Wszystko
Najnowsze
Archiwum

Sztuczna inteligencja, czyli rewolucja dla fabryk i elektrowni

Wysoka moc obliczeniowa, umiejętność logicznego wykorzystania informacji i co najważniejsze – zdolność uczenia się. Twórcy technologii od lat inspirują się ludzkim organizmem, którego zdolności wspierane są przez właściwości maszyn. Technologia w funkcjonowaniu przedsiębiorstw
z- 5
- #
- #
- #
- #
- #
- #


Python, R, Scala and Julia in one Notebook [eng]
![Python, R, Scala and Julia in one Notebook [eng]](https://wykop.pl/cdn/c3397993/link_ZJ8tJeqSFHeWxY0LDt14Vk52CVChRbt5,w220h142.jpg)
Use R, Julia, Scala or Python? The answer is: Yes! How to create versatile environment, in which different languages are available and able to communicate with each other? Without changing program you work in and where data may be passed between specific structures characteristic for the...
z- 0
- #
- #
- #
- #
- #


#raport #it #analityk #praca #datascience
#bigdata
Mnie by dodatkowo interesowało: tendencja rozwojowa, sezonowość, koncentracja wg kontrahentów oraz kwestia płatności faktur, bo można mieć zysk i stracić płynność. Jeśli chodzi
Są fajne paczki do wizualizacji nawet w formie interaktywnej, ale ogólnie to najlepiej ładne wykresy i ew możesz jakąś analizę statystyczną zrobić. Ekspertem nie jestem, uczę się dopiero, ale tak to widzę.
https://soundcloud.com/twiml/twiml-talk-033-ben-vigoda-power-probabilistic-programming
#datascience #siecineuronowe no i z #programowanie może kogoś zainteresuje
Co należy wiedzieć, albo czego nie wiedzieć nie można idąc na interview na stanowisko level zielonka ze secjalizacją DataScience ? Język Python i związane z nim bilbioteki typu numpy, scipy są w wymaganiach. Ma ktoś doświadczenie z takiej rozmowy, jakieś typowe pytania, zagadanienia ?
#python #machinelearning #pracait #programista15k #datascience

Od października zaczynam studia magisterskie na kierunki Big Data na SGH (inżyniera robiłem na zupełnie innym kierunku) i zastanawiam się jak najlepiej rozwijać się w tej branży. Z tego co wiem, na studiach będe miał możliwość poznania
@mam_Cie_na_strzala: Big data jest ścieżką opierającą się na analizie dużych wolumenów danych. Bardziej niż technologie ważniejsze jest zrozumienie procesów i technik umożliwiających składowanie i analizowanie dużej ilości danych. Po drodze pewno poznasz parę języków ( jak np python i go ) i narzędzi ( takich jak SQL, Hadoop .. ), ale nadal najważniejsze jest zrozumienie sposobów podejścia
Generalnie data science to szerokie pojecie. W roznych firmach zatrudniaja DS i w ramach tej samej pozycji, zakres obowiazkow moze byc rozny (nawet w tej samej firmie). To co jest konieczne zeby byc DS to:
1. statystyka
2. SQL
3. znajomosc programowania - w stopniu pozwalajacym na samodzielne pisanie skryptow (Python
Minął tydzień, na razie powolutku do przodu, pierwsi chętni to zgłębiania tematyki już są.
Na razie, przed oficjalnym startem, na rozgrzewkę wrzucamy jakiś kurs #python bo jak by nie patrzeć, aktualnie #machinelearning, ogromna część to Python i R.

źródło: comment_GdMbyJJ1R6TNSolyN7apeQ1aXP1qSTRq.jpg
Pobierz
Komentarz usunięty przez autora
jakiś poziom zaawansowania uczestniczących jest wymagany?
@boloney: No najlepiej jak ktoś coś tam ogarniał, chociaż w minimalnym stopniu, czy to miał pojęcie coś o programowaniu, czy też już coś z nazwijmy to data science ogólnie.
Aczkolwiek jak ktoś jest silnie zmotywowany i jest w miarę rozgarnięty, może i od zera, większość kursów (te które ruszymy za 10 tyg. będzie i tak leciała od podstaw (tylko różnie ludzie mogą myśleć co


http://www.learndatasci.com/free-data-science-books/
http://www.kdnuggets.com/2015/09/free-data-science-books.html
#whatadata – analiza i wizualizacja danych, statystyka, ciekawostki z półświatka Data Science ( ͡° ͜ʖ ͡°)
PyData Seattle 2017

Zbiór tegorocznych filmików z PyData Seattle 2017 (July 5-7 2017)
z- 0
- #
- #
- #
- #
#polska #swiat #socjologia #datascience #ciekawostki
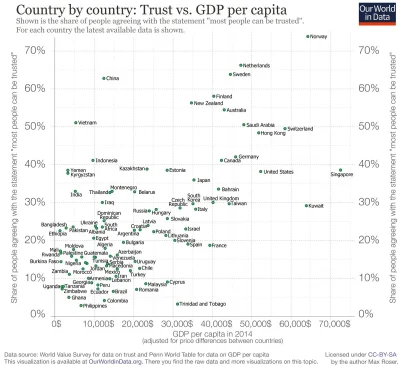
źródło: comment_0s0bIfWpHmClOPJHzS5UseBO3BvnqUfQ.jpg
Pobierz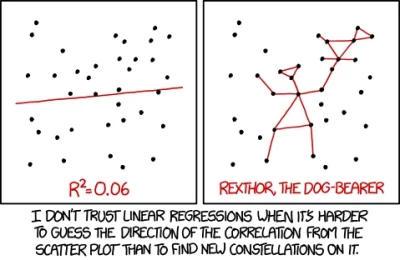
Świetna wizualizacja danych z Airbnb

Świetna wizualizacja danych z Airbnb na przestrzeni lat. Gdy lokal pojawił się dostępny do wynajmu po raz pierwszy, pojawia się na mapie. Dostępne miasta: Amsterdam, Barcelona, Nowy Jork, Berlin.
z- 1
- #
- #
- #
- #
- #
- #

#pytanie #kiciochpyta #studbaza #datascience podejrzewam, że społeczność #udemy #kursyudemy też się coś może wypowiedzieć.

Okazuje się, że bakterie w nim zawarte i ich proporcje mogą powiedzieć całkiem sporo o składzie osób przebywających w danym pomieszczeniu. Kobiety, mężczyźni, psy, koty - kogo więcej, kogo mniej?
Otwieramy w nowej karcie i sprawdzamy jakich dodatkowych lokatorów mamy w domu :)
#biologia #datascience #ciekawostki a przy okazji kolejna przyjemna #wizualizacja danych
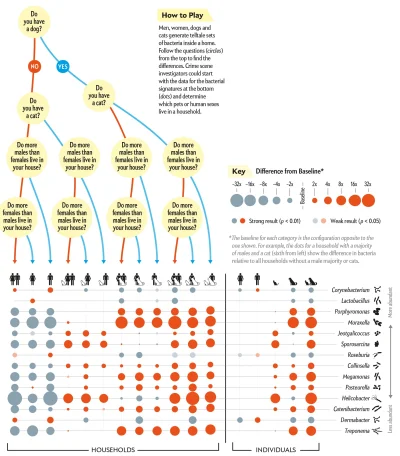
źródło: comment_PyDtDWt5QfkWYkp086x790hKiMrWmelp.jpg
Pobierza = c(aa = "111", cc = "222")
b = c(aa = "333", cc = "444")
l = list(a ,b)Oczekuje kolumny aa z wartościami 111 oraz 333 a dostaję wiersz aa z tymi wartościami. Analogicznie w przypadku wiersza b
#rproject #datascience

{kind=link}
{kind=link}
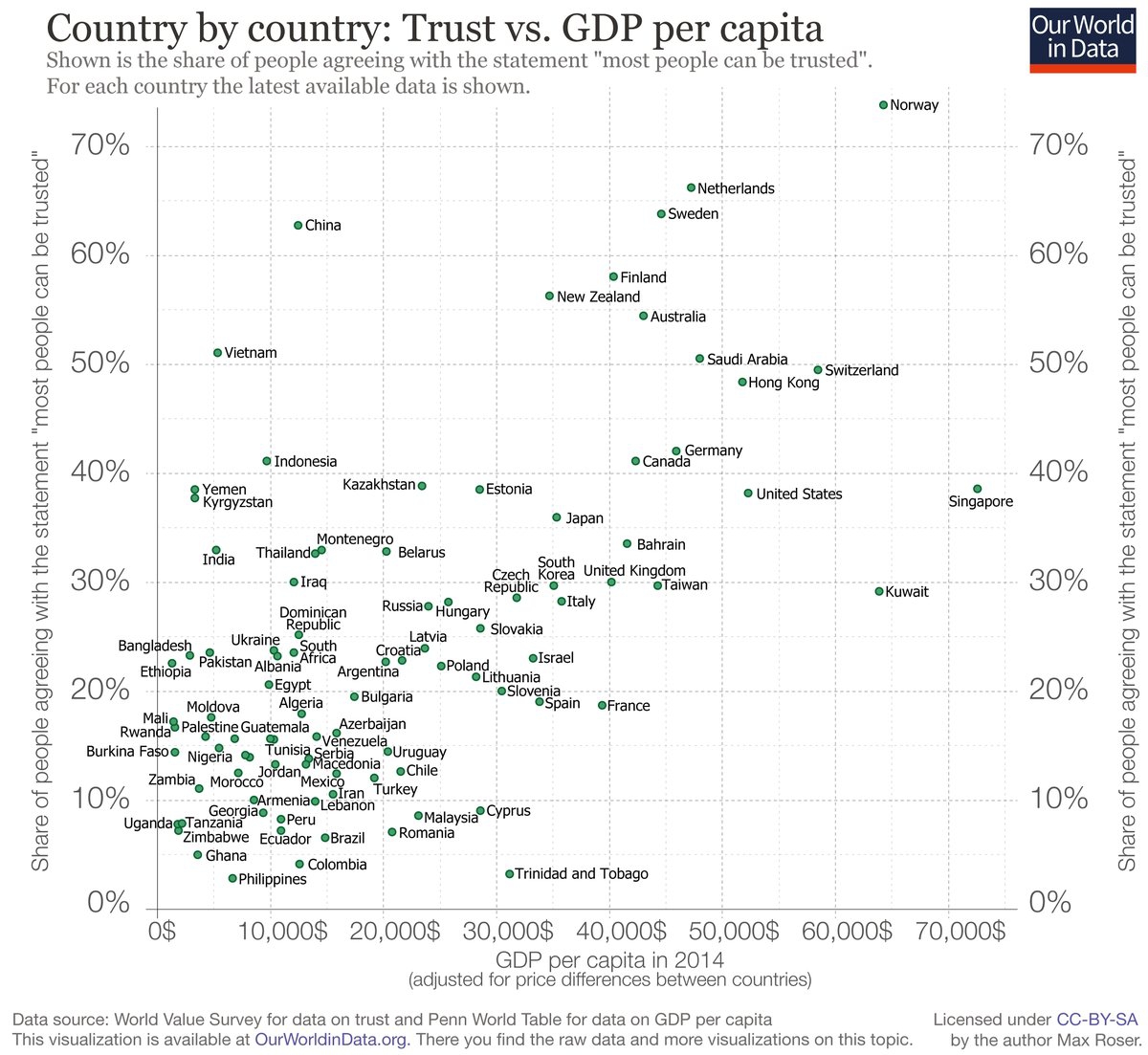{kind=link}
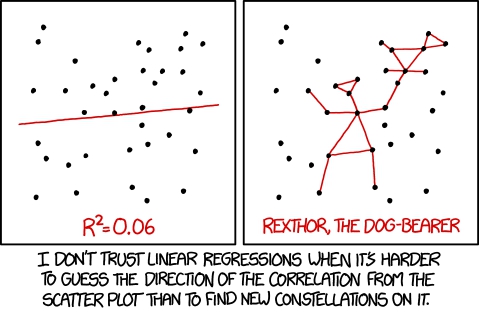{kind=link}
{kind=link}
Ostatnio myślałem o magisterskich zagranicą, już
#sql #bazydanych #datascience #programowanie
@BillyMenadzer Co do wyglądu kodu.
Tutaj masz pokazanych kilka "dobrych praktyk", których ludzie się trzymają, oraz odnośniki do blogów: https://stackoverflow.com/questions/522356/what-sql-coding-standard-do-you-follow
Możesz skorzystać ze stron i programów, które po wpisaniu kodu sformatują Ci go. Jeśli któraś forma Ci się spodoba i łatwiej Ci na niej pracować, to takiej się trzymaj.