Mrki zaczynam uczyć się Django, zrobiłem tutorial z djangogirls, teraz zabieram się za tutorial ze strony django https://docs.djangoproject.com/en/1.8/intro/tutorial01/ jednak chciałbym zmienić domyślną baze danych SQLite na coś innego. Z tego co się orientuję (a jestem totalnie zielony) to najlepiej znać MySQL albo PostgreSQL. Decyduję się na PostgreSQL.
Zainstalowałem wg instrukcji na wiki postgresql https://wiki.postgresql.org/wiki/YUM_Installation dla Fedory 22. I co dalej? Wpisywać te wszystkie komendy w konsoli, którę są podane po zainstalowaniu postgresql-server?
Zainstalowałem wg instrukcji na wiki postgresql https://wiki.postgresql.org/wiki/YUM_Installation dla Fedory 22. I co dalej? Wpisywać te wszystkie komendy w konsoli, którę są podane po zainstalowaniu postgresql-server?






















{kind=link}
{kind=link}
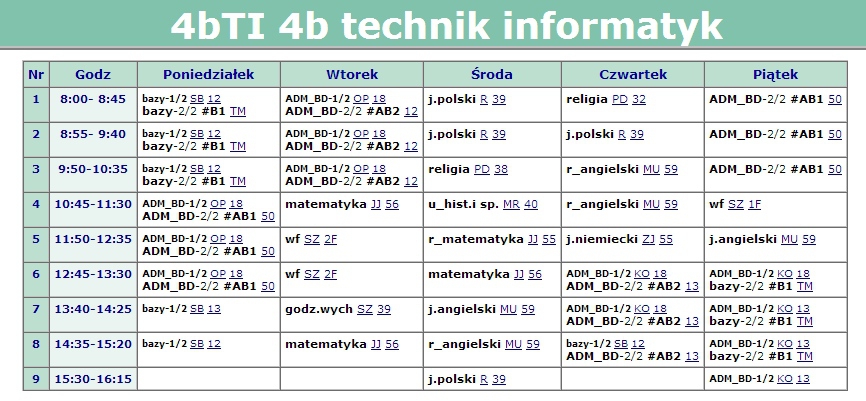
Mam taka tabelke z rozgrywkami
Macie pomysł na sprytne zliczenie wygranych,porażek,liczby meczy dla każdej drużyny ?
(pomińmy na razie kursory)
baza sql server 2012
#bazydanych #sql #sql
źródło: comment_t1v5abBpy3NlJK584ViCEkAZXIH9AnOx.jpg
Pobierzselect
TeamId
,sum(wygrana) as wygrane
,sum(przegrana) as przegrane
,sum(remis)