
Hej Mireczki. Jak wygląda ścieżka kariery programisty Python? Rok temu z ciekawości poklepałem w nim trochę kodu i znam składnię. Wiem że mam za mało wiedzy, żeby zostać juniorem, ale od czego zacząć? Każdy kurs na Udemy uczy tylko składni, albo jakiejś biblioteki. Jestem automatykiem z wykształcenia i lubię programować. Programowałem już sterowniki PLC i jestem w trakcie studiów, ale niestety straciłem pracę. Myślę nad tym żeby się przebranżowić. Nie zależy mi
Wszystko
Najnowsze
Archiwum

Komentarz usunięty przez moderatora
Komentarz usunięty przez moderatora

#programowanie #python #machinelearning
Mirki, zacznę od was bo nie wiem gdzie dalej się udać. Mam następujący problem.
Chciał bym wydajnie przerabiać zdjęcia na macierze. Robię sobie trochę kaggli ale w każdym mam dokładnie ten sam problem. Ładowanie dużych Data Setów zajmuje dużo czasu.
Zaimplementowałem multiprocessing - bardzo naiwnie bo nie bardzo się na tym znam, niby jest szybciej ale to nadal dużo poniżej możliwości mojego serwera. Dysk
Mirki, zacznę od was bo nie wiem gdzie dalej się udać. Mam następujący problem.
Chciał bym wydajnie przerabiać zdjęcia na macierze. Robię sobie trochę kaggli ale w każdym mam dokładnie ten sam problem. Ładowanie dużych Data Setów zajmuje dużo czasu.
Zaimplementowałem multiprocessing - bardzo naiwnie bo nie bardzo się na tym znam, niby jest szybciej ale to nadal dużo poniżej możliwości mojego serwera. Dysk
źródło: comment_1595257108OFkIo0jBDZR8zYoFTiyu4x.jpg
Pobierz
@zboinek: dlaczego nie używasz Pillow/PIL?
@vornikor: Właśnie natknąłem się na taką oto funkcje- pic rel. Nowa implementacja w tensorflow. Widać jest dokładnie tak jak myślę czyli to ładowanie jest zrealizowane zupełnie inaczej. Tutaj odczyt z dysku jest żaden, czas trwania koło 2s, co znaczy, że wcale nie tworzy tego od razu i trzyma w ramie tylko zacznie mielić dopiero jak będzie na to czas. Batch_size duży ale to tylko dla testu czy może czasami nie

źródło: comment_15952860963WEcAQTYjli2ffKDDj8Q6V.jpg
Pobierz
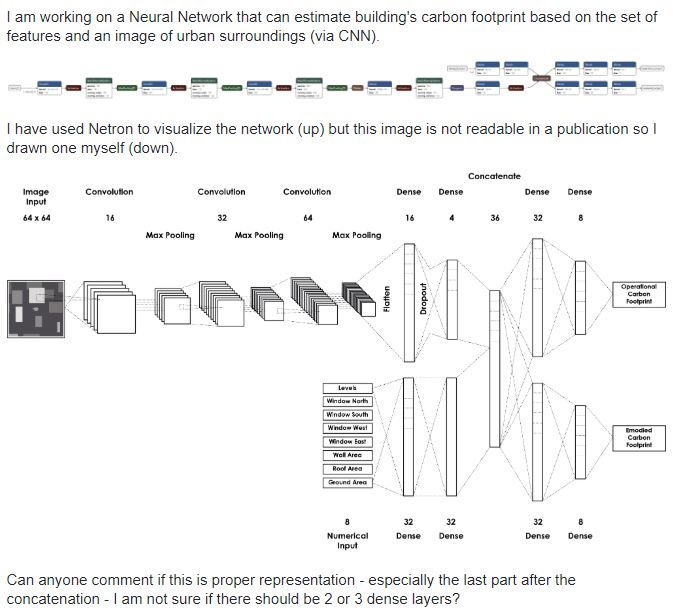
Czy ktoś może ocenić czy dobrze zilustrowałem sieć?
https://datascience.stackexchange.com/questions/78026/can-anyone-verify-my-nn-diagram-if-it-is-properly-drawn
#python #uczeniemaszynowe #ai #sztucznainteligencja #machinelearning #keras
https://datascience.stackexchange.com/questions/78026/can-anyone-verify-my-nn-diagram-if-it-is-properly-drawn
#python #uczeniemaszynowe #ai #sztucznainteligencja #machinelearning #keras
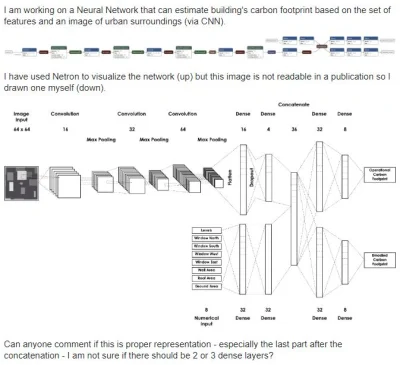
źródło: comment_15952513468BShUCAjxyBYaVbkLUJvbx.jpg
Pobierz@nilfheimsan: W warstwach Conv i Pool powinieneś podać kernel size oraz ewentualnie stride i padding
@nilfheimsan: wygląda poprawnie wszystko. brakuje rozmiaru wyjścia na końcu sieci. w sumie ten górny obrazek jest bardziej dla mnie czytelny, tylko nie ma na nim pokazanych aktywacji warstw liniowych

mamy tu jakichs magikow #machinelearning ?
ktos mi podpowie dlaczego dal jednego konca sieci (materialoutput) wsyzstko ładnie idzie do bledu 1% a dla drugiego wyjscia (operationoutput) mam ciagle blad ponad 100%?
gdzie jest blad?
* pierwszy raz robie siec z dwoma koncami
#python #uczeniemaszynowe #ai #sztucznainteligencja
ktos mi podpowie dlaczego dal jednego konca sieci (materialoutput) wsyzstko ładnie idzie do bledu 1% a dla drugiego wyjscia (operationoutput) mam ciagle blad ponad 100%?
gdzie jest blad?
* pierwszy raz robie siec z dwoma koncami
#python #uczeniemaszynowe #ai #sztucznainteligencja

źródło: comment_1594974938MNzqMmqlVnbiUHSkpsYil1.jpg
Pobierz@Poczmistrz_z_Tczewa: chyba nie, jak?
@keczub_: @Poczmistrz_z_Tczewa: wyglada chyba na to ze architektura jest ok bo wlasnie znalazlem w danych wejsciowych pojedyncza linijke ktora ma nierealne liczby. wlasnie to poprawiam i chyba zadziala
nauczka na przyszlosc zawsze sprawdzaj dane wejsciowe (sprawdzilem ale na oko, a nie skryptem, a w 3000 linijek sie zachowal pojedynczy przypadek)
nauczka na przyszlosc zawsze sprawdzaj dane wejsciowe (sprawdzilem ale na oko, a nie skryptem, a w 3000 linijek sie zachowal pojedynczy przypadek)
Jest jakaś możliwość obliczenia właściwie to uproszczenia wyniku poniższej całki :
from sympy import *
x = Symbol('x')
f = Function
f = 1 / (exp(x) + exp(-x))
from sympy import *
x = Symbol('x')
f = Function
f = 1 / (exp(x) + exp(-x))

stawiam sobie zdalny serwerek do #deeplearning i #machinelearning i ogólnie #sztucznainteligencja. Chciałbym mu nadać jakąś fajną nazwę (tzn hostname żeby być precyzyjnym). Proszę o jakies ciekawe pomysły na nazwę, związaną z powyższymi zagadnieniami :> skynet już jest na liście ( ͡° ͜ʖ ͡°)
#pytaniedoeksperta #humorinformatykow
#pytaniedoeksperta #humorinformatykow


Mirki, polecicie jakieś ciekawe książki, kursy, nagrania systematyzujące wiedzę ze #statystyka #machinelearning #datamining ?

@xan-kreigor: ja tam lubiem
konto usunięte via Android
@xan-kreigor Teraz zostanie z nami na zawsze. W sumie dobry motyw, jedziesz na urlop a filmiki dalej się robią z twoją gębą

Tak jak obiecałem, podjąłem się karkołomnego zadania zmorphowania dwóch skrajnie różnych postaci za pomocą technologii deep fake. Poniżej efekt scalenia ze sobą Laleczki Chucky i Daenerys.
https://www.wykop.pl/link/5589079/morphujemy-daenerys-z-laleczka-chucky-wykopowy-projekt-deep-fake/
#deepwykop - już 461 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
#machinelearning #ciekawostki #technologia #faceswap #graotron
https://www.wykop.pl/link/5589079/morphujemy-daenerys-z-laleczka-chucky-wykopowy-projekt-deep-fake/
#deepwykop - już 461 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
#machinelearning #ciekawostki #technologia #faceswap #graotron

Morphujemy Daenerys z Laleczką Chucky [wykopowy projekt deep fake]
![Morphujemy Daenerys z Laleczką Chucky [wykopowy projekt deep fake]](https://wykop.pl/cdn/c3397993/link_1594023481Mvw47mdcCcio0RpkzO7aPe,w220h142.jpg)
Dzisiaj nietypowe podejście do Deep Fejka. Ponieważ możliwe jest już w miarę płynne morphowanie dwóch skrajnie różnych postaci, pozwoliłem sobie podjąć karkołomne zadanie scalić Chuckiego z Khaleesi.
z- 9
- #
- #
- #
- #
- #
- #
MIT usunęło zbiór 80 milionów zdjęć, bo były wśród nich rasistowskie obelgi

Takie zbiory wykorzystywane są do Machine Learningu. W internecie nic nie ginie i zbiór danych nadal można pobrać z Archive.org i torrentów.
z- 27
- #
- #
- #
- #
- #
Bylibyście zainteresowani morphem dwóch postaci, czy jedynie taka formuła jaka była dotąd w projekcie?
#deepwykop - już 456 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
#machinelearning #technologia #deepfake #faceswap
#deepwykop - już 456 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
#machinelearning #technologia #deepfake #faceswap

źródło: comment_15938454183mbD8eJFYCD3vRUH6DrDFY.jpg
Pobierz
Jakie są metody do przewidywania wartości etykiety Y, ale jako wartość ciągła?
czyli nie taki jak KNN, że dodaje mi jedną z przewidywanych etykiet z procesu uczenia, tylko szacuje np. wagę albo rozmiar próbki.
CNN na pewno tak może, ale klasycznie też będzie wartość dyskretna, help
Przyszło
czyli nie taki jak KNN, że dodaje mi jedną z przewidywanych etykiet z procesu uczenia, tylko szacuje np. wagę albo rozmiar próbki.
CNN na pewno tak może, ale klasycznie też będzie wartość dyskretna, help
Przyszło

@k-NN: nie jestem pewien czy rozumiem o co ci chodzi, ale chyba pojęcia których szukasz to regression i classification. Możesz użyć na przykład SVR albo sieci z jednym neuronem na wyjściu.
@k-NN: Chodzi Ci po prostu o regresję. Polecam na początek: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
Wyobrażacie sobie Henrego Cavilla w roli policjanta Johna McClane w Szklanej Pułapce? GAN, czyli generative adversarial network, to opcja w teorii miała mi pomóc "zepsuć" wysokiej jakości materiał źródłowy i dopasować do jakości filmu z lat 80tych. Czy się udało? Oceńcie sami
https://www.wykop.pl/link/5578905/gdyby-w-szklanej-pulapce-gral-henry-cavill-wykopowy-projekt-deep-fake/
#deepwykop - już 459 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
Poniżej
https://www.wykop.pl/link/5578905/gdyby-w-szklanej-pulapce-gral-henry-cavill-wykopowy-projekt-deep-fake/
#deepwykop - już 459 osób obserwuje Wykopowy Projekt Rozkminiania Technologii Deep Fake
Poniżej

Gdyby w Szklanej Pułapce grał Henry Cavill [wykopowy projekt deep fake]
![Gdyby w Szklanej Pułapce grał Henry Cavill [wykopowy projekt deep fake]](https://wykop.pl/cdn/c3397993/link_1593500523ttluYfVCR4dHfdmCpBraSt,w220h142.jpg)
W kolejnym etapie projektu na warsztat wziąłem GAN (generative adversarial network). Czy był w stanie odwzorować specyficzną teksturę w starym filmie z lat 80tych i zastosować podmiankę twarzy w dużej rozdzielczości? Więcej informacji nt. samego procesu w komentarzu.
z- 24
- #
- #
- #
- #
- #
- #

ciekawostka , jak zarabia sie na swiecie w branzy big data
#datascience #bigdata #machinelearning #zarobki
#datascience #bigdata #machinelearning #zarobki

źródło: comment_1593473692ur2jypFRpBK5SuwcXmZ6km.jpg
PobierzDzisiaj podejście do speed fejka, czyli możliwie jak najszybciej ukończonego procesu trainingu (który w skrajnych przypadkach może trwać nawet ponad 100 godzin). Poniżej owoc króciutkiego trainingu na bardzo niskim batchu, ale z użyciem wysokiej jakości ostrego źródła, i tej samej rozdzielczości lecz raczej rozmytego obrazu. Wyszło nawet nieźle biorąc pod uwagę, że sam proces uczenia się twarzy uczył się ok. 75% mniej niż normalnie. Mniej więcej tak wyglądałaby Margeary gdyby grał ją
Jeśli chcesz dopisać się do listy do wołania, plusuj ten komentarz.

źródło: comment_1593239500IKQ0DjtLp6QQ41plhw8Mm8.jpg
Pobierz
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
który w skrajnych przypadkach może trwać nawet ponad 100 godzin
@Rimfire: To ja marudze jak mam trenowac cos dluzej niz dzien.... ( ͡º ͜ʖ͡º) Nie rujnuja cie rachunki? XD
What happens when AI stops playing games?

"Artificial intelligence has been on a seemingly unstoppable march". Zmierzamy ku scenariuszowi z Matrixa? A może to już się dzieje ( ͡° ͜ʖ ͡°)
z- 2
- #
- #
- #
- #
- #
- #
Obecnie nie mam zamiaru spamować Wykopaliska nowymi filmikami, a na Mirko nie mogę wrzucać embedów bo Michau znowu coś zepsuł. To znaczy mogę wrzucać ale one się nie wyświetlają i trzeba otwierać w nowym oknie. Obecnie robię upgrade'y i dopieszczam część starych modeli bo wyszła nowa rewolucyjna architektura i efekty są dość spektakularne. No nic, jakby co zapraszam na mój kanał, tam są już pierwsze owoce
źródło: comment_1595405885hnaNGHgVuWvDWo7oh0jysI.jpg
Pobierz