Wszystko
Najnowsze
Archiwum




Zagraj z komputerem w kamień, nożyce, papier.
#mikroreklama #technologia #ciekawostki #algorytmy #komputery #gry
#mikroreklama #technologia #ciekawostki #algorytmy #komputery #gry
Zagraj z komputerem w kamień, nożyce, papier.

Cała zabawa zaczyna się od momentu kiedy algorytm nauczy się twojego toku rozumowania. Cały problem polega na tym że ludzie nie są w stanie być całkowicie losowi w swoich wyborach. Zdarzają się jednak ludzie którzy będą wygrywać częściej. Pewnie to co którzy są nieprzewidywalni. Może to właśnie ty?
z- 23
- #
- #
- #
- #
- #
Kurs algorytmiki na Khan Academy współautorstwa Thomasa Cormena
http://cs-blog.khanacademy.org/2014/11/teaching-algorithms-on-khan-academy.html
bezpośrednio
Given how important algorithms are, we were elated when Dartmouth professors Thomas Cormen and Devin Balkcom suggested writing an online course on Algorithms, available to anyone for free, forever, on Khan Academy. If you’re a college CS student, you might recognize the name “Cormen” - he’s the “C” in the “CLRS”-authored Algorithms textbook, the most popular algorithms textbook used by college classes.
http://cs-blog.khanacademy.org/2014/11/teaching-algorithms-on-khan-academy.html
bezpośrednio
@aseeon: Akurat z podstaw algorytmów to można w internecie naprawdę dużo znaleźć. Mimo wszystko fajnie, że temat pojawia się na takim dużym serwisie ;)
naprawdę dużo znaleźć
@Sedd: Nie powinno się liczyć na ilość tylko na jakość! (⌐ ͡■ ͜ʖ ͡■)
A tak to jasne, że to nie jedyny kurs algorytmiczny w internecie, ale zawsze miło gdy pojawia się konkurencja w temacie, szczególnie gdy pracowali nad nią mądrzy ludzie.



#informatyka #algorytmy #studbaza #kiciochpyta
Instancje Taillarda.
Skoro w modelu open shop zachodzi pełna dowolność, czemu w instancjach jest jakaś kolejność (po co są dwie tabelki danych wejściowych, mogłaby być jedna) i jak to interpretować (w wierszach są nr maszyn czy zadań)?
http://mistic.heig-vd.ch/taillard/problemes.dir/ordonnancement.dir/openshop.dir/tai5_5.txt
Instancje Taillarda.
Skoro w modelu open shop zachodzi pełna dowolność, czemu w instancjach jest jakaś kolejność (po co są dwie tabelki danych wejściowych, mogłaby być jedna) i jak to interpretować (w wierszach są nr maszyn czy zadań)?
http://mistic.heig-vd.ch/taillard/problemes.dir/ordonnancement.dir/openshop.dir/tai5_5.txt


Mając mała ilość pamięci RAM ( w jednym momencie możemy w niej przechowywać max 1000 elementów) zaproponuj najbardziej efektywny algorytm sortowania tablicy zawierającej milion elementów.
Nic mi nie przychodzi do głowy odkrywczego. Ma ktos może jakiś pomysł ?
#algorytmy #informatyka #pytanie
Nic mi nie przychodzi do głowy odkrywczego. Ma ktos może jakiś pomysł ?
#algorytmy #informatyka #pytanie


Wykopki, jak nazywa się algorytm użyty np w grze, w której z zadanego zakresu wybieram liczbę i komputer ją zgaduję wybierając liczbę ze środku przedziału, itd?
#informatyka #algorytmy
#informatyka #algorytmy

@JezelyPanPozwoly: dziel i zwyciężaj - choć konkretniej to wyszukiwanie binarne :)
@JezelyPanPozwoly: Metoda bisekcji?

@Mayki: Napisałeś to w taki sposób, że wątpię, żeby ktokolwiek zrozumiał pytanie.

#programowanie #algorytmy
Wybaczcie brak polskich znakow, niestety nie mam ich tu. Mam za to z pozoru trywialny problem algorytmiczny (albo okresowa zacme). Dla osob z zapleczem edukacyjnym powinna to byc blachostka.
Bardziej niz gotowe rozwiazanie docenie info co powinienem zgooglowac, jak sie problem/zagadnienie nazywa, bo zaloze sie ze nie jestem pierwszym, ktory sie nad tym glowi :)
to
Wybaczcie brak polskich znakow, niestety nie mam ich tu. Mam za to z pozoru trywialny problem algorytmiczny (albo okresowa zacme). Dla osob z zapleczem edukacyjnym powinna to byc blachostka.
Bardziej niz gotowe rozwiazanie docenie info co powinienem zgooglowac, jak sie problem/zagadnienie nazywa, bo zaloze sie ze nie jestem pierwszym, ktory sie nad tym glowi :)
to

@denwood: możesz zacząć od http://en.wikipedia.org/wiki/Sparse_matrix
@paziu: domyslam sie, a optymalne byc musi.. Pisze juz do siorki z matrycami, moze ona cos wynajdzie tez.
Tablice pomocnicze to bardzo dobry pomysl, ale obawiam sie, ze zamieszanie moze byc mocno duze, gdy
a) na uklad tablicy
Tablice pomocnicze to bardzo dobry pomysl, ale obawiam sie, ze zamieszanie moze byc mocno duze, gdy
a) na uklad tablicy

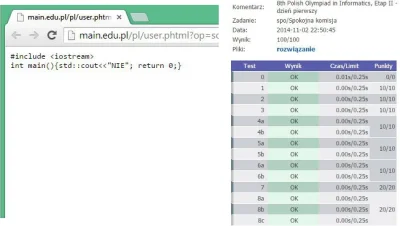
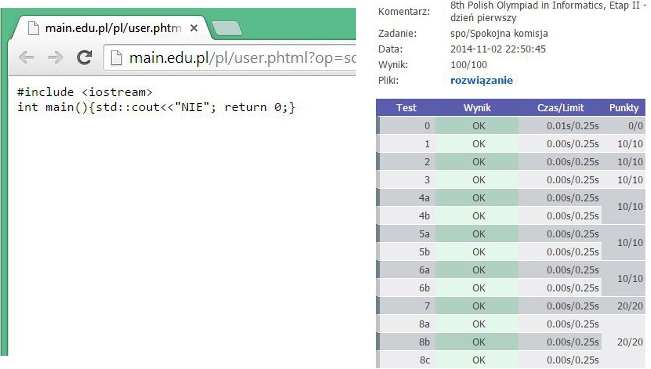
Po wielu godzinach pisania kodu, doszedłem do takiego rozwiązania skomplikowanego zadania algorytmicznego z użyciem grafów dwudzielnych.
#politechnikalodzka #algorytmy #programowanie
#politechnikalodzka #algorytmy #programowanie
źródło: comment_wBjU9ViwKq16egECVBG0mQUrOroPXWN1.jpg
Pobierz


#programowanie #java #algorytmy
jak wypełnić dwuwymiarową tablicę o dowolnej wielkości zgodnie z takim wzorem:
0 1 2
0
jak wypełnić dwuwymiarową tablicę o dowolnej wielkości zgodnie z takim wzorem:
0 1 2
0
@parsiuk: @PuffinusGravis:
Rozwiązanie zagadki:
http://pastebin.com/FKvG1jBz
co prawda maciez jest odwrotna ale styknie :)
Rozwiązanie zagadki:
http://pastebin.com/FKvG1jBz
co prawda maciez jest odwrotna ale styknie :)
Nauka rekurencji poprzez naukę rekurencji
- 5
- #
- #
- #
Zajmuje się ktoś programowaniem na platformie Force.com ? Salesforce to produkt bardzo młody, interesujące podejście do programowania, zarobki zajebiste, wymagania też nie mniejsze. Właśnie przechodzę na 1,5msc bezrobocie w związku ze zmianą firmy gdzie będę się starał o stanowisko junior salesforce dev'a, dostałem materiały z którymi mam się zapoznać i przedstawić na rozmowie kwalifikacyjnej.
Mam sporo pytań dotyczących tej platformy, także ponawiam pytanie są Developerzy SalesForce' na wypoku ?
#java
Mam sporo pytań dotyczących tej platformy, także ponawiam pytanie są Developerzy SalesForce' na wypoku ?
#java

to już bardziej aktualne logo :)

źródło: comment_AGwKMooJvFunNSP6fpjItZ97QknoGPs8.jpg
Pobierz
sprawdzam pocztę z rana, a tam jakaś oznaczona jako 'ważna' wiadomość, na dobrą sprawęnie było to nic istotnego ale oznaczenie mnie zdziwiło więc kliknęłam a tam taka sytuacja...
#poczta #gmail #waznawiadomosc #algorytmy
#poczta #gmail #waznawiadomosc #algorytmy

źródło: comment_hwvdJrZttMhz5tjGIN2BMEHnyKE3AVQ9.jpg
PobierzWizualizacje algorytmów i struktur danych - http://visualgo.net/
#programowanie #algorytmy #informatyka #sieci
#programowanie #algorytmy #informatyka #sieci

źródło: comment_QeTxz0ExQ5p9lvuYE0WtVkdcKyX56tmt.gif
Pobierz
Uwaga! Ważna informacja dla programistów. Tej nocy zegarki przestawiamy z godziny trzeciej na drugą JEDEN RAZ. Nie dajcie się zapętlić!
#programowanie #algorytmy #hahaszki
#programowanie #algorytmy #hahaszki
@wbielak: Uwaga! Ważna informacja dla śmieszków. Tej nocy trafiamy na #czarnolisto

@fotexxx: nie przesadzasz trochę? :( Why so serious?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Potrzebuję pomocy, muszę stworzyć schemat blokowy i krokowy. Oto wymagania: 1 - dodawanie, 2 - odejmowanie, 3 - mnożenie, 4 - dzielenie, 0 - zakończ program. Chodzi mniej więcej, żeby po naciśnięciu odpowiedniej liczby program wykonał przydzielone mu zadanie (dodawanie, odejmowanie, mnożenie, dzielenie). #komputery #schematy #programowanie #algorytmy
no i?
prosty kalkulator - co tu za wyzwanie?
prosty kalkulator - co tu za wyzwanie?
@sircoran: czyli mamy lekcje za ciebie odrabiać
zacząłeś w ogóle cokolwiek szukać, pouczyłeś sie, wiesz co to jest algorytm, schemat blokowy i krokowy?
pokaż co zrobiłeś, może ktoś zechce ci pomóc a nie zrobić za ciebie
zacząłeś w ogóle cokolwiek szukać, pouczyłeś sie, wiesz co to jest algorytm, schemat blokowy i krokowy?
pokaż co zrobiłeś, może ktoś zechce ci pomóc a nie zrobić za ciebie
#gif #algorytmy #sortowanie trochę #matematyka, trochę #informatyka, może kogoś z #programowanie też zainteresuje ( ͡° ͜ʖ ͡°)
źródło: comment_sK2CSZzmeYJw98iNOr7LBzl3ff7Dp8Em.jpg
Pobierz