
#naukaprogramowania #programowanie #programista15k #bazydanych #nosql #czytajzwykopem #ksiazki
Właśnie skończona. Polecam, jako miłe wprowadzenie do NoSQL. Książka napisana prostym, jasnym językiem. Zawiera ogrom przypisów i odniesień do bardziej szczegółowych materiałów. Książka nie dotyczy bowiem jakichś konkretnych baz NoSQL, tylko opisuje teorie, jakie stoją za czterema najważniejszymi. Dobre fundamenty pod dalszą naukę.
Właśnie skończona. Polecam, jako miłe wprowadzenie do NoSQL. Książka napisana prostym, jasnym językiem. Zawiera ogrom przypisów i odniesień do bardziej szczegółowych materiałów. Książka nie dotyczy bowiem jakichś konkretnych baz NoSQL, tylko opisuje teorie, jakie stoją za czterema najważniejszymi. Dobre fundamenty pod dalszą naukę.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
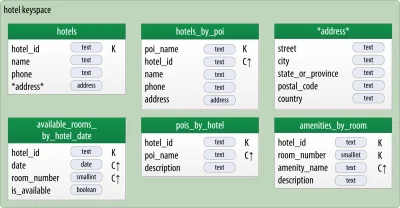
Przykład w relacyjnej bazie:
users
- id