Wszystko
Najnowsze
Archiwum


@dixieman: to zalezy jaka to biblioteka, sa tez biblioteki header only xD bardzo malo informacji dajesz, co to za tajny projekt? Ogarnij w dokumentqcji biblioteki jak ja linkowac
Mirki,
pracuje ktoś (lub pracował) w int2code? widzę, że ich oferta non stop wisi na JustJoin.it
https://justjoin.it/offers/int2code-gmbh-remote-c-c-embedded-software-developer-fc1fd560-1822-469a-815f-f9726d3522e5
i się zastanawiam, czy aż tak trudno się dostać, czy ludzie stamtąd uciekają czy co ( ͡° ͜ʖ ͡°)
#pracait #programista15k #cpp #embedded
pracuje ktoś (lub pracował) w int2code? widzę, że ich oferta non stop wisi na JustJoin.it
https://justjoin.it/offers/int2code-gmbh-remote-c-c-embedded-software-developer-fc1fd560-1822-469a-815f-f9726d3522e5
i się zastanawiam, czy aż tak trudno się dostać, czy ludzie stamtąd uciekają czy co ( ͡° ͜ʖ ͡°)
#pracait #programista15k #cpp #embedded

#cpp
#programowanie
Czy da się zrobić aby funkcja wzięła kilka tablic dwuwymiarowych zdefiniowanych w mainie i użyła ich w swoim podprogramie? Jeśli tak to jak musi wyglądać definicja tej funkcji i jej wywołanie w mainie?
Cały czas wyskakuje mi jakiś błąd w kompilatorze i już nie wiem...
#programowanie
Czy da się zrobić aby funkcja wzięła kilka tablic dwuwymiarowych zdefiniowanych w mainie i użyła ich w swoim podprogramie? Jeśli tak to jak musi wyglądać definicja tej funkcji i jej wywołanie w mainie?
Cały czas wyskakuje mi jakiś błąd w kompilatorze i już nie wiem...

@mikser_zbalansowany: bo to denuvo na wirtualce, wtedy masz trudniej rozbić co robi ten launcher gry, bo jest w procesie wirtualki
Niektóre gry to mają tylko
Niektóre gry to mają tylko
Jestem nowy w #programowanie #cpp
Jak zrobić aby w "funkcji1" móc wstawić "funkcje2"
Jeśli funkcja1 jest wyżej w kodzie niż 2?
Kompilator pokazuje mi "identifier not found" a słyszałem że dało się jakoś powiedzieć kompilatorowi że coś występuje później w kodzie
Jak zrobić aby w "funkcji1" móc wstawić "funkcje2"
Jeśli funkcja1 jest wyżej w kodzie niż 2?
Kompilator pokazuje mi "identifier not found" a słyszałem że dało się jakoś powiedzieć kompilatorowi że coś występuje później w kodzie

pytania mam do osób, które siedzą w c++ nieco dłużej niż ja (miesiąc temu zacząłem naukę) I byłyby mi w stanie nieco przystępnie mi wytłumaczyć parę rzeczy.
1. funkcje zwracające void - w każdym kursie, lekcji, wykładzie, etc. jest napisane, że ta funkcja nic nie zwraca. pytanie - po co w takim razie w ogóle je stosować, czy funkcje czasami nie pisze się po to, by zwracały nam coś, jakąś wartość czy string,
1. funkcje zwracające void - w każdym kursie, lekcji, wykładzie, etc. jest napisane, że ta funkcja nic nie zwraca. pytanie - po co w takim razie w ogóle je stosować, czy funkcje czasami nie pisze się po to, by zwracały nam coś, jakąś wartość czy string,

@yungdupa:
1 - mogą modyfikować stan jakiegoś obiektu. Czy to dobra praktyka? Jeden rabin powie tak, inny nie
3 - jak sama nazwa mówi, to struktura danych ;)
A na 2 wydaje mi się że znam odpowiedz, ale niech Ci odpowie ktoś kto siedzi w C/C++
1 - mogą modyfikować stan jakiegoś obiektu. Czy to dobra praktyka? Jeden rabin powie tak, inny nie
3 - jak sama nazwa mówi, to struktura danych ;)
A na 2 wydaje mi się że znam odpowiedz, ale niech Ci odpowie ktoś kto siedzi w C/C++
@yungdupa:
1. Nie zawsze potrzebujesz, żeby funkcja zwracała wartość. Na przykład chcesz sobie napisać funkcję, która wypisuje jakieś dane na konsolę/do pliku. Oczywiście trochę słaby przykład, bo na przykład chciałbyś wiedzieć, czy wypisywanie się powiodło, albo ile znaków funkcja wypisała, i wówczas może zwracać wartość, np. liczbę wypisanych znaków. Ale jeśli wiesz, że i tak nie będziesz korzystać ze zwracanej wartości, to równie dobrze można to pominąć.
jeśli przy wywołaniu funkcji
1. Nie zawsze potrzebujesz, żeby funkcja zwracała wartość. Na przykład chcesz sobie napisać funkcję, która wypisuje jakieś dane na konsolę/do pliku. Oczywiście trochę słaby przykład, bo na przykład chciałbyś wiedzieć, czy wypisywanie się powiodło, albo ile znaków funkcja wypisała, i wówczas może zwracać wartość, np. liczbę wypisanych znaków. Ale jeśli wiesz, że i tak nie będziesz korzystać ze zwracanej wartości, to równie dobrze można to pominąć.
jeśli przy wywołaniu funkcji


Podpowie ktoś czemu funkcja tgamma() zwraca NaN dla ujemnych wartości typu double z zerową częścią ułamkową?
np.
std::tgamma(-10.1) = -2.21342e-06
std::tgamma(-10.0) = nan
wg.
np.
std::tgamma(-10.1) = -2.21342e-06
std::tgamma(-10.0) = nan
wg.

Podpowie ktoś czemu funkcja tgamma() zwraca NaN dla ujemnych wartości typu double z zerową częścią ułamkową?
@Malchos: bo funkcja gamma dąży do +/- nieskończoności w punktach całkowitych niedodatnich (https://en.wikipedia.org/wiki/Gamma_function)

@Malchos: Gamma w tych miejscach ma wartość nieskończoną
cout<<tgamma(-5)<<endl;cout<<tgamma(-5.0)<<endl;cout<<tgamma(-5.00001)<<endl;
źródło: comment_1636295887qtmjenmBjqH2lE2tEWcfQH.jpg
Pobierz
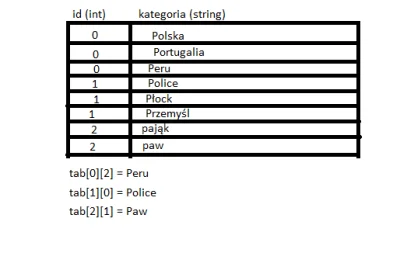
Mirki, w C++ chciałbym powiązać inta ze stringiem, mam ID kategorii i wartość.
Zależy mi aby do każdego elementu mieć dostęp po jego indeksie, stąd myślałem o tablicy dwuwymiarowej ale nie wiem jak się za to zabrać.
Próbowałem zastosować wektor par ale to chyba nie do końca jest to czego szukam.
W miarę rozrysowałem o co mi chodzi na obrazku.
#programowanie #cplusplus #cpp
Zależy mi aby do każdego elementu mieć dostęp po jego indeksie, stąd myślałem o tablicy dwuwymiarowej ale nie wiem jak się za to zabrać.
Próbowałem zastosować wektor par ale to chyba nie do końca jest to czego szukam.
W miarę rozrysowałem o co mi chodzi na obrazku.
#programowanie #cplusplus #cpp
źródło: comment_16360662412AMZ3gcUUX4N5pEBroPDhU.jpg
Pobierz@kolczan_prawilnosci: nie wiem co chcesz robić, ale tu tablica struktur raczej byłaby odpowiednia - przynajmniej na tak przedstawiony problem.
@kolczan_prawilnosci: Brzmi jak std:multimap
std::multimap map;
map.emplace(1, "A");
map.emplace(1, "B");
std::multimap map;
map.emplace(1, "A");
map.emplace(1, "B");
Można gdzieś znaleźć kod wbudowanych funkcji danego języka? Chodzi mi głownie o funkcje sin i atan w #js lub #cpp . Ale tez inne funkcje chciałbym podejrzeć np. te od tablic lub string np. replace itp.
#programowanie #javascript
#programowanie #javascript

@zezz: https://devdocs.io pewnie będzie najłatwiejsze do ogarnięcia. A tak to MDN dla JSa jest "oficjalną" dokumentacją a dla C++ nie ma jednego źródła, ale możesz np. zobaczyć https://cplusplus.com

@zezz: w kodzie silnika javascript

Czy to co teraz napisze, może być spowodowane wyciekiem pamięci? Po uruchomieniu programu z sumą kwadratów pojawił się dziwny błąd z wyświetlaniem numeru tablicy. https://imgur.com/a/a6jlyNZ Na onlinegdb.com jest wszystko w porządku. https://imgur.com/a/hEcBRAL Wcześniej w tym kodzie, zrobiłem drugą zmienną tablicową, ale zapomniałem wpisać delete [] dla tej drugiej zmiennej przed skompilowaniem. ( ͡° ͜ʖ ͡°) Co to jest za problem, jak to naprawić?
#cpp #naukaprogramowania
#cpp #naukaprogramowania


Pierwszy rzut oka na C++23:
https://blog.michalt.pl/article/pierwszy-rzut-oka-na-standard-c-23 #programowanie #it #cpp
https://blog.michalt.pl/article/pierwszy-rzut-oka-na-standard-c-23 #programowanie #it #cpp

Cześć. Kumpel zainteresował się #arduino i szuka #kursy #programowanie w #cpp w #gdansk lub #trojmiasto . Czy poza zdalnymi zajęciami organizuje ktoś takie rzeczy?


@stolemy: online na forbot

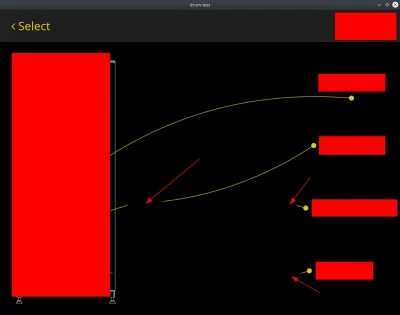
@lionbest: Takie coś.
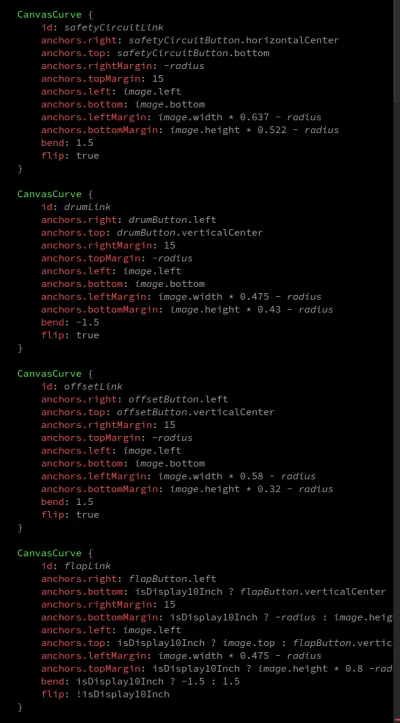
źródło: comment_1635941059NG8JHzlCGWXt6DcKcCVp4V.jpg
Pobierz
@NewEpisode: Sprawdź, czy nie masz gdzieś
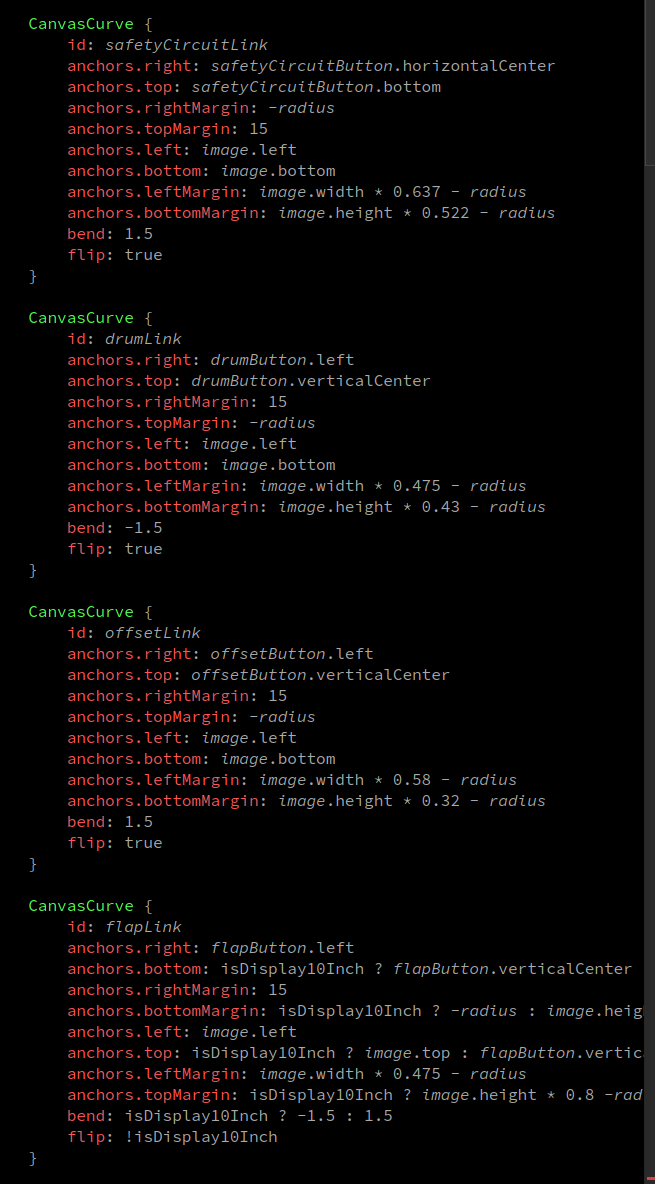
CanvasCurve.qml.Jak mogę przypisać melapsed.elapsed i mtimer.interval do zmiennej? AKtualnie rzuca "use of undeclared identifier"
#cpp
#cpp

źródło: comment_1635854458kHKL6GkbzSuSwnqswQVRxt.jpg
Pobierz
@NewEpisode: dopisując jakiego typu mają być to zmienne.
@NewEpisode: nie masz typu zdefinowanego

Treść przeznaczona dla osób powyżej 18 roku życia...


@AnonimoweMirkoWyznania: Przede wszystkim musisz douczyć się obiektówki. W każdym języku działa tak samo i od ~20 lat jest to podstawa organizacji kodu w większości nowoczesnych języków.
Natomiast C++ to absuralny syf, ale o ile wiem bardzo kasowy jak jesteś dobry. Ale Twoja decyzja.
Ja polecam do C++ materiały na wikibooks, z tego uczyłem się na studiach. Nigdy w tym nie pracowałem bo nie chciałem.
Wydaje się też, że miejsce w którym żyjesz to
Natomiast C++ to absuralny syf, ale o ile wiem bardzo kasowy jak jesteś dobry. Ale Twoja decyzja.
Ja polecam do C++ materiały na wikibooks, z tego uczyłem się na studiach. Nigdy w tym nie pracowałem bo nie chciałem.
Wydaje się też, że miejsce w którym żyjesz to

Treść przeznaczona dla osób powyżej 18 roku życia...

@JakTamCoTam: odśmiecacz? Ja tam wolę mieć kontrolę nad pamięcią
@MamCieNaHita: nie jestem ekspertem od c++, ale chyba odpowiednio stosując shared pointery i weak pointery można uniknąć leakow przy dowlonych grafach?

w #cpp bardzo mi się podoba fakt, że można od razu striggerować garbage collectora, a nie czekać, aż cały ram się zapcha i system zacznie spowalniać #programowanie #programista15k
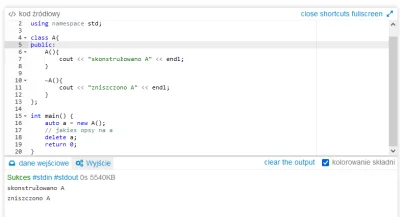
źródło: comment_16355078741nEZ91ViXY0TJfnxgTjd6g.jpg
Pobierz
@SmacznyPies: Od kiedy w cpp jest garbage collector?
#programowanie #cpp #qt
Czy jeżeli jakaś funkcja wysyła do sys.stderr, mogę jakoś przejąć tego stringa?
Czy jeżeli jakaś funkcja wysyła do sys.stderr, mogę jakoś przejąć tego stringa?
@Hauleth: nie wiem co przez to rozumiem :D chciałbym po prostu dostać wszystko to co on tam chce wyprintować, jako tekst... i przeformatować go po swojemu, bo mam własne funkcje do logowania sobie rzeczy

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@s_theCapt: Widzę że dałeś tag #cpp, więc masz rozwiązanie dla std::cerr
https://stackoverflow.com/questions/4810516/c-redirecting-stdout
https://stackoverflow.com/questions/4810516/c-redirecting-stdout
Link: https://www.slideshare.net/olvemaudal/deep-c
#programowanie #jezykc #cpp
op tasuje sie do tego ze C samo znajdzie funkcje print jak nie dasz includa albo zwroci result ostatniej operacji jak print gdzie wersja cpp by sie nie skompilowala
albo ze static sa inicjalizowane na 0
mozna tych rzeczy w 10 minut nauczyc kogos ale wiesz deep understanding ( ͡° ͜ʖ ͡°) co wy wiecie o c ( ͡° ͜ʖ