Wszystko
Najnowsze
Archiwum

Mireczky z #bazydanych
Tworzę tabelę w której mam pola kierunek i ID.
Chcę do nich wkleić dane tak jak zawsze to robię (LibreOffice Base), ale dostaję taki błąd:
Violation of unique constraint SYSPK61: duplicate value(s) for column(s) "Kierunek" in statement [INSERT INTO "zloszenia" ("Kierunek,"ID) VALUES (?,?)]
Ktoś wie o co tutaj chodzi?
Obie zmienne znakowe i wszystko się mieści na 100%, a z baz danych dość cienki jestem,
Tworzę tabelę w której mam pola kierunek i ID.
Chcę do nich wkleić dane tak jak zawsze to robię (LibreOffice Base), ale dostaję taki błąd:
Violation of unique constraint SYSPK61: duplicate value(s) for column(s) "Kierunek" in statement [INSERT INTO "zloszenia" ("Kierunek,"ID) VALUES (?,?)]
Ktoś wie o co tutaj chodzi?
Obie zmienne znakowe i wszystko się mieści na 100%, a z baz danych dość cienki jestem,

Violation of unique constraint duplicate value(s) for column(s) "Kierunek"
@Wyrewolwerowanyrewolwer: Masz założony unikalny index na pole "kierunek" i próbujesz wstawić już istniejącą wartość.
@MarcusPlinius: Dzięki za pomoc. Na siłę chciałem utworzyć klucz główny na jednym z istniejących danych i wszystko się przez to sypało.
Swoją drogą ciekawe rzeczy można dzięki temu mieć.
Swoją drogą ciekawe rzeczy można dzięki temu mieć.

Witajcie
uczę sie do #matura z #informatyka i to rozszerzona i mam pytanie apropo #bazydanych bo tam się korzysta z access no i właśnie te proste kwerendy nie stanowią problemu ale schody się zaczynają jak zwykłe sumy nie wystarczają.
1. czy access działa na podstawie SQL?
2. skąd się nauczyć takich przydatnych funkcji
dzięki
uczę sie do #matura z #informatyka i to rozszerzona i mam pytanie apropo #bazydanych bo tam się korzysta z access no i właśnie te proste kwerendy nie stanowią problemu ale schody się zaczynają jak zwykłe sumy nie wystarczają.
1. czy access działa na podstawie SQL?
2. skąd się nauczyć takich przydatnych funkcji
dzięki
@Fachmann: wszystko da się zrobić "prostą kwerendą" albo z wykorzystaniem dwóch (jedna jest jakby podkwerendą). Najlepiej poprzeglądać rozwiązania z zeszłych lat, maturainformatyka.pl (jak nie wejdzie, to wpisz w googlach adres i pierwszy wynik)

@michal1358: górny pasek, nie pamiętam juz dokładnie ale trzeba zmienić z "pokaż wszystkie" na "pokaż 1"
@ronek22: @Fachmann: co do tej kwestii - potrzebujesz po prostu left albo right joina, zmienisz to klikając prawym na połączenie w relacjach
@ronek22: @Fachmann: co do tej kwestii - potrzebujesz po prostu left albo right joina, zmienisz to klikając prawym na połączenie w relacjach
Jak powinno się przechowywać w bazie danych niepełną datę urodzenia? Wiem, że ktoś urodził się w 1865 i nie wiadomo kiedy dokładnie.
Albo wiadomo, że urodził się albo 8 kwietnia, albo 11 kwietnia, jak to zapisać?
#sql #bazydanych
Albo wiadomo, że urodził się albo 8 kwietnia, albo 11 kwietnia, jak to zapisać?
#sql #bazydanych
nie pomagajcie mu, tu zły człowiek.


Czy ktoś z was kiedykolwiek rozwiązywał problem rutowalności dróg z danych OSM? Żeby podzielić je na poziomy i później potworzyć węzły, po których można było wyznaczać trasy #pytanie #pomocy #sql #bazydanych
@superwoman: Nie sprecyzuje jak ale da się to zrobić, lata temu widziałem kod trasowania tym algorytmem na google maps i dało się rozwiązać problem węzłów.
@matju ok, dzięki pomyślę nad tym, może coś znajdę :)

Wtyczka SQLCipher dla SQLiteStudio - darmowe licencje demonstracyjne.
Od jakiegoś czasu dostępna jest płatna wtyczka do obsługi baz SQLCipher dla SQLiteStudio, ale teraz można zgłosić chęć przetestowania wtyczki, bez konieczności kupowania. Licencja demonstracyjna pozwala na używanie wtyczki przez tydzień.
Oficjalny kanał zamówień licencji demonstracyjnej: https://salsoft.com.pl/store/?trial-versions,27
Kanał dla Mirków - po prostu napiszcie wiadomość prywatną na wykopie.
Od jakiegoś czasu dostępna jest płatna wtyczka do obsługi baz SQLCipher dla SQLiteStudio, ale teraz można zgłosić chęć przetestowania wtyczki, bez konieczności kupowania. Licencja demonstracyjna pozwala na używanie wtyczki przez tydzień.
Oficjalny kanał zamówień licencji demonstracyjnej: https://salsoft.com.pl/store/?trial-versions,27
Kanał dla Mirków - po prostu napiszcie wiadomość prywatną na wykopie.
#sql #bazydanych
Znacie jakiś prawilny kurs od podstaw? A jak znacie i jeszcze moglibyście podlinkować to już w ogóle super ( ͡° ͜ʖ ͡°)
Znacie jakiś prawilny kurs od podstaw? A jak znacie i jeszcze moglibyście podlinkować to już w ogóle super ( ͡° ͜ʖ ͡°)

@ImOut: codeschool

Siemka mirki, jutro mam egzamin i jest jedna opcja która nie daje mi spokoju. Jaka jest różnica między 1 a 2 formą normalizacyjną w przygotowaniu baz danych (temat poruszany przy ERD) ? Da radę ktoś to wytłumaczyć na chłopski rozum?
#programowanie #sql #bazydanych
#programowanie #sql #bazydanych

Treść przeznaczona dla osób powyżej 18 roku życia...
Treść przeznaczona dla osób powyżej 18 roku życia...
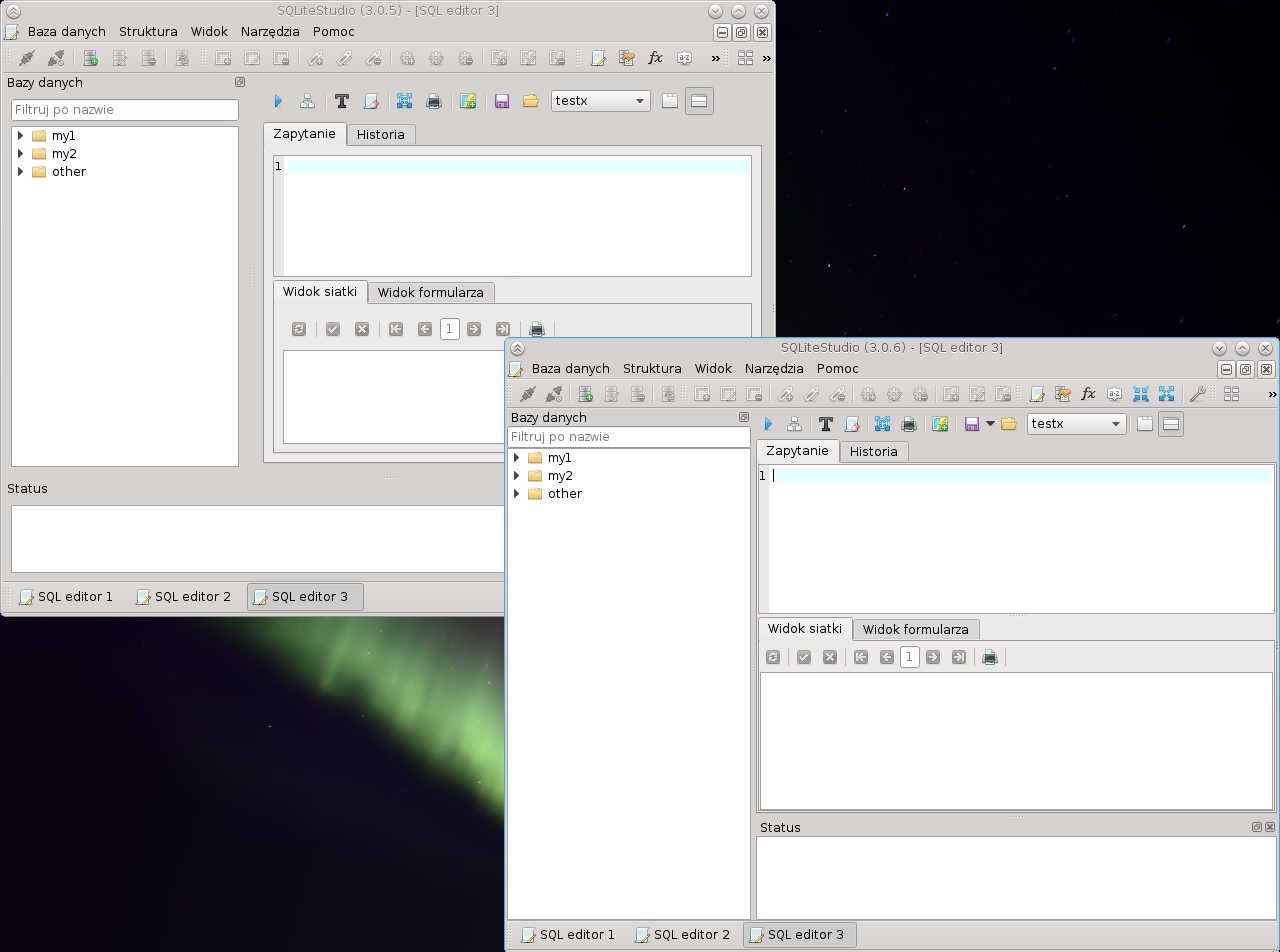
Wydałem SQLiteStudio 3.0.6
Z ważniejszych zmian:
- interfejs zoptymalizowany pod kątem prezentacji zawartości/danych - tj. zmniejszone do minimum marginesy kontrolek, żeby w oknie aplikacji mieściło się więcej informacji (można w opcjach przywrócić stare ustawienia)
- lista baz danych teraz domyślnie zajmuje całą lewą stronę (czyli pole statusu nie zajmuje już całej szerokości na dole), przez co widać więcej baz na liście (to też można zmienić w ustawieniach)
- podczas wstawiania nowego wiersza w widoku siatki można
Z ważniejszych zmian:
- interfejs zoptymalizowany pod kątem prezentacji zawartości/danych - tj. zmniejszone do minimum marginesy kontrolek, żeby w oknie aplikacji mieściło się więcej informacji (można w opcjach przywrócić stare ustawienia)
- lista baz danych teraz domyślnie zajmuje całą lewą stronę (czyli pole statusu nie zajmuje już całej szerokości na dole), przez co widać więcej baz na liście (to też można zmienić w ustawieniach)
- podczas wstawiania nowego wiersza w widoku siatki można
źródło: comment_JZWLSnhxbSDjMv1fI5cdxYfduefIgHQT.jpg
PobierzNiedługo wychodzi nowy produkt od ukochanych jetbrainsów - edytor baz. Już dziś można się zapisać do early access i ściągnąć.
https://www.jetbrains.com/dbe/features/
#programowanie #jetbrains #bazydanych
https://www.jetbrains.com/dbe/features/
#programowanie #jetbrains #bazydanych

@LOLWTF: To było jakieś 4-5 miesięcy temu, na jakimś Windowsie. Pewnie nic poważnego, ale akurat robiłem to w pracy i nie chciałem poświęcać na to więcej czasu. Jak będę miał w najbliższym czasie chwilę to na pewno się temu przyglądnę. Dzięki za przypomnienie ;)

@LOLWTF: sama wtyczka do Intellij jest w--------a w kosmos, więc boję się tego używać :D

#sf2 #symfony2 #bazydanych #mysql
używam create builder do stworzenia formularza.
W formularzu muszę przechowywać geolokalizacje, tj latitude i longitude...
Jakiego typu pola powinienem użyć oraz czy te dwie wartości powinienem trzymać razem czy osobno?
używam create builder do stworzenia formularza.
W formularzu muszę przechowywać geolokalizacje, tj latitude i longitude...
Jakiego typu pola powinienem użyć oraz czy te dwie wartości powinienem trzymać razem czy osobno?
@qwelukasz: to zależy. MySQL ma dopiero od wersji 5.7 potrafić indeksować dane geometryczne przechowywane w InnoDb, więc jeżeli to był Twój plan, to musisz poczekać. Jeżeli natomiast będą to tylko i wyłącznie lat/lng i nie planujesz stosować jakichś super skomplikowanych operacji, możesz użyć do tego celu decimal/float spokojnie ze zwykłym indeksem.

Witam,
Mam pytanie odnośnie baz danych XML.
Istnieją dwie drogi wykorzystanai takich baz.
Pierwsza to baza danych jako źródło danych akceptuje pliki xml przetwarza np. za pomocą SQL i wynik wystawia w postaci danych w plikach XML.
Drugą opcją są natywne bazy. Trzeba wtedy wybrać język opisujący dane w plikach(SGML, XML, YAML, JSON), wybrać język zapytań (Xpath, Xquery). Dobrze myślę? W tej drugiej opcji to my określamy sposób przetwarzania i zapisu? .
Mam pytanie odnośnie baz danych XML.
Istnieją dwie drogi wykorzystanai takich baz.
Pierwsza to baza danych jako źródło danych akceptuje pliki xml przetwarza np. za pomocą SQL i wynik wystawia w postaci danych w plikach XML.
Drugą opcją są natywne bazy. Trzeba wtedy wybrać język opisujący dane w plikach(SGML, XML, YAML, JSON), wybrać język zapytań (Xpath, Xquery). Dobrze myślę? W tej drugiej opcji to my określamy sposób przetwarzania i zapisu? .

@SebixBezKaryny: chyba najpopularniejsza baza danych xml: http://exist-db.org/exist/apps/homepage/index.html
Nie pamiętam czy ma dostępne jakieś przykładawe datasety.
Mogę się zapytać co tam ciekawego tworzysz?
Nie pamiętam czy ma dostępne jakieś przykładawe datasety.
Mogę się zapytać co tam ciekawego tworzysz?
@ghost1511: Mam prezentację o tego typu bazach danych.
Dziękuje za odpowiedź.
Dziękuje za odpowiedź.


@geekmaster: https://www.codeschool.com/courses/try-sql tak dokladnie

@ksiak: Dziwacznym rozwiązaniem jest np. obsługa constraintów:
A obsługa functional dependencies przed 5.7 jest ewidentą pułapką na niedoświaczonych programistów (na szczęście tylko raz musiałem to poprawiać w legacy code).
Dziwne zachowania zmieniają się zależnie od konfiguracji i wersji ale po
For other storage engines, MySQL Server parses and ignores the FOREIGN KEY and REFERENCES syntax in CREATE TABLE statements. The CHECK clause is parsed but ignored by all storage engines.
A obsługa functional dependencies przed 5.7 jest ewidentą pułapką na niedoświaczonych programistów (na szczęście tylko raz musiałem to poprawiać w legacy code).
Dziwne zachowania zmieniają się zależnie od konfiguracji i wersji ale po
Mirki, czy ktoś pisze apki pod Androida z użyciem SQLite'a?
Zrobiłem wtyczkę do SQLiteStudio do łączenia się z bazą na androidzie bezpośrednio ze swojego komputera i szukam kilku chętnych do wypróbowania i podzielenia się uwagami. Zaznaczam, że dotyczy to tylko baz w aplikacjach które samemu się pisze, nie dowolnych baz w telefonie.
W zamian mogę zaoferować wieczną licencję na ową wtyczkę. Nie szukam profesjonalnych testerów, a jedynie ludzi którzy mają styczność z tematem i
Zrobiłem wtyczkę do SQLiteStudio do łączenia się z bazą na androidzie bezpośrednio ze swojego komputera i szukam kilku chętnych do wypróbowania i podzielenia się uwagami. Zaznaczam, że dotyczy to tylko baz w aplikacjach które samemu się pisze, nie dowolnych baz w telefonie.
W zamian mogę zaoferować wieczną licencję na ową wtyczkę. Nie szukam profesjonalnych testerów, a jedynie ludzi którzy mają styczność z tematem i
#informatyka #bazydanych #komputery #pytanie #szkola
Ktoś może ma w jakimś pdf wyjaśnioną obsługę accessa? Nie miałem do czynienia z tym programem nigdy i się gubię.
Ktoś może ma w jakimś pdf wyjaśnioną obsługę accessa? Nie miałem do czynienia z tym programem nigdy i się gubię.


@Przemysl: Widzę to czego szukałem. Dzięki wielkie!! :)

Mam jako projekt do napisania aplikację webową w której nawiążę połączenie z bazą danych SQL Server oraz umożliwię dodawanie, usuwanie oraz edycję rekordów.
Jestem kompletnie zielony w temacie, nigdy też nie pisałem nic w C# czy Javie, znam jedynie podstawy SQL.
Moje pytanie - jakich narzędzi użyć by zrobić to możliwie najprościej i najszybciej?
#bazydanych #java #programowanie #sql
Jestem kompletnie zielony w temacie, nigdy też nie pisałem nic w C# czy Javie, znam jedynie podstawy SQL.
Moje pytanie - jakich narzędzi użyć by zrobić to możliwie najprościej i najszybciej?
#bazydanych #java #programowanie #sql

Treść przeznaczona dla osób powyżej 18 roku życia...
@Malchos: prosty CRUD w javie to kwestia godziny ze spring bootem, polecam
a front-end wiadomo, jak kto chce, ja polecam albo angular(jesli chcesz SPA) albo thymeleaf
a front-end wiadomo, jak kto chce, ja polecam albo angular(jesli chcesz SPA) albo thymeleaf
#bazydanych #programowanie #mysql #postgresql
Mam takie pytanie do bardziej doświadczonych dev'ów.
Sprawa jest następująca.
Jest strona, na której osoba zakłada konto (podaje nazwę firmy, swoj login i hasło) i automatycznie staje się administratorem w obrębie swojego konta w danej firmie.
Mam takie pytanie do bardziej doświadczonych dev'ów.
Sprawa jest następująca.
Jest strona, na której osoba zakłada konto (podaje nazwę firmy, swoj login i hasło) i automatycznie staje się administratorem w obrębie swojego konta w danej firmie.
@qwelukasz: PostgreSQL i MySQL osiągają podobną wydajność, więc tu musisz wybrać tą bazę, którą wolisz.
7500 wpisów to dla bazy danych bardzo mało danych. Gdyby tych danych było miliardy to wtedy mógłbyś zaczynać zastanawiać się nad wydajnością.
Musisz oczyswiście pamiętać o założeniu odpowiednich indeksów na pola. Przede wszystkim ważny będzie indeks na id_firmy, żeby szybko wybierać dane dla poszczególnej firmy.
7500 wpisów to dla bazy danych bardzo mało danych. Gdyby tych danych było miliardy to wtedy mógłbyś zaczynać zastanawiać się nad wydajnością.
Musisz oczyswiście pamiętać o założeniu odpowiednich indeksów na pola. Przede wszystkim ważny będzie indeks na id_firmy, żeby szybko wybierać dane dla poszczególnej firmy.
@qwelukasz:
1. Bazy danych mają typ reprezentujący datę, więc chyba lepiej używać go niż stringów.
2. Dla wpisów historycznych stworzyłbym osobną tabelę. W tym momencie żeby wyświetlić aktualne wpisy musisz dla każdego wpisu wybrać wpis z maksymalnym historyid. To powoduje konieczność użycia podzapytań, co znacząco wpływa na wydajność (to można obchodzić dodając pole trzymające informację, czy dany wiersz jest aktualny, ale mimo wszystko lepiej przenieść te dane do osobnej
1. Bazy danych mają typ reprezentujący datę, więc chyba lepiej używać go niż stringów.
2. Dla wpisów historycznych stworzyłbym osobną tabelę. W tym momencie żeby wyświetlić aktualne wpisy musisz dla każdego wpisu wybrać wpis z maksymalnym historyid. To powoduje konieczność użycia podzapytań, co znacząco wpływa na wydajność (to można obchodzić dodając pole trzymające informację, czy dany wiersz jest aktualny, ale mimo wszystko lepiej przenieść te dane do osobnej

Jaki program, wtyczka do wordpressa, cokolwiek żeby zrobić bazę danych książek?
#bazydanych #programy
#bazydanych #programy
@MaNiEk1: z chęcią też bym poznał taką wtyczkę

Mirki poratuje ktoś od #bazydanych ? Przy próbie logowania po włączeniu programu mam taki błąd:
A
The log scan number (10375:384:1) passed to log scan in database 'CDN_NAZWABAZY' is not valid. This error may indicate data corruption or that the log file (.ldf) does not match the data file (.mdf). If this error occurred during replication, re-create the publication. Otherwise, restore from backup if the problem results in a failure during startup.A

{kind=link}
{kind=link}
Mireczki , szukam bazy danych kodów pocztowych powiązanych z miastami i województwami a najlepiej to gminami , macie może dostęp do takiego czegoś albo wiecie gdzie taką bazę można uzyskać ? (najlepiej nie płatną)