
Friendship ended with Colab Tesla now RTX3090 is my best firend ( ͡° ͜ʖ ͡°)
#deeplearning #machinelearning #programowanie #kartygraficzne
#deeplearning #machinelearning #programowanie #kartygraficzne
Wszystko
Najnowsze
Archiwum

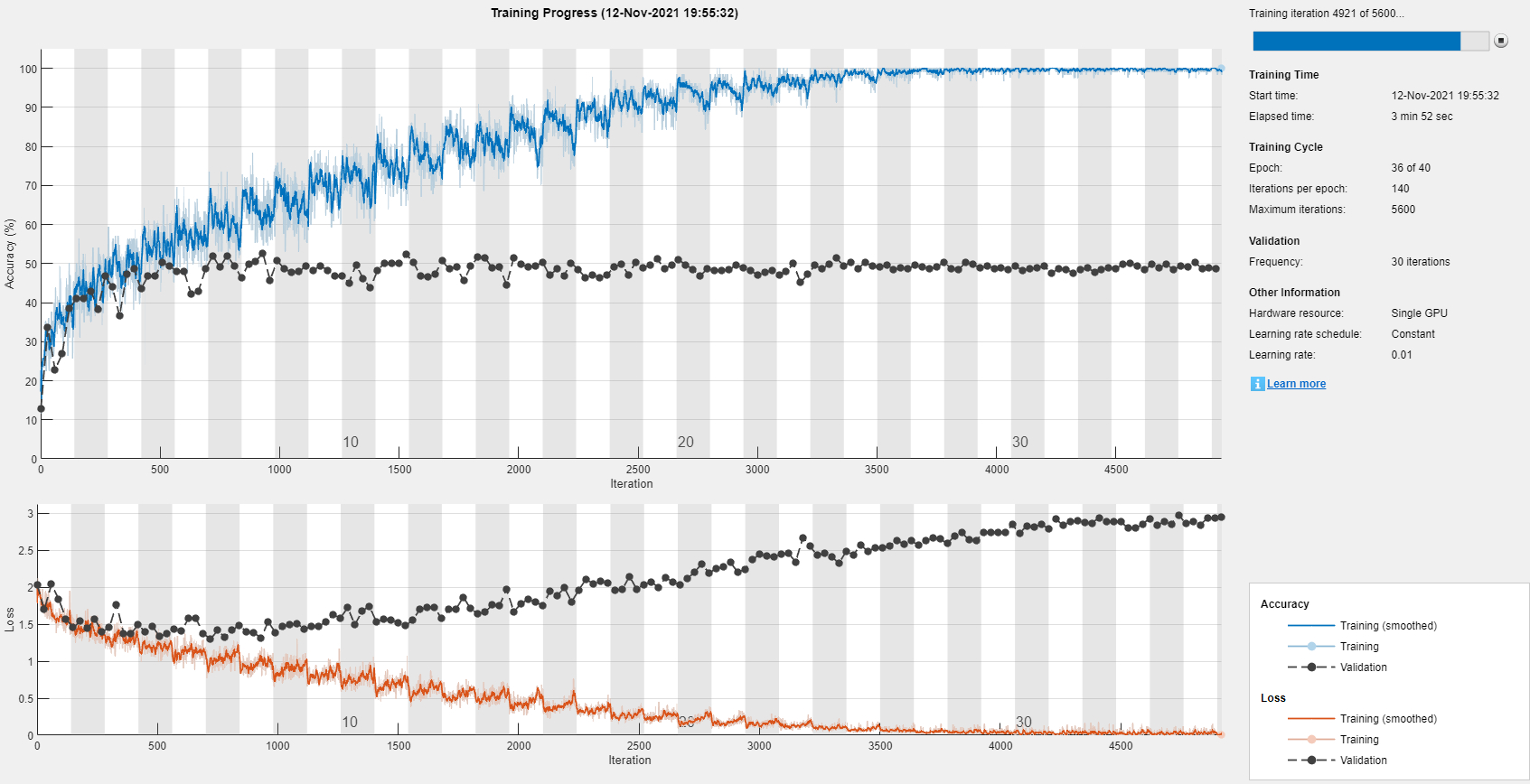
źródło: comment_1656966928UR7xnoXLEGH4ygJP4qbYu3.jpg
Pobierz
źródło: comment_1655938289GU2WRP43WYMF7A3scu6EUP.jpg
Pobierz
Sztuczna inteligencja potrafi stworzyć ultra realistyczne obrazy z prostego opisu. Mrówka Vader nie ma problemu.
zstate [dangerstraight, dangerright, dabgerleft, direction left, direction right, direction up, direction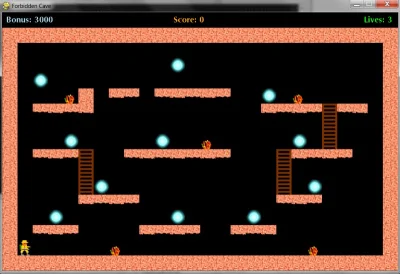
źródło: comment_1651335526WsxlTtN58sYwypjrnKYKN8.jpg
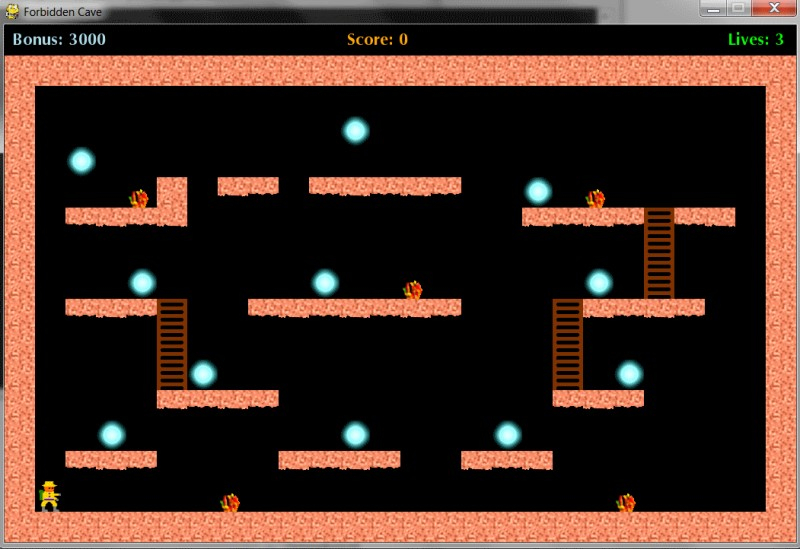
PobierzAle ja mam grę ze zdjęcia (forbidden cave) i przy mojej postaci chyba nie będzie kierunku tak?
obstacle_left, bo jeśli będąc na pozycji widocznej na screenie klikniesz strzałkę w lewo to zakładam, że nic się nie stanie. Pewnie jakiś wpływ ma też drabinka, więc również ladder_up
Modele głębokiego uczenia opracowane przez naukowców z IRT AESE Saint Exupéry i Météo-France sprawdzają się w prognozowaniu pogody. Są dużo szybsze niż prognozowanie oparte na metodach numerycznych, dzięki czemu ostrzeżenia można wysłać wcześniej.
z
Gdy będziemy już w środku, zakupy zajmą tylko chwilę - wystarczy wziąć z półki wybrane produkty i… wyjść.
z
źródło: comment_1636744148QGooGyVryCVFIOk8kCR79r.jpg
PobierzKomentarz usunięty przez autora



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
Co o tym myślicie, to jest na poważnie, możliwości są porównywalne do tych kodując tradycyjnie standardowe modele w #python?
#machinelearning #ml #sztucznainteligencja #deeplearning #