
Hej #machinelearning i #datascience. Ostatnio po głowie chodził mi problem największego możliwego wpisanego okręgu w jakiś obszar zdefiniowany przez punkty na płaszczyźnie. Okazało się, że całkiem sprytnie można to rozwiązać za pomocą diagramów Woronoja. Jakby ktoś był zainteresowany, to zapraszam do artykułu:
https://www.jakbadacdane.pl/jakosc-powietrza-w-polsce-3-gdzie-brakuje-nam-czujnikow/
#jakbadacdane
https://www.jakbadacdane.pl/jakosc-powietrza-w-polsce-3-gdzie-brakuje-nam-czujnikow/
#jakbadacdane
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
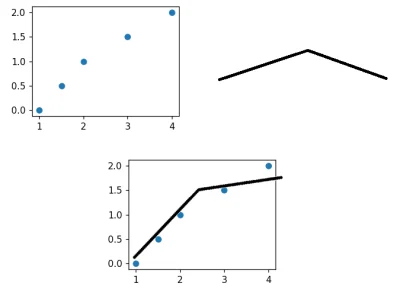
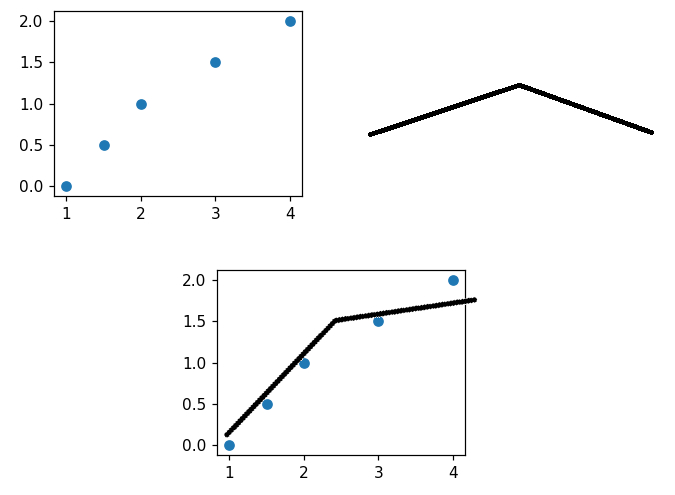
Wygenerowałem wykres 3d (3D wireframe) i powiedzmy że zakres osi z jest równy 100, chciałbym podejrzeć wykres osi x i y w pkt 55 z.
Za każdą podpowiedź artykuł będę bardzo wdzięczny
#python #programowanie #naukaprogramowania #datascience #analizadanych
I jeszcze pytanko czy da sie zrobić taki dynamiczny podgląd (jakby pokaz slajdów wykresów 2d) - jakby wygenerować suwak na którym będą całkowite
link