie wiem, że można to zrobić tworząc plik *.js, a następnie odczytać go za pomocą VUE i odpalić jako HTML. Zastanawiam się czy jest jakiś ciekawy tutorial jak to wszystko połączyć. Jakimi bibliotekami się zainteresować i w ogóle.
Strona w Vue nie będzie jakoś mega rozbudowana, ma pokazywać ilość testów przeprowadzonych, ile się udało ile nie i
Strona w Vue nie będzie jakoś mega rozbudowana, ma pokazywać ilość testów przeprowadzonych, ile się udało ile nie i

@Tytyka: wpisz w google "python + Vue tutorial"

hej Mirasy
jak że mam już dość swojej pracy i chciałbym się trochę przebranżowić pomyślałem że pouczę się trochę i zostanę #programista15k xD jednak problem jest taki że nie mam podstaw
tzn jeszcze na studiach próbowałem coś tam pisać w #python ale później jak już poszedłem do #pracbaza to porzuciłem to
chciałbym do tego wrócić i znajomy mi mówił że u nich w firmie szukają programistów
jak że mam już dość swojej pracy i chciałbym się trochę przebranżowić pomyślałem że pouczę się trochę i zostanę #programista15k xD jednak problem jest taki że nie mam podstaw
tzn jeszcze na studiach próbowałem coś tam pisać w #python ale później jak już poszedłem do #pracbaza to porzuciłem to
chciałbym do tego wrócić i znajomy mi mówił że u nich w firmie szukają programistów
Komentarz usunięty przez moderatora

Treść przeznaczona dla osób powyżej 18 roku życia...

Cześć ( ͡° ͜ʖ ͡°) Mamy dla Was najnowszą listę ofert pracy z kategorii #backend ( ͡° ͜ʖ ͡°)
Zdalnie
• Python Developer (Big Data) | Randlab | 13-20k
https://crossweb.pl/job/Bww8e
• C++
Zdalnie
• Python Developer (Big Data) | Randlab | 13-20k
https://crossweb.pl/job/Bww8e
• C++

źródło: comment_1650616821bEbDamRmU5UbbS27UrR8KH.jpg
Pobierz
Jakaś biblioteka, którą będę mógł zrobić wiszące powiadomienie w Windowsie i da się spełnić te dwa warunki?
- Powiadomienie permanente do puki się go nie zamknie
- Okienko nie przyblokuje pracy w innej aplikacji w momencie pojawienia się
#python #programowanie
- Powiadomienie permanente do puki się go nie zamknie
- Okienko nie przyblokuje pracy w innej aplikacji w momencie pojawienia się
#python #programowanie

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@Krunhy: póki #grammarnazi
Komentarz usunięty przez autora