Mleczko z głębi lodówki
Wszystko
Najnowsze
Archiwum
konto usunięte via Android


Panie @konik_polanowy, wie Pan może czy da się jakoś otrzymać stare książki w ramach PacktPub Free Learning? Dopiero to odkryłem, a z wielu bym skorzystał ( ͡° ʖ̯ ͡°) Zwłaszcza tych do Pythona...
#packtpubfreelearning #python #datascience #packt #pytanie
#packtpubfreelearning #python #datascience #packt #pytanie



Dzisiaj Data Analysis with Python [Video] (Saturday, April 29, 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #datascience
odpowiedź
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #datascience
odpowiedź
![konik_polanowy - Dzisiaj Data Analysis with Python [Video] (Saturday, April 29, 2017)...](https://wykop.pl/cdn/c3201142/comment_NSm8RG3JDhqAQjHZ8dnPr6l9qrZvZZd1,w400.jpg)
źródło: comment_NSm8RG3JDhqAQjHZ8dnPr6l9qrZvZZd1.jpg
PobierzDzisiaj Python Machine Learning (September 2015)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #machinelearning #datascience
odpowiedź
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #machinelearning #datascience
odpowiedź

źródło: comment_OP86Dl1DwOdZNZPQVZMhq3cJZDDVln5k.jpg
Pobierz

Miruny! Polecicie jakieś fajne książki/e-booki do nauki #python - w szczególności w połączeniu z #analizadanych #datascience? Najlepiej, gdyby były w naszym ojczystym języku ( ͡° ͜ʖ ͡°)
#programowanie
#programowanie

@plackojad: ja Ci polecam książkę "Jak przestać być rodzynkarzem - autor: Lubię Sernik"
konto usunięte via iOS
W jaki sposob mozna okreslic, w jaki sposob podzielic watki, by osiagnac najbardziej optymalne rozwiazanie?
Np jak w Apache Sparku podzielic executory by aplikacje smigaly najbardziej i zaosby byly najlepiej wykorzystywane?
#programowanie #python #apachespark #datascience
Np jak w Apache Sparku podzielic executory by aplikacje smigaly najbardziej i zaosby byly najlepiej wykorzystywane?
#programowanie #python #apachespark #datascience

@przepyszna_frytka: odpowiedź jest oczywiście: to zależy. A zależy od charakteru pracy wykonywanej przez te wątki. Jeśli są to wątki CPU bound, nie ma sensu tworzyć ich więcej, niż masz dostępnych rdzeni
konto usunięte via iOS
@przepyszna_frytka: większa połowa najbardziej optymalnego rozwiązania przy cofaniu sie do tylu
Jak być na bieżąco z trendami w analityce danych? Rozmawiamy z Elitmind

Zaawansowana analityka danych to jedna z najprężniej rozwijających się gałęzi IT. Wciąż pojawiają się nowe rozwiązania i technologie, firmy masowo migrują dane i systemy do chmury, a zapotrzebowanie rynku na specjalistów Business Intelligence i Data Science rośnie z roku na rok. Jak być...
z- 0
- #
- #
- #
- #
- #
Dzisiaj Machine Learning Algorithms (July 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #datascience #machinelearning
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #datascience #machinelearning

źródło: comment_hFuqsO2cWg4m2bZ6gkITdkSfT2QyctjN.jpg
PobierzWołam zainteresowanych (235) z listy Packt Pub Free
Możesz zapisać/wypisać się klikając na nazwę listy.
Sponsor: Grupa Facebookowa z promocjami z chińskich sklepów
Masz problem z działaniem listy? A może pytanie? Pisz do IrvinTalvanen
Możesz zapisać/wypisać się klikając na nazwę listy.
Sponsor: Grupa Facebookowa z promocjami z chińskich sklepów
Masz problem z działaniem listy? A może pytanie? Pisz do IrvinTalvanen

@konik_polanowy dzięki! Nie znałem tej stronki. Świetna sprawa z tymi darmowymi książkami!

#datascience
#python
Jeśli chcę sobie zacząć robić portfolio to czy ma to znaczenie na jakich danych pracuję? Czy jednak większe znaczenie ma jakość tej analizy?
#python
Jeśli chcę sobie zacząć robić portfolio to czy ma to znaczenie na jakich danych pracuję? Czy jednak większe znaczenie ma jakość tej analizy?

Treść przeznaczona dla osób powyżej 18 roku życia...
@IsambardKingdomBrunel: Standardem w paperach / pracach naukowych wszelkiego rodzaju są zbiory z UCL Machine Learning repository: https://archive.ics.uci.edu/ml/index.php
Są tam standardy (iris, mtcars) ale znajdziesz też większe zbiory albo dotyczące innych zagadnień. Przy większości zobaczysz też co napisali w oparciu o ten konkretny zbiór.
Co do robienia do portfolio - dane są moim zdaniem średnio istotne, lepiej pokazać znajomość metod. I też istotne - rozumiem przez to nieco więcej niż randomforest na wszystkich
Są tam standardy (iris, mtcars) ale znajdziesz też większe zbiory albo dotyczące innych zagadnień. Przy większości zobaczysz też co napisali w oparciu o ten konkretny zbiór.
Co do robienia do portfolio - dane są moim zdaniem średnio istotne, lepiej pokazać znajomość metod. I też istotne - rozumiem przez to nieco więcej niż randomforest na wszystkich

Hej, chciałbym zrobić fajny prgoram do analizy danych kod który przetwarza dane i wizualizuje je (w matplotlib) już stworzyłem teraz się zastanawiam nad GUI odpowiednim do tego żeby fajnie wykresy mi wygenerował i dynamicznie je zmieniał,
- czy ktoś takie coś robił i mogłby mi podpowiedzieć które GUI do tego poleca ?
- jeśli nie robiłeś nic co się ociera o taki temat ale korzystałeś z jakiegoś GUI i oprócz dokumentacji korzystałeś
- czy ktoś takie coś robił i mogłby mi podpowiedzieć które GUI do tego poleca ?
- jeśli nie robiłeś nic co się ociera o taki temat ale korzystałeś z jakiegoś GUI i oprócz dokumentacji korzystałeś

@mozeskomentuje: może spróbuj dash from plotly

@mozeskomentuje ja robię front webowy. Do wykresów polecam vis.js
Założyłem tutaj konto by poprosić Was (a myślę że tacy specjaliści i tutaj są) o wskazówki odnośnie rozwoju zawodowego. Obecnie kończę studia, które nie są techniczne (ani ekonomia ani nic z tych rzeczy) chociaż chciałbym iść w kierunku data analysis/data science.
Mam problem drobny bo nie wiem dokładnie od czego zacząć. W ogłoszeniach o pracę często widać że wymagane jest wykształcenie kierunkowe (choć też jest tak, że jest ono określane jako preferowane).
Moje pytanie
Mam problem drobny bo nie wiem dokładnie od czego zacząć. W ogłoszeniach o pracę często widać że wymagane jest wykształcenie kierunkowe (choć też jest tak, że jest ono określane jako preferowane).
Moje pytanie
@Analitykzbozejlaski1_-: Data science to przede wszystkim umiejętność myślenia i rozwiązywania problemów. Tu nie chodzi o opanowanie narzędzi. Jeśli uważasz, że zostaniesz data scientist bo potrafisz kodować w SQL to jesteś w błędzie tak samo jeśli uważałbałbyś, że umiejętność operowania skalpelem uczyni z ciebie chirurga. Bo nie chodzi o narzędzia, a o umiejętność ich wykorzystana. Dlatego właśnie w ofertach pracy często wymagane jest ukończenie odpowiednich studiów.
Dalej. Chcesz zostać data analyst,
Dalej. Chcesz zostać data analyst,
@Miszka_Fisznan: Jakieś książki z tego zakresu konkretne polecasz? (Wstęp do matematyki, prawdopodobieństwo, statystyka etc).
No studiowałem bezpieczeństwo na WAT, teraz kończę na UW. Na WAT miałem przedmiot wstęp do matematyki, statystyka i probabilistyka, prognozowanie, (nawet miałem bezpieczeństwo sieci teleinformatycznych). Generalnie nie szło mi źle, zazwyczaj kończyło się na ocenach 4-5 gdzie niektórzy chyba do dziś jeszcze się p------ą z niektórymi z przedmiotów (bo humanistyczny kierunek to wiadomo jak najdalej od
No studiowałem bezpieczeństwo na WAT, teraz kończę na UW. Na WAT miałem przedmiot wstęp do matematyki, statystyka i probabilistyka, prognozowanie, (nawet miałem bezpieczeństwo sieci teleinformatycznych). Generalnie nie szło mi źle, zazwyczaj kończyło się na ocenach 4-5 gdzie niektórzy chyba do dziś jeszcze się p------ą z niektórymi z przedmiotów (bo humanistyczny kierunek to wiadomo jak najdalej od

Zostać docenianym specjalistą w obszarze, który rozwija się w zawrotnym tempie - z Data Science to możliwe
https://bulldogjob.pl/news/516-zarzadzanie-data-science-czyli-jak-zostac-cenionym-specjalista
#programowanie #technologia #kariera #pracait #datascience #bigdata #nauka
https://bulldogjob.pl/news/516-zarzadzanie-data-science-czyli-jak-zostac-cenionym-specjalista
#programowanie #technologia #kariera #pracait #datascience #bigdata #nauka

źródło: comment_4DT3zk7mmtoYqyls5aHKrSnqnHNKaar4.jpg
PobierzDzisiaj Machine Learning for OpenCV (July 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #machinelearning #opencv #datascience
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #machinelearning #opencv #datascience

źródło: comment_ZRGw6WsncOC025CFFha8xyhtaSGE5QYj.jpg
Pobierz
konto usunięte via iOS
Komentarz usunięty przez autora


Hey, czy są jakieś Polskie datasety z rasistowskimi komentarzami?
#datascience #machinelearning #deeplearning
#datascience #machinelearning #deeplearning

@gstark: vikop
konto usunięte via iOS
konto usunięte via iOS
@Avitus: jak nie zapomne to ok

@przepyszna_frytka: ja się do tej pory nie spotkałem. Jedyne co wydaje mi się może być namiastką to przerobienie notebooków na python'a przy pomocy https://github.com/minodes/pynb i testowanie pytest'em albo tox'em
Ale jak znajdziesz coś lepszego to wołaj :)
Ale jak znajdziesz coś lepszego to wołaj :)
Wie ktoś czy można wyświetlić wykres 2d z wykresu 3d w matplotlib?
Wygenerowałem wykres 3d (3D wireframe) i powiedzmy że zakres osi z jest równy 100, chciałbym podejrzeć wykres osi x i y w pkt 55 z.
Za każdą podpowiedź artykuł będę bardzo wdzięczny
#python #programowanie #naukaprogramowania #datascience #analizadanych
Wygenerowałem wykres 3d (3D wireframe) i powiedzmy że zakres osi z jest równy 100, chciałbym podejrzeć wykres osi x i y w pkt 55 z.
Za każdą podpowiedź artykuł będę bardzo wdzięczny
#python #programowanie #naukaprogramowania #datascience #analizadanych
@benedek: nie mam problemu z wygenerowaniem wykresu w punkcie tylko myślałem zeby wygenerować wykres 3 d i później wpisywać np wykres(z=4) i cyk wykres, ale jak sobie myślę to zrobię to w klasie i jako metodę wygenerowanie 3d później podgląd w punktach - co o ty myślisz?
I jeszcze pytanko czy da sie zrobić taki dynamiczny podgląd (jakby pokaz slajdów wykresów 2d) - jakby wygenerować suwak na którym będą całkowite
I jeszcze pytanko czy da sie zrobić taki dynamiczny podgląd (jakby pokaz slajdów wykresów 2d) - jakby wygenerować suwak na którym będą całkowite

chodzi o coś takiego? - wykres izometrii?
link
link

Hej #machinelearning i #datascience. Ostatnio po głowie chodził mi problem największego możliwego wpisanego okręgu w jakiś obszar zdefiniowany przez punkty na płaszczyźnie. Okazało się, że całkiem sprytnie można to rozwiązać za pomocą diagramów Woronoja. Jakby ktoś był zainteresowany, to zapraszam do artykułu:
https://www.jakbadacdane.pl/jakosc-powietrza-w-polsce-3-gdzie-brakuje-nam-czujnikow/
#jakbadacdane
https://www.jakbadacdane.pl/jakosc-powietrza-w-polsce-3-gdzie-brakuje-nam-czujnikow/
#jakbadacdane
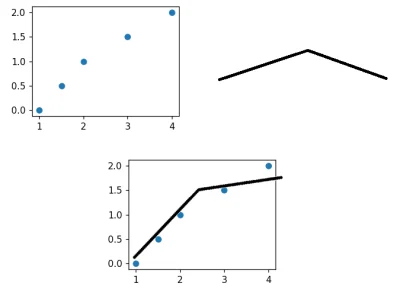
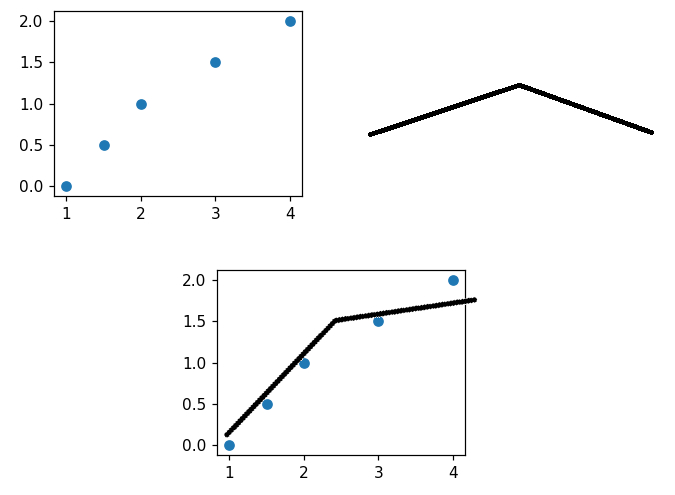
Czy ktoś wstawiał linie o określonym kształcie "między" punkty tak aby jak najbardziej wpasować linie w punkty (zdjęcie poniżej) i później z tego określił pole powierzchni między linia zbudowaną na punktach a tą która określoną która wstawiamy?
Za każdą poradę, artykuł będę wdzięczny
#naukaprogramowania #matplotlib #python #programowanie #datascience #analizadanych
Za każdą poradę, artykuł będę wdzięczny
#naukaprogramowania #matplotlib #python #programowanie #datascience #analizadanych
źródło: comment_h2ZLA3oFnBhy4IiDT96JK0t47cwCGNXz.jpg
Pobierz
@mozeskomentuje: Uogólnione modele liniowe powinny załatwić sprawę. Można też wykonać dopasowanie oparte np. na metodzie największej wiarygodności i skorzystać z kryterium informacyjnego (Bayesa-Schwartza albo Akaikego). Pole powierzchni powinna załatwić różnica dwóch pól powierzchni między prostą (krzywą) wpasowaną, a osią odciętych.
Po co Ci to w ogóle potrzebne? Dopasowujesz rozkład?
Po co Ci to w ogóle potrzebne? Dopasowujesz rozkład?
@mozeskomentuje: coś podobnego to: regresja liniowa


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Czy w data science przydaje się docker i jeśli tak to do czego?