Treść przeznaczona dla osób powyżej 18 roku życia...



Będę wredny, a co mi tam - crudziarze się boją że w niedalekiaj przyszłości zostąpi ich AI. A w każdej chwili może zastąpić ich losowy Hindus, tylko dlatego że będzie tańszy.
#programowanie #programista15k #pracait
#programowanie #programista15k #pracait
pa6lo via Wykop
Chyba przespałeś erę outsoursingu do Indii jakieś 10 lat temu, spoiler alert - nie sprawdziło się
@OlekAleksander @groman43: W Londynie coraz więcej startupów zatrudnia lokalnie tylko garstkę pierdzistołków, zespoły techniczne pracują zdalnie z najtańszych krajów. To nie jest klasyczny outsourcing ale zatrudnianie (kontraktowanie) najbardziej zdolnych i wykształconych jednostek do pracy pod bezpośrednim nadzorem centrali.
pa6lo via Wykop
Tak, ale te tańsze kraje to coraz częściej Polska czy Rumunia.
@OlekAleksander: Wręcz przeciwnie. Polacy już od lat nie konkurują ceną lecz doświadczeniem i dostępnością. Specjalistów z krajów azjatyckich można zatrudnić za £20-30k rocznie.

źródło: Bez tytułu
Pobierz
pa6lo via Wykop
Gdyby to była "sztuczna inteligencja", to ten czat miałby samoświadomość
@supra107: Definicje "sztucznej inteligencji" nie zawierają wymagań dot. samoświadomości.
pa6lo via Wykop
Gdyby takie dziennikarzyny mówiły o "uczeniu maszynowym"
@supra107: Poniekąd masz rację, że termin AI został mocno nacechowany przez pop-kulturę i dziennikarzy technologicznych w przeciągu ostatnich dekad. Rok temu istniała szansa na wypromowanie bardziej precyzyjnego termin typu "machine learning" czy "deep learning", ale serwisy informacyjne wybrały słowo-klucz: AI. Podejrzewam, że powodem był gotowy skrótowiec (AI), na których punkcie anglojęzyczni mają lekką obsesję.

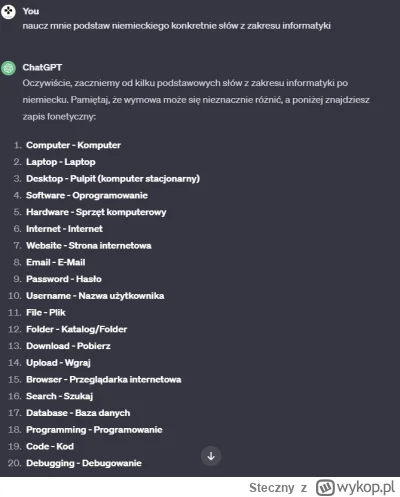
ChatGPT staje się gorszy i gorszy. Używam często jak mam zrobić jakieś żmudne rzeczy bo szybciej wytlumaczyc, wkleic co ma zrobic i zostawic na kilka minut. Zawsze wszystko było spoko. Teraz zauważam że często zrobi źle, musze kilka razy tłumaczyć, czasem już w ogóle nie pamięta wcześniejszych wiadomości w danej rozmowie itp. Chyba czas anulować subskrybcje bo bez sensu to się robi.
#programowanie #chatgpt #programista15k
#programowanie #chatgpt #programista15k
pa6lo via Wykop
tworzą firmy w oparciu o zapytania do api lub wręcz dialog w czacie.
@AntyKuc @JamesJoyce W ostatnim roku nastąpił wysyp "produktów" opartych w całości na OpenAI API i zakodowanych w jeden weekend przy pomocy Chat GPT.

źródło: gpt-business
Pobierz
pa6lo via Wykop
Open AI zaszalało z cenami to te firmy są w stanie na własnej infrastrukturze postawić LLMa jakiegoś żeby funkcjonować?
@AntyKuc: Zmiana cennika zamiata większość takich firm-krzaków. Wyróżniam dwie kategorie grifterów, oferujących "produkt", gdzie każde zapytanie użytkownika jest przekierowane do OpenAI.:
1. Plankton, czyli jednostki usiłujące zaistnieć w biznesie z jakimś gównianym SaaS zrobionym w jeden weekend w oparciu o gotowe rozwiązania sklejone przy pomocy


źródło: Zdjęcie z biblioteki
Pobierz
pa6lo via Wykop
@JamesJoyce: Przykład jajogłowego pokazuje, że można być światowej klasy naukowcem i interdyscyplinarnym geniuszem a jednocześnie przejawiać naiwność dziecka w kwestii mechanizmów władzy.
#programista15k #programowanie #it #chatgpt #sztucznainteligencja #filozofia
Ciekawe jak google poradzi sobie z nawałnicą syntetycznego kontentu, który szturmuje internet od momentu udostępnienia ChatuGPT i kolejnych modeli. Faktem jest bowiem, że od połowy 2023 r. korpus ludzkiej wiedzy będzie musiał być traktowany zasadniczo inaczej niż przed 2023. Scrappowanie danych z mediów społecznościowych, google image czy czegokolwiek innego obecnie może zniszczyć cały utworzony dataset.
Ciekawe jak google poradzi sobie z nawałnicą syntetycznego kontentu, który szturmuje internet od momentu udostępnienia ChatuGPT i kolejnych modeli. Faktem jest bowiem, że od połowy 2023 r. korpus ludzkiej wiedzy będzie musiał być traktowany zasadniczo inaczej niż przed 2023. Scrappowanie danych z mediów społecznościowych, google image czy czegokolwiek innego obecnie może zniszczyć cały utworzony dataset.
pa6lo via Wykop
Moim zdaniem watermarki typu "human generated" mogą sporo zyskać na wartości. Podobnie, jak, uwaga, uwaga, kod czy program lub inny obiekt informatyczny, przygotowany i supportowany przez ludzi.
Tak, w przypadku twórczości literackiej czy dziennikarskiej, gdzie autor czerpie z rzeczywistości, używając empatii i zmysłu obserwacji. Użycie narzędzi AI do przeformułowania zdania czy dobrania synonimu nie umniejsza wartości dzieła.
Porównajmy to z językiem marketingu, który współcześnie nie przekazuje żadnych informacji tylko puste komunikaty. Dla odbiorcy taki
pa6lo via Wykop
ale jak oznaczyć, które dane są prawdziwe a które nie?
@JamesJoyce: W przypadku stron, podejrzewam, że Google czy Bing będą rozwijać system reputacji źródeł. W przyszłości może być taki natłok treści syntetycznych, że nikt nie będzie chciał ich indeksować a uwzględnienie URI w rezultatach wyszukiwania będzie przywilejem. Może wtedy SEO jako dyscyplina będzie do czegoś przydatna?
Jeśli chodzi o datasety, to domyślam się, że era darmowych, tudzież "pożyczonych" danych dobiega
pa6lo via Wykop
Te dane przecież były "darmowe" bo nie ma jeszcze przepisów dotyczących ich komercjalizacji,
@JamesJoyce: Nie znam się na prawie własności intelektualnej więc mogę jedynie gdybać. Obecnie mamy do czynienia usunięciem na żądanie, tj. będąc autorem dzieła musisz wysłać wniosek o wykluczenie ze zbioru. Ciekawe, czy i kiedy prawo zacznie wymagać ogarnięcia kwestii własności danych przed procesem trenowania modelu?
Następnie, czy prawo wystarczy, a może rozwiną się techniki anty-scrappingowe a z
pa6lo via Wykop
kojarzy mi się z piractwem komputerowym na sterydach.
@vateras131: Trafna uwaga. Zanim prawo ogarnie tę kwestię, to wiele podmiotów zdąży utuczyć się na kradzionym, jak dawniej handlarze z Grzybowskiej. Mając pierwsze modele gotowe, będą oni krzyczeć najgłośniej o etyce w AI i potrzebie regulacji dostępu do danych treningowych.
Dodatkowo sprawa z Deviant Art pokazuje potrzebę zmian w kwestii własności materiałów publikowanych przez użytkowników, do których serwis rości sobie wyłączne prawo.

Świeże plotki ze światka AI mówią, że podobno szykuje się nam przełom w sztucznej inteligencji (Open AI).
"Tuż przed usunięciem Sama Altmana, kilku naukowców OpenAI napisało list do rady dyrektorów, ostrzegając przed potężnym odkryciem w dziedzinie sztucznej inteligencji, które może zagrozić ludzkości" (Reuters)
"Za 3 lata wszyscy będziemy martwi, albo będziemy mieli boga jako służącego" (Siqi Chen na X)
"OpenAI
"Tuż przed usunięciem Sama Altmana, kilku naukowców OpenAI napisało list do rady dyrektorów, ostrzegając przed potężnym odkryciem w dziedzinie sztucznej inteligencji, które może zagrozić ludzkości" (Reuters)
"Za 3 lata wszyscy będziemy martwi, albo będziemy mieli boga jako służącego" (Siqi Chen na X)
"OpenAI

źródło: 123
Pobierz
pa6lo via Wykop
Cała drama z OpenAI Samem i zarządem to spór o to, że powstalo AGI i jedni chcą jak najszybciej to zmonetyzować (...), a inni stawiają mocno na security
@nad__czlowiek: Myślałem podobnie w sobotę, nawet nazwałem to tutaj "starciem pragmatyków z idealistami". W idealizm Sutskevera mogę uwierzyć, ale nie w to, że cwaniak D'Angelo oraz dwie karierowiczki Toner i McCauley odwaliły taki cyrk w trosce o przyszłość ludzkości. Wydaje mi

{kind=link}
{kind=link}
{kind=link}
{kind=link}
WTF?
▶️ Obejrzyj tę rolkę https://www.facebook.com/share/r/abycn6nYcP151eDt/?mibextid=UalRPS
#mlm #frajerzyzmlm #frajerzymlm
▶️ Obejrzyj tę rolkę https://www.facebook.com/share/r/abycn6nYcP151eDt/?mibextid=UalRPS
#mlm #frajerzyzmlm #frajerzymlm
#programista15k #programowanie #openai #chatgpt
Brockman tez odchodzi z OpenAI, wraz z częścią inżynierów wysokiego lvl. Pewnie założy z Altmanem nową firmę. Najbliższe miesiące dla OpenAI pewnie będą bardzo nerwowe, by utrzymać się na powierzchni i nie dać się zjeść przez Microsoft.
Bunt robotów oficjalnie opóźniony.
Brockman tez odchodzi z OpenAI, wraz z częścią inżynierów wysokiego lvl. Pewnie założy z Altmanem nową firmę. Najbliższe miesiące dla OpenAI pewnie będą bardzo nerwowe, by utrzymać się na powierzchni i nie dać się zjeść przez Microsoft.
Bunt robotów oficjalnie opóźniony.

źródło: Zdjęcie z biblioteki
Pobierz{kind=link}
pa6lo via Wykop
@JamesJoyce: Trudno powiedzieć, Axios twierdzi, że coup udał się zanim MS zdążył zauważyć. Na Reddicie panuje przekonanie, że to było starcie pragmatyków (Altman) z idealistami (Sutskever) w kwestii tego co i kiedy nazwać AGI - ponoć ma to kluczowe znaczenie w relacjach z MS.
Chodzi o to, że po co mam marnować czas na rekrutacje, kiedy z góry wiadomo, że jestem za słaby, lepiej się w tym czasie dokształcić.
Nie będę pisał ile to poradników i książek nie przerobiłem, bo to chyba nie ma sensu, może opiszę projekty które zrobiłem na własny użytek, pomijając te
@ozzi91: Z tego co piszesz wynika, że już pracujesz w jakiejś technicznej branży, być może zgodnej z Twoim wykształceniem. Sugeruję, aby zamiast całkowitego przebranżowienia się, ewoluować w stronę digital transformation i SWE w ramach swojej dyscypliny. Zaplecze w postaci kontaktów i doświadczenia w konkretnym sektorze jest bezcenne. Z pewnością