Siema, jutro mam pierwszą ever rozmowe techniczną na Big Data Dev'a. Macie jakieś porady, może pytania jakie występują ? Stack wymagany: Scala, Spark, Flink, Hadoop ( ogólnikowo bo nie wiem czy chodzi o hadoop czy o hadoop + frameworki) ale pewnie tak. Generalnie n-------m interview questions z google itp ale stack jest tak ogromny że przyswojenie tak dużej ilości wiedzy bez miesięcy praktyki jest ciężkie więc jedynie jak mogę odpowiedać to chyba
Wszystko
Najnowsze
Archiwum

programistalvlhard

Krever
@programistalvlhard: Stack bardzo standardowy. Przede wszystkim powiedz jakie masz doświadczenie i czy interview jest na jakiś konkretny level(junior, mid, senior). Rekrutowałem na takie stanowisko przez ponad pół roku więc pewnie mogę jakoś pomóc. Jak ogłoszenie jest publiczne to też możesz podesłać, może uda się coś wywnioskować z opisu albo znam firmę i coś podpowiem.
Krever
Ja zawsze sprawdzałem zrozumienie środowiska hadoopowego, tzn czy wiesz jak ze sobą współpracują poszczególne elementy. Tzn musisz wiedzieć że na najniższym poziomie nie ma czegos takiego jak hadoop, jest tylko hdfs, yarn, hive, hbase itp. Warto wiedziec czym sie rozni hive od hiveserver2 od mestastore i na jakiej zasadzie dziala integracja spark-hive(spark ma wlasny ewaluator do query hiveowych i bazuje na danych z metastora). Nigdy nie pytałem o API sparka ani kolekcji
Mam #pytanie. Może mondre, może gupie, nie wiem.
Jak się wkręcić w coś takiego jak "Cambridge Analytica"? Chciałbym pracować w miejscu, gdzie na podstawie jakichś danych, tworzysz profil danej grupy, określasz strategie, analizujesz czy to działa czy nie. Problem w tym, że ani nie mam jakiegoś kuca by ogarniać #datamining/ #bigdata, ani nie skończyłem #psychologia #marketing. Co trzeba
Jak się wkręcić w coś takiego jak "Cambridge Analytica"? Chciałbym pracować w miejscu, gdzie na podstawie jakichś danych, tworzysz profil danej grupy, określasz strategie, analizujesz czy to działa czy nie. Problem w tym, że ani nie mam jakiegoś kuca by ogarniać #datamining/ #bigdata, ani nie skończyłem #psychologia #marketing. Co trzeba
@sil3nt: Na stanowisko analityka z regóły wymagane jest doświadczenie z pakietami statystycznymi i bazodanowymi: SAS, SQL, R, Python. To są podstawowe narzędzia do analizy danych i bez doświadczenia z nimi raczej cieżko znaleźć pracę. Moża startować na stanowisko 'graduate' czyli świeżaka po studiach, ale wtedy warto mieć dyplom z ekonomii lub matematyki. Trzeba również dobrze wypaść na testach, chętnych po studiach jest znacznie więcej. To tyle jeśli chodzi o zwykłych
@sil3nt: Nie wydaje mi się aby w żadnej z opcji była gruba matma. Opcja pierwsza wydaje mi się najlepsza ze względu na sporą ilość SAS, analizę regresji oraz data mining, czyli dokładnie to co jest niezbędne do analizy danych i budowy modeli regresji. W opcji drugiej jest troche więcej matmy i inny software. Opcja trzecia wydaje się być bardziej IT. To znaczy więcej zabawy w przechowywanie danych niż ich analiza.
Wprowadzenie do agregacji danych w ElasticSearch - Cztery Tygodnie

Oprócz zaawansowanego wyszukiwanie pełnotekstowego w ElasticSearch mamy także możliwość grupowania i zliczania dokumentów. Co ważne operacje zliczania mogą być wykonywane równolegle z operacjami przeszukiwania indeksu. Dzięki czemu możemy zmniejszyć ilość zapytań do wyszukiwarki. Projekt...
z- 0
- #
- #
- #
- #
- #
#bigdata
Nie moge za bardzo skumac jak w architekturze Kappa jest zastapiana warstwa batch...
Moze mi ktos to wytlumaczyc...
W Lambda mam np. cos takiego ze z
Nie moge za bardzo skumac jak w architekturze Kappa jest zastapiana warstwa batch...
Moze mi ktos to wytlumaczyc...
W Lambda mam np. cos takiego ze z
@nie_tuzinkowy: w lambda lepiej użyć storma bieżących danych
@mirasKo-Kalwario: why
a nie spark structure streaming
a nie spark structure streaming
Lista przydatnych linków ze świata #programowanie #hubadev
1. -> https://www.diffchecker.com/ - Porównywanie dwóch plików tekstowych.
2. -> https://idea-instructions.com/ - Algorytmy wyjaśnione w stylu instrukcji składania mebli IKEA.
3.
1. -> https://www.diffchecker.com/ - Porównywanie dwóch plików tekstowych.
2. -> https://idea-instructions.com/ - Algorytmy wyjaśnione w stylu instrukcji składania mebli IKEA.
3.



Cześć! Kolejne nowości z #nofluffoffers dla wszystkich zainteresowanych Backendem, Fullstackiem i Frontendem.
`
`
**BACKEND JOBS**
- [REMOTE] [Java Developer](https://nofluffjobs.com/EA9YZSX7W) @ casumo.com 13.8k-22.5kCześć! Sprawdźcie nowości z kategorii Backend, Frontend i Fullstack :)
`
`
**BACKEND JOBS**
-
[REMOTE] .Net Developer @ qualicode.co 6.7k-10.4k
@nofluffjobs: Lubię Was, więc podpowiem, że #csharp jeszcze sporo.
@piotrb: Wielkie dzięki, przyda się! :D


Facebook nadal cię śledzi, nawet jak skasujesz swoje konto! Zobacz, jak sobie...
z tym poradzić! Skandal z nielegalnym zbieraniem danych użytkowników Facebooka i firmą, która doradzała sztabowi wyborczemu Trumpa sprawił, że wielu użytkowników postanowiło skasować konta. Okazuje się, że wykasowanie konta nie jest proste, to na dodatek użytkownik i tak później jest śledzony...
z- 55
- #
- #
- #
- #
- #
- #

#programowanie #java #bigdata
Mirki, mam dane pogodowe z kilkudziesięciu lat. Chciałbym te dane ładnie wizualizować (średnie, jak wzrasta/spada temp itp.). Następnie w celu nauki przeprowadzić analizę (wpływ pogody na dane zanieczyszczeń i innych danych). Na początku chcę się skupić na wizualizacji tych danych. Czy elasticsearch + grafana sądobrym rozwiązaniem? Możecie coś polecić?
Mirki, mam dane pogodowe z kilkudziesięciu lat. Chciałbym te dane ładnie wizualizować (średnie, jak wzrasta/spada temp itp.). Następnie w celu nauki przeprowadzić analizę (wpływ pogody na dane zanieczyszczeń i innych danych). Na początku chcę się skupić na wizualizacji tych danych. Czy elasticsearch + grafana sądobrym rozwiązaniem? Możecie coś polecić?

elasticsearch + grafana
@mariusz-laszczka: Będzie spoko. Ja bym tam pewnie trzymał w postgresql dopóki by nie stało się wąskim gardłem czy coś.
@mariusz-laszczka: może też przydatne będzie coś w stylu influxdb, ale nie wiem, nie korzystałem
1968-rok nie przejdzie.
Nie wiem, czy w każdym Firefoxie można to powtórzyć.
Jeżeli DNS jest ustawiony na Google'a 8.8.8.8, a przeglądarka to Firefox, to strona o adresie:
outofstream.pl/sejm-przyjal-uchwale-o-50-rocznicy-marca-1968-roku/201803070010
Nie wiem, czy w każdym Firefoxie można to powtórzyć.
Jeżeli DNS jest ustawiony na Google'a 8.8.8.8, a przeglądarka to Firefox, to strona o adresie:
outofstream.pl/sejm-przyjal-uchwale-o-50-rocznicy-marca-1968-roku/201803070010
@kjjbox: firefox to zło ;) Uciekaj na opera ;p
#suchar
- Halo, czy to pizzeria Giuseppe?
- Dzień dobry, nie, to pizzeria Google.
- Źle się dodzwoniłem?
- Nie, proszę pana, Google kupiło tę pizzerię.
- Halo, czy to pizzeria Giuseppe?
- Dzień dobry, nie, to pizzeria Google.
- Źle się dodzwoniłem?
- Nie, proszę pana, Google kupiło tę pizzerię.

Przebieg samochodu a jego wiek - ciekawa zależność
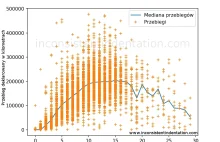
Jeżeli chcecie kupić samochód używany to pamiętajcie że przebieg to kwestia umowna. Szczególnie przy starszych samochodach. Koledzy bawią się ostatnio, i na podstawie analizy ~5000 losowych ofert z popularnego portalu z ogłoszeniami samochodowymi pozwala wyciągnąć jeden wniosek. W Polsce,...
z- 204
- #
- #
- #
- #
- #
- #

Mirabelki i Mireczki, czy ktoś z Was był może na jakimś sensownym stacjonarnym szkoleniu/kursie z obszaru #statystyka dla biznesu #datascience #bigdata #analizadanych które by było warte polecenia? Albo chociaż kojarzycie jakieś instytucje, które oferują tego rodzaju szkolenia o sensownej jakości? Bardziej myślałem o czymś zorientowanym na metodologię niż samo techniczne klepanie kodu R czy Pythona, bo same narzędzia łatwo ogarnąć samemu lub w zderzeniu

źródło: comment_hzFjL3LXlHsiG2ff9AQRKH3xGuraligi.jpg
Pobierz@Cooltec: pierwszy rozdział pt. "How to Sound Like a Data Scientist" xD
@kurp: tak. Codziennie o 1:00 (realnie 1:03) pojawia się nowy ebook.
Możesz obserwować #packtpubfreelearning ale ostatnio nie codziennie ktoś podrzuca przypominacza.
Oczywiście czasem wrzucą ebooka 4-letniego co COŚTAM v. 2.0 a aktualnie wszyscy robią na COŚTAM v. 4.5, ale czasem zdarzają się takie sprzed zaledwie kilku miesięcy.
Ogólnie quality staff.
Możesz obserwować #packtpubfreelearning ale ostatnio nie codziennie ktoś podrzuca przypominacza.
Oczywiście czasem wrzucą ebooka 4-letniego co COŚTAM v. 2.0 a aktualnie wszyscy robią na COŚTAM v. 4.5, ale czasem zdarzają się takie sprzed zaledwie kilku miesięcy.
Ogólnie quality staff.
Cześć,
Poszukuję osób mających pojęcie o zakładach bukmacherskich i statystyce w celu współpracy poświęconej zbudowaniu modelu matematycznego w meczach piłkarskich, z zamiarem przekucia tego w biznes polegający na płatnym oferowaniu informacji na temat sytuacji, w których wyjątkowo opłaca się postawić na daną drużynę (tzw. valuebet).
W praktyce wymaga to według mnie:
1. Zaprojektowania bazy danych,
2. Opracowania metody automatycznego pozyskiwania danych,
3. Zrobienia "researchu" nt. tego, jakie modele zostały już gdzieś przez kogoś zaproponowane - czyt. przerobienia
Poszukuję osób mających pojęcie o zakładach bukmacherskich i statystyce w celu współpracy poświęconej zbudowaniu modelu matematycznego w meczach piłkarskich, z zamiarem przekucia tego w biznes polegający na płatnym oferowaniu informacji na temat sytuacji, w których wyjątkowo opłaca się postawić na daną drużynę (tzw. valuebet).
W praktyce wymaga to według mnie:
1. Zaprojektowania bazy danych,
2. Opracowania metody automatycznego pozyskiwania danych,
3. Zrobienia "researchu" nt. tego, jakie modele zostały już gdzieś przez kogoś zaproponowane - czyt. przerobienia

źródło: comment_8NdMy9TCJmFL9z3toOTVEHEagKlRzAfB.jpg
Pobierz
konto usunięte via Android
@kravforth czyli inni mają odwalić za ciebie robotę a ty będziesz zbijał siano z bukmacherki? Tak to wygląda.
mielibyśmy grupę dyskusyjną, gdzie wymienialibyśmy się spostrzeżeniami, pomysłami, przedstawiali wyniki własnych analiz
@kravforth: pachnie jak brain-picking na którym to ty wyjdziesz najlepiej, strasznie to wszystko wygląda jakbyś chciał przycwaniaczyć
Alzo, wygląda jakbyś chciał napisać https://www.stratabet.com/ ( ͡° ͜ʖ ͡°)
EDIT: Zapomniałem dopisać, że kompletnie nie doceniasz jak trudne jest zrobienie tego, stratabet tworzył cały sztab ludzi od programistów przez analityków danych po doktorów statystyków i metematyków,

#bigdata #machinelearning
mirki możecie polecić jakiś dobry tutorial/książke w której opisane jest krok po kroku jak przygotować dane do użycia w algorytmach uczenia maszynowego?
mirki możecie polecić jakiś dobry tutorial/książke w której opisane jest krok po kroku jak przygotować dane do użycia w algorytmach uczenia maszynowego?

Pewnego dnia powstanie zdcentralizowana #sztucznainteligencja która będzie wszędzie, także utrzymywać będzie "pirackie serwery" na adresach IPV6 i nietylko, więc #infoanarchizm będzie niezniszczalny ( ͡° ͜ʖ ͡°)
Będzie sama się doskonalić czy sterować maszynami, każdy będzie w niej miał bezpieczą maszynę wirtualną i wszystko będzie oparte o wielowarstwową technologię #blockchain ( ͡° ͜ʖ ͡°)
To co dzisiaj się dzieje
Będzie sama się doskonalić czy sterować maszynami, każdy będzie w niej miał bezpieczą maszynę wirtualną i wszystko będzie oparte o wielowarstwową technologię #blockchain ( ͡° ͜ʖ ͡°)
To co dzisiaj się dzieje


@majsterV2: czeka nas Skynet, przy decentralizacji, nawet nie będzie możliwości jej wyłączenia ( ͡° ͜ʖ ͡°)
Dobra to takie pytanie. Powiedzmy że chcę zmienić dziedzinę w której się obracam (Oracle) na Hadoop deva (Big Data Engineer) + Cloud (AWS). Teraz kwestia jak wbić się na juniorskie stanowisko skoro liczba ofert dla juniorów jest równa zeru :D?.
Hipotetyczny stack do ogarniecia to: scala / python, hadoop stack (hdfs,storm,hbase,hive,pig,spark),, kafka, impala ?
Ma ktoś jakieś porady? Chętnie przyjmę ( ͡° ͜ʖ ͡°)
#bigdata #
Hipotetyczny stack do ogarniecia to: scala / python, hadoop stack (hdfs,storm,hbase,hive,pig,spark),, kafka, impala ?
Ma ktoś jakieś porady? Chętnie przyjmę ( ͡° ͜ʖ ͡°)
#bigdata #
Treść przeznaczona dla osób powyżej 18 roku życia...
Treść przeznaczona dla osób powyżej 18 roku życia...

CIekawe, czy za pomocą sztucznej inteligencji i #analizadanych #bigdata dałoby się ustalić, na podstawie samego stenogramu z komentarza #skoki , czy zawody komentuje Szaranowicz, Babiarz lub Szczęsny ( ͡° ͜ʖ ͡°)
#pjongczang2018
#pjongczang2018

{kind=link}
{kind=link}