Czy zna ktoś wartościowe podcasty/wykłady odnośnie deep learningu? Im bardziej szczegółowo tym lepiej, matematyczny aspekt jest równie ważny, fajnie też jakby była praktyka oparta na tensorflow. Póki co tylko u Lex`a Friedman i DeepMind znalazłem coś wartego uwagi, a nie mam siły przekopywać się przez kolejnych gości, którzy nie wiedzą o czym mówią ¯\_(ツ)_/¯ #ai #programowanie #sztucznainteligencja #deeplearning #machinelearning
Wszystko
Najnowsze
Archiwum
konto usunięte via iOS
https://course.fast.ai tu masz bardziej od strony praktycznej
Sztuczna inteligencja zabrała się za tworzenie nowych świątecznych hitów

Zespół ze Sztokholmu odpowiedzialny za ten projekt zapoznał AI ze znanymi bożonarodzeniowymi melodiami w formacie MIDI, trenując je i dając jakiś punkt wyjścia, a następnie zostawił same sobie.
z- 0
- #
- #
- #
- #
- #
- #

Czy to jest idealny #servermasterrace do #grafikakomputerowa i #machinelearning?
https://allegro.pl/dl360e-gen8-g8-2x-e5-2450l-48gb-ddr3-4-x-kieszen-i7657418168.html
Co prawda będzie trzeba wsadzić jakieś GPU.
Może ten serwer ma większą moc?
https://allegro.pl/serwer-hp-proliant-dl785-g5-8xqc-2-7ghz-64gb-6xpsu-i7583993931.html - może i są do niego mocniejsze procesory za niewielkie
https://allegro.pl/dl360e-gen8-g8-2x-e5-2450l-48gb-ddr3-4-x-kieszen-i7657418168.html
Co prawda będzie trzeba wsadzić jakieś GPU.
Może ten serwer ma większą moc?
https://allegro.pl/serwer-hp-proliant-dl785-g5-8xqc-2-7ghz-64gb-6xpsu-i7583993931.html - może i są do niego mocniejsze procesory za niewielkie

@wytrzzeszcz: ten 1u



Ahoj #datascience i #machinelearning. Wy to pewnie mnożycie macierze w bazach danych i inne cuda robicie. Ale może jest wśród was #newbie który jeszcze nie miał do czynienia z bazami danych. I właśnie z myślą o osobach początkujących napisałem artykuł w którym dzielę się moimi przemyśleniami na temat używania baz danych w projektach data science. Od razu ostrzegam, że temat jest na poziomie bardzo początkującym.
@ja_tu_czytam: Nie obrażam się ;). I mam pewien pomysł jak to ugryźć, ale jeszcze nie przetestowany - użyć modułu dask (https://dask.org/).
W samym artykule też piszę o tym, że możemy w ogóle nie zbudować ramki danych bo zabraknie nam pamięci ( ͡° ͜ʖ ͡°).
W sumie to jest to pomysł na artykuł na przyszłość. Może faktycznie w takiej sytuacji polegnę. Ale i tak będzie o
W samym artykule też piszę o tym, że możemy w ogóle nie zbudować ramki danych bo zabraknie nam pamięci ( ͡° ͜ʖ ͡°).
W sumie to jest to pomysł na artykuł na przyszłość. Może faktycznie w takiej sytuacji polegnę. Ale i tak będzie o

@Avitus: czekam na kontynuację ^^
Kupiłeś siekierę? #allegro wie co jeszcze może Ci się przydać (╯°□°)╯︵ ┻━┻ #machinelearning #profilowanie #czarnyhumor #wtf #heheszki
źródło: comment_ej3u8U8yv4eodHJutkN2RzHvNqHxYCHv.jpg
Pobierz
Treść przeznaczona dla osób powyżej 18 roku życia...

@drakkar: to może jeszcze... tak w wersji glam?
--> https://allegro.pl/prawdziwy-karambit-cs-go-noz-neck-fade-pazur-n062m-i6818375929.html
--> https://allegro.pl/prawdziwy-karambit-cs-go-noz-neck-fade-pazur-n062m-i6818375929.html

źródło: comment_CVFlhtm05pPCoOf4H1RQW0aHdWT0zbPq.jpg
PobierzDzisiaj Python Machine Learning (September 2015)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #machinelearning #datascience
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #machinelearning #datascience

źródło: comment_5tnvYV5cKCXxB597Itqi9fsbQGJvq5SM.jpg
Pobierzu mnie coś stronka szwankuje, nie pokazuje dzisiejszej pozycji ani przycisku akceptacji oferty

@uhu8: Pozmieniali coś i trzeba wyłączyć blokery reklam.
Sztuczna Inteligencja weszła na nowy poziom w tworzeniu ludzkich twarzy

Nowy artykuł naukowy badaczy Nvidia robi furorę wśród specjalistów machine learning. Ludzkie twarze stworzone przez ich algorytmy nigdy nie były tak realne. [eng]
z- 15
- #
- #
- #
- #
- #

Pozwolę sobie rozreklamować na kilku tagach znalezisko ze statystykami wykopu dodane przez @lemur_78 bo warto to zobaczyć.
https://www.wykop.pl/link/4690931/analiza-glownej-strony-wykop-pl/
#wy #datascience #programowanie #programista15k i może ktoś z #machinelearning skusi się na wykorzystanie seta
https://www.wykop.pl/link/4690931/analiza-glownej-strony-wykop-pl/
#wy #datascience #programowanie #programista15k i może ktoś z #machinelearning skusi się na wykorzystanie seta
@Waldemar_Morawiec: Stary dobry LeMUr :)
Ahoj #machinelearning i #datascience!. Czy są tutaj osoby początkujące? Specjalnie z myślą o was napisałem artykuł, w którym wypisuję i omawiam elementy projektu machine learning, które warto sobie przemyśleć i wybrać jeszcze przed rozpoczęciem pracy. Idea jest taka, że dzięki podjęciu tych decyzji, nawet osoba początkująca będzie miała szansę doprowadzić taki projekt do końca. Miłej lektury:
https://www.jakbadacdane.pl/jak-zaczac-dzialac-w-uczeniu-maszynowym/
#jakbadacdane
https://www.jakbadacdane.pl/jak-zaczac-dzialac-w-uczeniu-maszynowym/
#jakbadacdane

Hej mirki,
Chciałbym zbadać wpływ różnorodności regresorów użytych w baggingu na jakość uzyskanych wyników. Różność chciałem badać za pomocą miary chi square jednak teraz tak się zastanawiam bo regresory w baggingu zasilane są zbiorami danych stworzonymi na podstawiawie zbioru treningowego poprzez losowanie ze zwracaniem. W chi square obliczamy różnicę między poszczególnymi instancjami danych konkretnych par regresorów to na logikę regresory musiałyby korzystać z takiego samego zbioru danych bo jaki jest sens obliczania
Chciałbym zbadać wpływ różnorodności regresorów użytych w baggingu na jakość uzyskanych wyników. Różność chciałem badać za pomocą miary chi square jednak teraz tak się zastanawiam bo regresory w baggingu zasilane są zbiorami danych stworzonymi na podstawiawie zbioru treningowego poprzez losowanie ze zwracaniem. W chi square obliczamy różnicę między poszczególnymi instancjami danych konkretnych par regresorów to na logikę regresory musiałyby korzystać z takiego samego zbioru danych bo jaki jest sens obliczania

Tensorflow 2.0: models migration and new design #ai #machinelearning
https://pgaleone.eu/tensorflow/gan/2018/11/04/tensorflow-2-models-migration-and-new-design/
#interfacesmieci
https://pgaleone.eu/tensorflow/gan/2018/11/04/tensorflow-2-models-migration-and-new-design/
#interfacesmieci
Predykcyjny SYSTEM POLICYJNY oparty na SZTUCZNEJ INTELIGENCJI
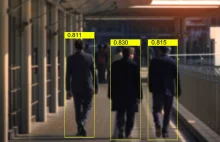
System będzie dostarczał informacji, które będą z kolei służyły wczesnym interwencjom i zapobieganiu działaniom potencjalnych przestępców. Raport mniejszości się kłania!
z- 38
- #
- #
- #
- #
- #
- #
Dzisiaj Machine Learning Algorithms (July 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #machinelearning #algorytmy #datascience
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #machinelearning #algorytmy #datascience

źródło: comment_JhjJQKCr0O1nPwnxQdy2mf6q1dsutQS4.jpg
Pobierz@konik_polanowy: czy byłby ktoś tak uprzejmy podesłać link do ściągnięcia tego pdf?

@Init0: zapętliło się
Moduły RISC-V z akceleratorem sieci neuronowych za 20 zł

Procesory z architekturą RISC-V stają się coraz popularniejsze i coraz tańsze. Otwarta licencja sprzyja eksperymentom i umożliwia stosunkowo łatwą integrację z najnowszymi rozwiązaniami. Firma Sipeed wypuszcza na rynek kolejny moduł z rozwiązaniem konkurencyjnym dla popularnych rdzeni...
z- 13
- #
- #
- #
- #
- #
- #
konto usunięte via iOS
W jakis sposob najlepiej napisac klase, ktora by dzialala z modelami #machinelearning ?
Czy mozna stworzyc klase, ktora by dziedziczyla po danym modelu, czy lepiej zadeklarowac w srodku klasy zmienna ktora by przechowywala taki model?
np
class Klasa(Model):
...
Czy mozna stworzyc klase, ktora by dziedziczyla po danym modelu, czy lepiej zadeklarowac w srodku klasy zmienna ktora by przechowywala taki model?
np
class Klasa(Model):
...
W jakis sposob najlepiej napisac klase, ktora by dzialala z modelami #machinelearning ?
@przepyszna_frytka: Pytanie na które nie da się jednoznacznie odpowiedzieć ;) .
A uniwersalna odpowiedź to :"to zależy, co ty chcesz z tym w ogóle
bo sam na razie nie wiem, jakie rozwiazanie bedzie najlepsze
@przepyszna_frytka:
No właśnie, bo najlepsze rozwiązanie to takie jakie sobie wymyślisz aby sensownie działało jako całość.
@przepyszna_frytka: > chce stworzyc „biblioteke” korzystajaca z scikit-opt by optymalizowac parametry modeli, czyli ta klasa, by posiadala metody optymalizujace parametry, zapisujace
Hej.
Tym razem przygotowałem krótki artykuł o module SHAP, który pozwala podejrzeć, dlaczego model dokonał takiej, a nie innej predykcji dla konkretnej obserwacji:
https://www.jakbadacdane.pl/co-to-jest-shapley-additive-explanations-shap/
Miłego czytania.
Tym razem przygotowałem krótki artykuł o module SHAP, który pozwala podejrzeć, dlaczego model dokonał takiej, a nie innej predykcji dla konkretnej obserwacji:
https://www.jakbadacdane.pl/co-to-jest-shapley-additive-explanations-shap/
Miłego czytania.

Zdalnie.io #31
Kliknij tutaj lub obserwuj #zdalnieio, aby otrzymywać cotygodniową porcję ofert pracy zdalnej :)
Frontend/Javascript
React Developer (Appchance) 7 000 - 12 000 PLN -
Kliknij tutaj lub obserwuj #zdalnieio, aby otrzymywać cotygodniową porcję ofert pracy zdalnej :)
Frontend/Javascript
React Developer (Appchance) 7 000 - 12 000 PLN -

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
plusuj ten komentarz jeśli chcesz być wołany o nowych wydaniach #zdalnieio :)
Nvidia stworzyła pierwsze DEMO GRY, używając AI do generowania grafiki

To prosty symulator, ale może być początkiem rewolucji dla grafiki w przemyśle gamingowym.
z- 15
- #
- #
- #
- #
- #
- #
Próbuję obliczyć różnorodność pomiędzy dwoma regresorami. Znalazłem artykuł w którym opisana jest miara disagreement measure która jest rozszerzeniem miary Kunchevy dla klasyfikatorów. Nie bardzo rozumiem fragment o obliczaniu odchylenia standardowego. Czy mam obliczyć wartość odchylenia wartości wyestymowanej do rzeczywistej i podzielić to jakoś przez N przewidywań? Ktoś może coś doradzić?
źródło: comment_b0HZbftw0FWvwWGuzyeyqf5KGohdfiaV.jpg
PobierzNie potrafiłem sam sobie tego poukładać bardzo mi pomogłeś - jedno co dodam to, że muszę policzyć odchylenie dwukrotnie - dla pierwszego modelu z wartości przewidywanych i dla drugiego modelu z wartości przewidywanych