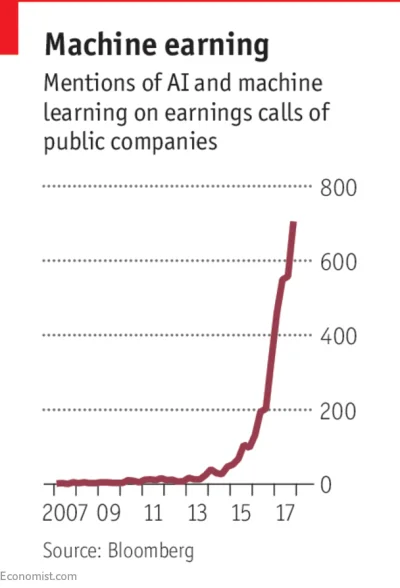
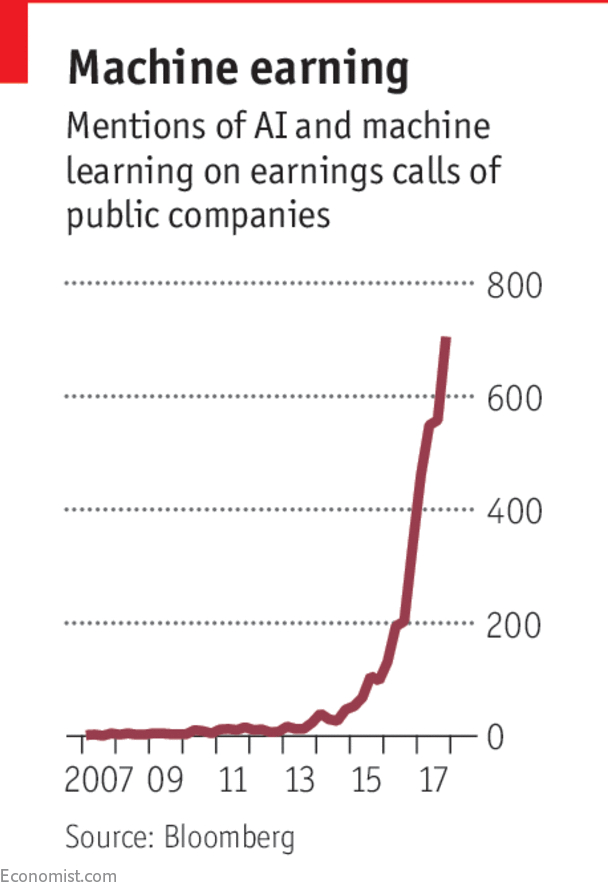
**Wykres: Ile razy "sztuczna inteligencja" była wymieniana przez prezesów spółek giełdowych w USA podczas "*earning calls"
Obserwuj #infog** - codziennie ciekawa infografika/wykres/mapka (społeczeństwo, gospodarka, technologia)
* earning calls to konferencje prezesów/zarządów z inwestorami, analitykami i mediami omawiające wyniki finansowe spółki w danym okresie (badano słowa/frazy: AI, machine learning, deep learning, neural network, computer vision, NLP)
#sztucznainteligencja #machinelearning #deeplearning #technologia #gospodarka
Obserwuj #infog** - codziennie ciekawa infografika/wykres/mapka (społeczeństwo, gospodarka, technologia)
* earning calls to konferencje prezesów/zarządów z inwestorami, analitykami i mediami omawiające wyniki finansowe spółki w danym okresie (badano słowa/frazy: AI, machine learning, deep learning, neural network, computer vision, NLP)
#sztucznainteligencja #machinelearning #deeplearning #technologia #gospodarka



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #datascience #machinelearning
źródło: comment_6HIYqspHlEdryydGiZqUegTDT8sKCiVI.jpg
Pobierz