
Cześć, mam problem - mam dosc duzy plik csv - na tyle duzy, ze samo wczytywanie trwa kilkanascie sekund (a bedzie bardzieł puchł). mocno spowalni mi dzialanie aplikacji - poustawialem juz recznie rodzaje danych w kolumnach, wstawilem gdzuie sie da dane kategoryczne, ale nadal wolno. W zwiazku w tym mam pytaie (jak na razie nic nie znalalem na ten temat w sieci): czy jest opcja wczytywania z pliku csv tylko interesujacyh mnei
Wszystko
Najnowsze
Archiwum



#python #pytanie #pandas
potrzebuję pomocy w sprawdzeniu poprawności danych w skrypcie używającym pandas i datetime w pythonie.
Mam sobie taki input, gdzie
potrzebuję pomocy w sprawdzeniu poprawności danych w skrypcie używającym pandas i datetime w pythonie.
Mam sobie taki input, gdzie
start_time, end_time oraz session_time mam podane jako string. Konwertuję to sobie do datetime.timedelta, dodaję start_time do start_date (które na wejściu nie ma podanych godzin i minut, sam rok, miesiąc, dzień), uzyskując start_time jako datetime z godzinami. Następnie dodaję do tego session_time i wychodzi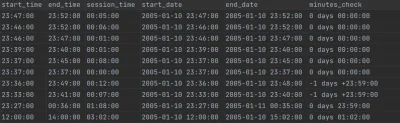
źródło: comment_1622308692E1yYkE2yevKQyvAXkJskBb.jpg
Pobierz@CancerLight: no właśnie to się sprowadza w sumie do tego samego, bo
end_time i end_date będą mieć różną datę, jeśli skonwertuję. w sumie jak teraz pomyślałem, to chyba najprostsze rozwiązanie to skonwertować to do stringa i porównać stringi, ale trochę to denerwujące, bo nie po to konwertowałem na datetime wszystko, żeby później z powrotem wracać na stringi ( ͡° ʖ̯ ͡°)dobra, poradziłem sobie na stringach, ale dla potomnych: timedelta może przyjąć parametr
.abs - https://stackoverflow.com/questions/41782920/how-do-i-format-a-pandas-timedelta-objectCześć,
mam pytania z zakresu #python, #pandas i ogólnie #datascience.
Zasysam dośc duża tabelę z bazy danych (ok 1,5GB). Po zakonczeniu procesu sprawdzam jakiego typu mam kolumny ( tabela.info() ). Wszystkie sa typem 'object'. Jednak jak dam type(tabela[kolumna][0]) to otrzymuje np. decimal.Decimal.
W zwiazku z tym mam pytania:
1. W koncu jakiego typu jest taka kolumna?
2. Z uwagi na dosc duza liczbe wierszy (ok 13 milionow) chce
mam pytania z zakresu #python, #pandas i ogólnie #datascience.
Zasysam dośc duża tabelę z bazy danych (ok 1,5GB). Po zakonczeniu procesu sprawdzam jakiego typu mam kolumny ( tabela.info() ). Wszystkie sa typem 'object'. Jednak jak dam type(tabela[kolumna][0]) to otrzymuje np. decimal.Decimal.
W zwiazku z tym mam pytania:
1. W koncu jakiego typu jest taka kolumna?
2. Z uwagi na dosc duza liczbe wierszy (ok 13 milionow) chce
@thomeq object na category zazwyczaj daje dobre efekty. No i do zmiany numerycznych możesz uzyc pd downcast. Zazwyczaj domyslnie jest jakis 64bitowy int/float

@thomeq: 3. Przy zmiennych binarnych mozesz sobie zrobic get dummies i zdropowac pierwsza (czyli cos na zasadzie is_male z wartosciami 0 i 1 lub bool). Jesli chodzi o wiek to zazwyczaj warto sobie to pokubelkowac jakos sensownie. Jesli pracujesz np. na miejscu zamieszkania to mozesz sociagnac sobie skads wielkosc miejscowosci i pokubelkowac na male, srednie i duze miasta lub np wyliczyc odleglosc od najblizszej siedziby Waszej firmy. Co do wydajnosci

Mam coś takiego, grupujące df po 'name' i wyrzucające sumy dodatnich i ujemnych wartosci z 'xTAdded':
Jak mogę dodać kolejną kolumnę, gdzie byłaby podobna suma tylko liczona tylko dla kolumn spełniających warunek? Np. chciałbym kolumnę 'buildup', która sumuje dodatnie 'xTAdded' ale tylko, gdy w kolumnie 'endX' jest wartość <70. Tutaj ta lambda się odwołuje sama
df.groupby(df['name'])['xTAdded'].agg([('neg' , lambda x : x[x < 0].sum()) , ('pos' , lambda x : x[x > 0].sum())])Jak mogę dodać kolejną kolumnę, gdzie byłaby podobna suma tylko liczona tylko dla kolumn spełniających warunek? Np. chciałbym kolumnę 'buildup', która sumuje dodatnie 'xTAdded' ale tylko, gdy w kolumnie 'endX' jest wartość <70. Tutaj ta lambda się odwołuje sama


mam dwa źródła, w każdym źródle jest wachlarz wartości. chciałbym sprawdzić oraz ładnie zwizualizować korelację w #powerbi albo #python #pandas moze być w czymś innym chodzi o to aby jakos ciekawie i najlepiej to zrobić #bazydanych #wizualizacjadanych #naukaprogramowania
@rosso_corsa: Jeśli o samą korelację ci chodzi to możesz również użyć regplot() lub lmplot() z biblioteki seaborn

@rosso_corsa:
sns.heatmap(df.corr())
sns.heatmap(df.corr())

Mirki, mam pytanie które wydaje się dość podstawowe ale naprawdę nie mogę nigdzie znaleźć satysfakcjonującej odpowiedzi.
Powiedzmy, że chcę generować dane finansowe dotyczące spółek giełdowych. Ponieważ cena akcji podawana jest codziennie a raporty dotyczące zadłużenia, zysków, czy wartości księgowej rzadziej (na przykład kwartalnie), wydaje mi się że optymalne jest rozdzielenie tych dwóch danych na dwie różne tabele:
- OHLC za każdy dzień
- Snapshot pokazujący dane finansowe z raportu za dany okres
Powiedzmy, że chcę generować dane finansowe dotyczące spółek giełdowych. Ponieważ cena akcji podawana jest codziennie a raporty dotyczące zadłużenia, zysków, czy wartości księgowej rzadziej (na przykład kwartalnie), wydaje mi się że optymalne jest rozdzielenie tych dwóch danych na dwie różne tabele:
- OHLC za każdy dzień
- Snapshot pokazujący dane finansowe z raportu za dany okres

@Mr_NiceGuy: Na końcu jest forward fill - na puste "miejsca" wstawi pierwszą wartość leżącą powyżej
@Mr_NiceGuy: my pleasure.
Cześć, mam pytanie z #python, dokladniej z #pandas.
Mam ramke danych z kolumnami: X, Y Q i Z, przy czym Z powstała w wyniku .unique() (tj zawiera w sobie numpy.ndarray z kilkoma wartosciami - wczesniej dla kazdego X i Y bylo kilka roznych wartosci Z, ale zostały ta komenda zebrane do tablicy numpy, tak, ze teraz jedna linijka to jeden unikalny zestaw X i Y) np.
A |
Mam ramke danych z kolumnami: X, Y Q i Z, przy czym Z powstała w wyniku .unique() (tj zawiera w sobie numpy.ndarray z kilkoma wartosciami - wczesniej dla kazdego X i Y bylo kilka roznych wartosci Z, ale zostały ta komenda zebrane do tablicy numpy, tak, ze teraz jedna linijka to jeden unikalny zestaw X i Y) np.
A |

df['match'] = df.apply(lambda x: x['Q'] in x['Z'], axis=1)i potem filtorowanie po df.match? Trochę naokoło ale powinno zadziałać.

Treść przeznaczona dla osób powyżej 18 roku życia...
Treść przeznaczona dla osób powyżej 18 roku życia...

@kamilek98PL: Z doświadczenia panadas jest spoko, jak masz dużo danych, żeby coś wyszukać, wyciągnąć itp. jako kontener ala baza danych. Obróbkę tych danych zawsze wolałem robić poza. Aczkolwiek znam ludzi, którzy jak wgłębili się w dokumentację to robią turbo rzeczy na data frame. Także kto co woli. Jak to się mówi jeśli masz problem prawdopodobnie w pythonie już go rozwiązano Ty musisz tylko znaleźć to które Ci pasuje. I data
szukam prostego sposobu w #pandas #python aby w df zliczyć i wyswietlic a nastepnie usunac wiersze ktore beda mialy 3x nan w trzech wskazanych przeze mnie kolumnach. jest tu moze jakis majster-ekspert ktory mi podopowie? #naukaprogramowania
@rosso_corsa:
Tu masz taki bardziej elegancki sposób.
Założenie jest takie, że szukamy wsród kolumn A, B, C stąd to list('ABC')
df.loc[df[list('ABC')].isna().all(axis=1), :]
Tu masz taki bardziej elegancki sposób.
Założenie jest takie, że szukamy wsród kolumn A, B, C stąd to list('ABC')
df.loc[df[list('ABC')].isna().all(axis=1), :]
@1001001: a ja tak pyknalem, najwazniejsze ze dziala
dane[dane['P1'].isnull() & dane['P2'].isnull()& dane['P0'].isnull()]
dane[dane['P1'].isnull() & dane['P2'].isnull()& dane['P0'].isnull()]
Chce zautomatyzować sobie tworzenie makra po przez pythona i zastanwiam się jak to osiągnąć.
Przykładowy case:
Mam plik .xlsx gdzie mam table z kolumnami: kolumna1, kolumna2, kolumna3
chce
Przykładowy case:
Mam plik .xlsx gdzie mam table z kolumnami: kolumna1, kolumna2, kolumna3
chce
@znowu_musze_wymyslac:
tak sądziłem... jeszcze raz:
użytkownik tworzy dwa pliki wejścia, plik z danymi (*.xslx) i plik szablonu (*.txt)
skrypt iteruje po każdym wierszu w pliku z danymi (*.xlsx) i kolumnach zdefiniowanych w szablonie (*.txt) w
tak sądziłem... jeszcze raz:
użytkownik tworzy dwa pliki wejścia, plik z danymi (*.xslx) i plik szablonu (*.txt)
skrypt iteruje po każdym wierszu w pliku z danymi (*.xlsx) i kolumnach zdefiniowanych w szablonie (*.txt) w

źródło: comment_15985553486iZc5HkyKg8ADV10rBFRVk.jpg
Pobierz@login_zajety_sic: Ja bym to zrobił w sposób następujący
1. Przechodzisz po pierwszym wierszu i parujesz nazwę z literą oznaczającą kolumnę np. (kolumna1,A), (kolumna2,b)
2. Przechodzisz przez resztę wierszy podmieniając wszystkie {kolumnaX} na odpowiadające im wartości
np. jesteś w wierszu drugim, w szablonie napotykasz na {kolumna1}, sprawdzasz z którą kolumną zostało sparowane i podstawiasz tam wartość z A2
1. Przechodzisz po pierwszym wierszu i parujesz nazwę z literą oznaczającą kolumnę np. (kolumna1,A), (kolumna2,b)
2. Przechodzisz przez resztę wierszy podmieniając wszystkie {kolumnaX} na odpowiadające im wartości
np. jesteś w wierszu drugim, w szablonie napotykasz na {kolumna1}, sprawdzasz z którą kolumną zostało sparowane i podstawiasz tam wartość z A2
#python #selenium #pandas
cześć, muszę wykonać kilka operacji na kilkuset obiektach w apce webowej z wykorzystaniem selenium. Kod jest napisany, dane są zaciągane do df z Excela. Moje pytanie dotyczy tego jak "poprawnie i ładnie" to napisać.
Mój pomysł był dosyć prosty i kilka razy go wykorzystywałem, ale czy programista napisałby to w taki sam sposób?
Piszę
cześć, muszę wykonać kilka operacji na kilkuset obiektach w apce webowej z wykorzystaniem selenium. Kod jest napisany, dane są zaciągane do df z Excela. Moje pytanie dotyczy tego jak "poprawnie i ładnie" to napisać.
Mój pomysł był dosyć prosty i kilka razy go wykorzystywałem, ale czy programista napisałby to w taki sam sposób?
Piszę

KoronaScience za darmo: kurs z podstaw Data Science w Pythonie
https://www.facebook.com/events/1094217857617583/
W trakcie kursu:
Poznasz podstawy #python, biblioteki #numpy, #pandas, #matplotlib i innych między innymi napiszemy razem prosty algorytm uczelnia maszynowego. Nauczysz się także pracować z obrazkami
https://www.facebook.com/events/1094217857617583/
W trakcie kursu:
Poznasz podstawy #python, biblioteki #numpy, #pandas, #matplotlib i innych między innymi napiszemy razem prosty algorytm uczelnia maszynowego. Nauczysz się także pracować z obrazkami

Mam to co na screane. W jaki sposob moglbym zrobic tak aby tabela wygladala w taki sposob:
Intervaltype Australia Belgium Germany France
5/27 100 2000 800 200
5/28 159 777 7993 232
5/29
Intervaltype Australia Belgium Germany France
5/27 100 2000 800 200
5/28 159 777 7993 232
5/29
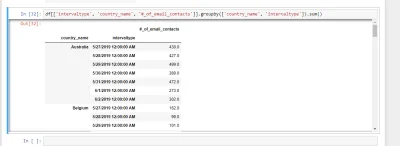
źródło: comment_kEFJivYsDE309r1QEcpbYiK5hYyQNnX3.jpg
Pobierz
Dzisiaj Mastering Python Data Analysis with Pandas [Video] (Thursday, September 28, 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #analizadanych #pandas
odpowiedź
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #analizadanych #pandas
odpowiedź
![konik_polanowy - Dzisiaj Mastering Python Data Analysis with Pandas [Video] (Thursday...](https://wykop.pl/cdn/c3201142/comment_D9yeNC3fRloYNKCwYZxkbb2yWKYcFCb4,w400.jpg)
źródło: comment_D9yeNC3fRloYNKCwYZxkbb2yWKYcFCb4.jpg
Pobierz
@konik_polanowy: dziekuje :)

@konik_polanowy: Imię i nazwisko autora nie brzmi zachęcająco.


@luzny_lori: ona zle napisala, jej chodzi ze tworzenie listy jako [*x] jest nieprawidlowe w pythonie 2.7
Dzisiaj Pandas Cookbook (October 2017)
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #pandas #python
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #pandas #python

źródło: comment_hpVTDnHsY4Cyg1Nl07KnSO4J1PZ7PgV3.jpg
Pobierz

#python #pandas #inwestycje #polska #ekonomia #programowanie
Zrobiłem interaktywną mapę prezentującą najnowszy wynalazek rządzących, czyli Polską Strefę Inwestycji. Może kogoś zainteresuje. W analizie danych wykorzystałem dwie biblioteki pythonowe czyli xlrd i pandas. A sama mapa zrobiona w QGIS.
Tu link do znaleziska.
https://www.wykop.pl/link/4512601/nie-widac-zaborow-mapa-powiatow-polskiej-strefy-inwestycji/#
Zrobiłem interaktywną mapę prezentującą najnowszy wynalazek rządzących, czyli Polską Strefę Inwestycji. Może kogoś zainteresuje. W analizie danych wykorzystałem dwie biblioteki pythonowe czyli xlrd i pandas. A sama mapa zrobiona w QGIS.
Tu link do znaleziska.
https://www.wykop.pl/link/4512601/nie-widac-zaborow-mapa-powiatow-polskiej-strefy-inwestycji/#

Znajdzie się ktoś kto ogarnia #pandas, #machinelearning, #scikitlearn i #python? Za cholerę nie mogę wykminić odpowiedniego przygotowania danych do klasyfikacji tekstu. Problem opisałem tutaj: https://stackoverflow.com/questions/49466193/sklearn-text-classification-attributes , jak będzie trzeba mogę to zrobić jeszcze dokładniej.
#programowanie
#programowanie


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mirki, mam timeseries z sieci basenow (czas, liczba wejsc, lokalizacja itp..) Chcialbym stworzyc model predykcyjny na podstaiwe tych danych, uzywajac #python #pandas. Przyznaje, ze z metodami stochastycznymi jestem troche na bakier i wlasicie #datascience dopiero zaczynam sie uczyc. Moglby ktos mnie nakierowac jak sie do tego zabrac?
#statystyka #machinelearning
#statystyka #machinelearning
@erwit: szeregi czasowe beda dobre jak nie masz innych zmiennych, w przeciwnym przypadku moglbys wyjac z timestampa np godzine, dzien tygodnia, miesiac itd i wrzucic je jako zmienne + do tego np liczba ludnosci w miescie, wojewodztwo itd wszystko zalezy od kreatywnosci :D
w przypadku szeregow polecam uzyc SARIMA bo na pewno bedzie to szereg sezonowy i mozliwe ze pojawi sie heteroskedastycznosc (wtedy trzeba bedzie siegnac po nieco bardziej zaawansowane
w przypadku szeregow polecam uzyc SARIMA bo na pewno bedzie to szereg sezonowy i mozliwe ze pojawi sie heteroskedastycznosc (wtedy trzeba bedzie siegnac po nieco bardziej zaawansowane
Mam dwie tabele (tab1 - kolumny A, B; tab2- kolumny C, D). Jedna ma 2 wiersz3, druga - trzy. Dla ulatwienia - jedna ma wartosci x, a druga - y.Chce je połączyc wierszami (dokladnie w kolejnosci wystepowania w tabeli), a brakujace wiersze wypelnic np. 'z'.
Pożądany efekt końcowy:
A B C D
x x y y
x x y y
@thomeq: bo domyślnie concat łączy po wierszach, zmień parametr axis
te tabele to wyimki z wiekszych tabel. Skubany patrzyl na indeks wierszy oryginalnej tabeli i brał go pod uwage...
5h siedzenia... (concat na poczatku probowalem)... :/