Tak z ciekawości, w wąsko pojętej inżynierii danych (czyli nie data science, nie analiza danych, tylko Big Data, ETLe, Sparki, Kafki, streamowanie itp.) też jest lipa z ofertami? Pytam, bo wypadłem ze śledzenia rynku pracy, stawki w zasadzie są te same co były, większość ofert jak było, tak jest remote, więc wydaje się, że jest dużo lepiej niż w reszcie specjalizacji. Nawet wydaje mi się, że jest więcej ofert na entry-level, czego
Wszystko
Najnowsze
Archiwum

też jest lipa z ofertami?
@blehblehbleh: Jest ciut gorzej niż było jeszcze rok temu. Ostatnio zmieniałem robotę i na trzy rozmowy miałem dwie oferty a dwie kolejne rozmowy urwały się w trakcie z powodu znalezienia już kogoś innego. Finalnie 2/5. Rok temu było 3-4/5

@blehblehbleh nie, nie ma. Jest wręcz wysyp.

✨️ Obserwuj #mirkoanonim
Mirki, wybieram się w tym roku na studia podyplomowe big data. Zastanawiam się nad Politechniką Warszawską i SGH. Macie jakieś opinie na temat tych studiów? Które byście wybrali? Który program wydaje wam się lepszy?
1. https://www.sgh.waw.pl/studia-podyplomowe-i-mba/transformacja-cyfrowa/studia-podyplomowe-inzynieria-danych-big-data
2. https://ds.ii.pw.edu.pl/bigdata.html
#bigdata #korposwiat #programista15k #programowanie
Mirki, wybieram się w tym roku na studia podyplomowe big data. Zastanawiam się nad Politechniką Warszawską i SGH. Macie jakieś opinie na temat tych studiów? Które byście wybrali? Który program wydaje wam się lepszy?
1. https://www.sgh.waw.pl/studia-podyplomowe-i-mba/transformacja-cyfrowa/studia-podyplomowe-inzynieria-danych-big-data
2. https://ds.ii.pw.edu.pl/bigdata.html
#bigdata #korposwiat #programista15k #programowanie


@mirko_anonim: przejrzałem program tych "studiów" to większość szkoleń do certyfikatów seniorskich ma ZNACZENIE ambitniejszy zakres
✨️ Obserwuj #mirkoanonim
Pracuje od kilku lat w #testowanieoprogramowania jednak widzę że ilość ofert na stanowiska testerskie jest coraz mniejsza.
Myśle o zmianie zmianie na #bigdata #analizadanych #datascience #businessintelligence bo ilość ofert w tym obszarze jest kilka razy większa niż na #qa.
Doświadczenie mam głównie jako tester manualny, znam podstawy pythona i js (używane do testów automatycznych).
Jaki
Pracuje od kilku lat w #testowanieoprogramowania jednak widzę że ilość ofert na stanowiska testerskie jest coraz mniejsza.
Myśle o zmianie zmianie na #bigdata #analizadanych #datascience #businessintelligence bo ilość ofert w tym obszarze jest kilka razy większa niż na #qa.
Doświadczenie mam głównie jako tester manualny, znam podstawy pythona i js (używane do testów automatycznych).
Jaki


źródło: 23-dns11-FINAL-1
PobierzWikiRank - ocena jakości i popularności Wikipedii
Serwis internetowy do automatycznej oceny jakości i popularności artykułów w różnych wersjach językowych Wikipedii.
z- 0
- #
- #
- #
- #
- #

Mam pytanie uzupełniające do mojego wczorajszego pytania o sortowanie.
Dataframy mi się sortują ładnie. Teraz pytanie - czy taki posortowany dataframe mogę zapisać jako posortowany parquet?
Bo zwykłe zapisane posortowanego df niestety nie daje oczekiwanego rezultatu i parquet (a potem external table z tego parqueta) nie są posortowane po tej kolumnie co dataframe.
Pewnie jest opcja, że się nie da, bo tabela to logiczne dane, a nie posortowany zestaw danych?
Dataframy mi się sortują ładnie. Teraz pytanie - czy taki posortowany dataframe mogę zapisać jako posortowany parquet?
Bo zwykłe zapisane posortowanego df niestety nie daje oczekiwanego rezultatu i parquet (a potem external table z tego parqueta) nie są posortowane po tej kolumnie co dataframe.
Pewnie jest opcja, że się nie da, bo tabela to logiczne dane, a nie posortowany zestaw danych?

@LucaJune Z tego co wiem to nie da się osiągnąć sortowania w parquet, ze względu na sposób w jaki zapisuje on dane (kolumny). Z reguly sortowanie musi odbyć się jeszcze raz po wczytaniu.
Jeśli twój DF jest dość mały, możesz spróbować zapisania go jako jedna partycja (df.coalesce(1)), wtedy sortowanie powinno być zachowane, ale tracisz obliczenia na wielu klastrach.
Jeśli twój DF jest dość mały, możesz spróbować zapisania go jako jedna partycja (df.coalesce(1)), wtedy sortowanie powinno być zachowane, ale tracisz obliczenia na wielu klastrach.

@LucaJune: @ch1nczyk Dokładnie, zapisując na plikach nie masz opcji zapisania "posortowanego", co najwyżej możesz używać takich metod jak clustering eg https://docs.databricks.com/en/delta/clustering.html czy partycjoniwanie.
Mam w Synapsie Analytics dataframe złożony z joinów z 10 innych dataframów, nic przesadnie skomplikowanego.
Ale chcę to posortować i .orderBy(col("nazwakolumny").desc()) mi nie działa.
Jako ciekawostka - w jednym notebooku mi to ładnie działa, a w innym nie.
Nie wywala błędu, tylko po prostu nie sortuje.
Ale chcę to posortować i .orderBy(col("nazwakolumny").desc()) mi nie działa.
Jako ciekawostka - w jednym notebooku mi to ładnie działa, a w innym nie.
Nie wywala błędu, tylko po prostu nie sortuje.

Naukowe źródła informacji w artykułach Wikipedii w różnych tematach i językach

Praca polskich naukowców została opublikowana w czasopiśmie "Procedia Computer Science" wydawnictwa Elsevier. W ramach pracy zostały przeanalizowane setki milionów przypisów artykułów Wikipedii z różnych wersji językowych w celu identyfikacji naukowych źródeł informacji.
z- 1
- #
- #
- #
- #
- #
- #
Wynajem mieszkań drożeje skokowo. Polska w światowej czołówce wzrostów czynszów
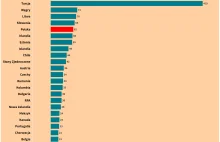
W ciągu ośmiu ostatnich lat czynsze w Polsce wzrosły tak bardzo, że znaleźliśmy się w ścisłe światowej czołówce pod tym względem. We wzroście kosztów wynajmu mieszkania wyprzedza nas tylko kilka krajów w zestawieniu 43 państw, dla których OECD zbiera dane.
z- 7
- #
- #
- #
- #
- #
- #
Algorytm Facebooka wykorzystuje wiedzę o ich lękach i słabościach użytkowników -

Facebook walczy o uwagę użytkowników, wykorzystując wiedzę o ich lękach i słabościach, a przyciski, które mają ograniczać wyświetlanie nie działają.
z- 67
- #
- #
- #
- #
- #
- #
Jak zacząć pozyskiwać właściwe dane z analityki cyfrowej
Rozpoczynanie rozumienia analityki cyfrowej może przypominać próbę czytania hieroglifów bez kamienia z Rosetty. Ale nie obawiaj się, drogi czytelniku! Przy odrobinie wskazówek i odrobinie dowcipu będziesz interpretować te tajemnicze liczby jak profesjonalista. Zatem zapnij pasy i zanurzmy s
z- 0
- #
????Odblokowanie mocy GPT: Ściągawka główna + 5jailbreak???? i Ściągawka CodeInterpreter GPT [Lite] ????
https://https://angonpl.gumroad.com/
W stale zmieniającym się krajobrazie sztucznej inteligencji jedną z najbardziej rewolucyjnych technologii, jaka się pojawiła, jest GPT (Generative Pre-trained Transformer) OpenAI. GPT okazał się przełomowy w różnych dziedzinach, od przetwarzania języka naturalnego po generowanie kreatywnych treści. Aby w pełni wykorzystać potencjał GPT, zarówno entuzjaści, jak i profesjonaliści sięgają po kompleksowe zasoby, takie jak ściągawki i przewodniki. W tym
https://https://angonpl.gumroad.com/
W stale zmieniającym się krajobrazie sztucznej inteligencji jedną z najbardziej rewolucyjnych technologii, jaka się pojawiła, jest GPT (Generative Pre-trained Transformer) OpenAI. GPT okazał się przełomowy w różnych dziedzinach, od przetwarzania języka naturalnego po generowanie kreatywnych treści. Aby w pełni wykorzystać potencjał GPT, zarówno entuzjaści, jak i profesjonaliści sięgają po kompleksowe zasoby, takie jak ściągawki i przewodniki. W tym

źródło: hackerser2
Pobierz

A dobra, co mi tam, skoro chłopaki dzisiaj taką nagonkę prowadzą to też dorzuce od siebie trzy grosze ( ͡° ͜ʖ ͡°)
#pracait #businessintelligence #dataengineering #bigdata
#pracait #businessintelligence #dataengineering #bigdata
źródło: inzynier danych
Pobierz@peoplearestrange: no wg mnie juniorom trudniej znaleźć teraz pracę

@peoplearestrange: też widziałem ten post, szkoda że reakcji nie wrzuciłeś. Kierunek i zwrot był jasny :-)
Hej, czy ktoś z was studiował albo zna osoby, które studiowały na studiach magisterskich po angielsku na SGH? Czy jest tam ciężej, lżej niż na polskich i na jakim poziomie jest angielski i zajęcia? #sgh #bigdata #studia #magisterka
@malebro: nie wątpię xd tylko ogólnie pytam czy różnią się poziomami
@benxz kilka przedmiotów brałem po angielsku, matematyczne - bez różnicy w poziomie, jak wiążesz przyszlosc z ekonometrią to polecam by liznąć jezyka specjalistycznego, jak nie to odradzam bo to dodatkowa przeszkoda w uczeniu się; reszta wg mnie trochę łatwiejsze, tj więcej zaliczania projektami czy prezentacjami. Ale to było w 2016, więc nie wiem, czy info aktualne

Statystyki YouTube są zadziwiające. Ciężko uwierzyć że działa tak sprawnie i są w stanie skalować tak ogromny ruch i objętość treści.
⚪️ W czerwcu 2022 roku na YouTube co minutę dodawano ponad 500 godzin materiału wideo. To oznacza, że co godzinę pojawiało się około 30 000 godzin nowej treści. Na dodatek to CDNy, więc wszystkie treści i serwery są w kilku kopiach.
⚪️ Codziennie oglądamy ponad 1 miliard godzin filmów na YouTube.
⚪️ W czerwcu 2022 roku na YouTube co minutę dodawano ponad 500 godzin materiału wideo. To oznacza, że co godzinę pojawiało się około 30 000 godzin nowej treści. Na dodatek to CDNy, więc wszystkie treści i serwery są w kilku kopiach.
⚪️ Codziennie oglądamy ponad 1 miliard godzin filmów na YouTube.

YouTube brought in $7.7 billion in advertising revenue in its second quarter, reversing the prior trends of a downturn.
@Jakie: Nieprawda. Od dawna YT jest rentowny i przynosi dochody. Nie wiem dlaczego ludzie wygadują bzdury, które im się wydają jako fakty. Bezsens... Wszystko możesz sprawdzić w kilka sekund, ale lepiej pisać jako pewniak coś co sobie wymyślasz i jedynie wprowadzasz ludzi w błąd. Taki komentarz ma ujemną wartość informacyjną. Pewnie
Porównywanie YouTube do np. Netflixa jest bardzo głupie. Może Netflix ma dużą oglądalność, ale tutaj istotne jest jedynie obsłużenie dużego uploadu. Samych treści na Netflixie jest strasznie malutko względem YouTube. Tyle co nic. Muszą obsłużyć jedynie duży ruch ale danych do przechowywania mają nieporównywalnie mniej.

Robię model profitowości kontraktów handlowych w #pracbaza i chciałbym podpiąć pod niego prosty model machine learning, który na podstawie wstępnej propozycji handlowca proponowałby zoptymalizowane parametry takiego kontraktu, tak aby dążyć do maksymalnej profitowości.
Coś w stylu, że tutaj damy trochę większy rabat, tutaj dla nas ciut większa prowizja, klient prawie nie zauważy, a dla nas to będzie znacząca różnica w profitowości takiego kontraktu.
1. Ile czasu realnie coś takiego mogłoby zająć?
Coś w stylu, że tutaj damy trochę większy rabat, tutaj dla nas ciut większa prowizja, klient prawie nie zauważy, a dla nas to będzie znacząca różnica w profitowości takiego kontraktu.
1. Ile czasu realnie coś takiego mogłoby zająć?

źródło: image
Pobierz
@MarteenVaanThomm: jak masz dużo danych i ich model nie jest raczej skomplikowany to sieci neuronowe mogą łatwo być overkillem - model użyj jaki chcesz, ale nie przesadzaj z jego wielkością. Nie wiem też co dokładnie chcesz osiągnąć i dlaczego nie można tego po prostu policzyć. Jeśli masz zbiór zatwierdzonych "optymalnych" kontraktów i chcesz włożyć nowy nieoptymalny kontrakt aby go poprawić to możesz tu zastosować maszynę Boltzmanna. Ewentualnie zastosować redukcję wymiarowości,
@Bejro: dzięki bardzo, sporo ciekawych rzeczy piszesz.
Jeśli chodzi o równanie do średniej to tutaj nie zda to egzaminu. Dlatego, że jeśli mamy parametr X (jakaś opłata_2 powiedzmy) dla klienta równa 100, a w modelu referencyjnym, tym najbardziej profitowym ten parametr dąży do 20, to równanie 100 do 20, czy nawet 50 nie ma sensu, bo klient na to nie pójdzie. Nie chcemy tutaj przerabiać każdej propozycji kontraktu pod jeden
Jeśli chodzi o równanie do średniej to tutaj nie zda to egzaminu. Dlatego, że jeśli mamy parametr X (jakaś opłata_2 powiedzmy) dla klienta równa 100, a w modelu referencyjnym, tym najbardziej profitowym ten parametr dąży do 20, to równanie 100 do 20, czy nawet 50 nie ma sensu, bo klient na to nie pójdzie. Nie chcemy tutaj przerabiać każdej propozycji kontraktu pod jeden

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cześć Mirki, polecicie jakiś kurs po angielsku do Pythona i Big Data? Uczyłem się mocno Node.js, ale chciałbym pobawić się Pythonem. Najfajniej jakiś kombajn z dużo liczbą godzin i dużą ilością materiału ( ͡° ͜ʖ ͡°)
#programownie #naukaprogramowania #it #python #bigdata
#programownie #naukaprogramowania #it #python #bigdata
Podręcznik Inkrementalny: Skuteczne Zarządzanie Projektem
Zarządzanie projektami to kluczowy element sukcesu w dzisiejszym złożonym i dynamicznym środowisku biznesowym. Jednym z podejść, które znalazło szerokie zastosowanie w zarządzaniu projektami, jest podejście inkrementalne. W tym artykule przyjrzymy się, czym dokładnie jest podręcznik ink
z- 1
- #
Data Science: Kluczowa Dziedzina Współczesnej Informatyki
In today's increasingly data-driven world, data science plays a key role in acquiring knowledge, making decisions and developing new technologies. It is an interdisciplinary field that combines mathematics, computer science, statistics and business fields to extract value from data. In this article,
z- 1
- #
Którą ścieżkę obecnie byś wybrał? Pod uwagę bierzemy work&life balance, perspektywa zarobków, łatwość znalezienia pracy na obecnym rynku, ciekawsze rzeczy, ilość stresu w pracy, próg wejścia
#programowanie #programista15k #bigdata #data #datascience #programowanieit
──
Co obecnie byś wybrał?
@mirko_anonim: nie ma sensu, bo to nie zależy od ścieżki tylko od projektu, firmy, ASERTYWNOŚCI i farta
─────────────────────
· Akcje: Odpowiedz anonimowo · Więcej