Wszystko
Najnowsze
Archiwum



Hej, mam zaćmienie umysłu, a muszę w pracy napisać kwerendę w Accessie która obliczy mi łączną długość odcinków.
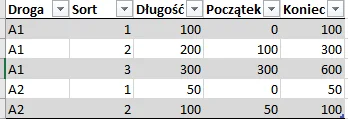
Droga jest podzielona na odcinki (Sort), każdy sort ma swoją długość, sort 1 zaczyna się od 0, i kończy na długości, ale sort 2 powinien zaczynać się od końca odcinka 1. Jak to mądrze zrobić? Mam problem z pobieraniem wartości z poprzednich rekordów. Narysowałem w Excelu o co mi konkretnie chodzi
#access
Droga jest podzielona na odcinki (Sort), każdy sort ma swoją długość, sort 1 zaczyna się od 0, i kończy na długości, ale sort 2 powinien zaczynać się od końca odcinka 1. Jak to mądrze zrobić? Mam problem z pobieraniem wartości z poprzednich rekordów. Narysowałem w Excelu o co mi konkretnie chodzi
#access
źródło: comment_1612767941xtiyDjBvSibYW4HqlU8bnL.jpg
Pobierz
To są tzw. running totals - i tego poszukaj w necie. Najpierw zrób formułę do "koniec", a początek zrobisz jako Koniec - długość @JaTobieTyMi:

1. Jak w #sqlserver ograniczacie użytkownikom dostęp po adresie IP?
W postgresie mam plik pg_hba.conf i tam sobie wpisuje użytkowników , bazy i dozwolone adresy IP. Dzięki temu daję dostęp do danej bazy niektórym użytkownikom z ograniczonymi uprawnieniami do tabel i mam pewność, że zdalnie nawet nie będzie mógł próbować zgadywać hasła do użytkownika postgres.
2. Jaki sens w #sqlserver ma autoryzacja użytkownikami z windowsa jeśli nie mam domeny AD?
W postgresie mam plik pg_hba.conf i tam sobie wpisuje użytkowników , bazy i dozwolone adresy IP. Dzięki temu daję dostęp do danej bazy niektórym użytkownikom z ograniczonymi uprawnieniami do tabel i mam pewność, że zdalnie nawet nie będzie mógł próbować zgadywać hasła do użytkownika postgres.
2. Jaki sens w #sqlserver ma autoryzacja użytkownikami z windowsa jeśli nie mam domeny AD?
@nietrolluje: nie, po prostu kiedyś łączyłem się przez L2TP i nie rozwiązywało mi nazw przez co nie mogłem połączyć się z serwerem sql ale lokalnie działało ok
@100x:
1. 4. jak chcesz po ip na windowsym firewallu do portu sqlowego. Trochę bezsensowne jest identyfikowanie userów po IP bo do sql servera możesz się łączyć nie tylko przez tcp/ip ale też przez shared memory, named pipes. Userzy też mogą mieć dynamiczne ip, różne podsieci, vpny itd.
2. żaden, jak nie ma AD to lepiej uzywać sql serverowej authentication mode (mixed) i utworzyć sobie sqlowego usera sa.
3. możesz
1. 4. jak chcesz po ip na windowsym firewallu do portu sqlowego. Trochę bezsensowne jest identyfikowanie userów po IP bo do sql servera możesz się łączyć nie tylko przez tcp/ip ale też przez shared memory, named pipes. Userzy też mogą mieć dynamiczne ip, różne podsieci, vpny itd.
2. żaden, jak nie ma AD to lepiej uzywać sql serverowej authentication mode (mixed) i utworzyć sobie sqlowego usera sa.
3. możesz

#sql #bazydanych
Chcę zrobić zapytanie
SELECT foo * bar as foobar
FROM someTableWhichHasFoo
WHERE foobar > 5
Chcę zrobić zapytanie
SELECT foo * bar as foobar
FROM someTableWhichHasFoo
WHERE foobar > 5
@JaTobieTyMi: nie da się podać aliasu w w WHERE. Możesz zrobić to na dwa sposoby
1.
SELECT foo * bar as foobar
1.
SELECT foo * bar as foobar
@JaTobieTyMi: zrobiłem to pierwsze. Dzięki za potwierdzenie, że się nie da. Pisałem egzamin i wiem, że zrobiłem dobrze tą część
Zamiast stosować przewidywalne, inkrementowane identyfikatory w tabelach bazy danych zaleca się często, ze względów bezpieczeństwa, używanie tzw. #uuid, czyli unikalnych identyfikatorów tekstowych. Taki klucz w tabeli maksymalnie niweluje skuteczność ataków ☠️ polegających na kolejnym odpytywaniu URL, zwiększając jedynie parametr ID o jeden.
Na przykładzie #php i #laravel zademonstruję sposób na użycie UUID.
A czy Ty używasz UUID w swoim projekcie?
Na przykładzie #php i #laravel zademonstruję sposób na użycie UUID.
A czy Ty używasz UUID w swoim projekcie?

źródło: comment_1612454863KAux8tRtsBdojzAWuKtSXq.jpg
Pobierz@Serghio: @Serghio: Mam doświadczenie w projekcie gdzie poprzednik zaczął stosować uuid oraz id (id był podstawowy)
uuid wypływało zawsze na zewnątrz, do jakiegoś get itd.
obowiązywała jednocześnie zasada aby id nigdy nie było widoczne nigdzie na froncie, id używaliśmy tylko do komunikacji pomiędzy wywołaniami na backendzie.
uuid wypływało zawsze na zewnątrz, do jakiegoś get itd.
obowiązywała jednocześnie zasada aby id nigdy nie było widoczne nigdzie na froncie, id używaliśmy tylko do komunikacji pomiędzy wywołaniami na backendzie.

@Serghio: @szczesc_borze: ostatnio mi wystarczyła informacja ile zamówień tygodniowo posiada pewna firma gdzie numer zamówienia jest autoincrement, wystarczyło złożyć dwa zamówienia w przeciągu tygodnia i wiedziałem
ps. to może ulid? nie rozwala tak bazy przy insercie
ps. to może ulid? nie rozwala tak bazy przy insercie

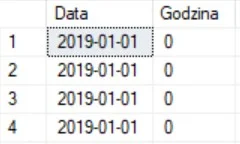
tabela wyglada tak, kolumna timestamp i godzina w int
jak sformułować zapytanie aby w wyniku mieć to w jednej kolumnie w formacie analogicznym do datetime2(0)? #naukaprogramowania #sql #bazydanych
jak sformułować zapytanie aby w wyniku mieć to w jednej kolumnie w formacie analogicznym do datetime2(0)? #naukaprogramowania #sql #bazydanych
źródło: comment_1612363810OlHUX7pnuTr0Zr9nZK3nUs.jpg
Pobierz
Nie jestem typowym korpo-programistą 15k, ale zrobiłem w życiu parę projektów. Większość z nich było oparte na relacyjnych bazach danych głównie mysql.
Od kilku lat robię też projekty oparte na mongoDB i choc na początku zauroczyła mnie ich prostota to stwierdzam, że przy większych projektach relacyjna baza daje większą kontrolę a mongo prowadzi do chaosu (chyba że zostaną zaimplementowane relacje co chyba mija się z celem nierelacyjnych baz danych).
Ciekawi mnie wasza
Od kilku lat robię też projekty oparte na mongoDB i choc na początku zauroczyła mnie ich prostota to stwierdzam, że przy większych projektach relacyjna baza daje większą kontrolę a mongo prowadzi do chaosu (chyba że zostaną zaimplementowane relacje co chyba mija się z celem nierelacyjnych baz danych).
Ciekawi mnie wasza

@brightit: tak jest, kiedy próbujesz używać noSQL jako zastępnika bazy SQL. Do normalnych case raczej używa się SQL, a NoSQL do np. zbierania nieregularnych danych, które następnie wymagają np. analizy. Takimi nieregularnymi danymi mogą być np. logi.
@brightit: cassandra/dynamoDB sobie zobacz jesli nie znasz i elastic tez bardzo warto znac
Change Data Capture - Zmień Bazę W Strumień (Debezium) - Wiadro Danych

Myślałeś/aś kiedyś o utworzeniu strumienia z operacji w bazie danych? W tym wpisie dowiesz się czym jest Change Data Capture i jak go wykorzystać planując architekturę naszego systemu.
z- 0
- #
- #
- #
- #
- #
- #
Potrzebuje pomocy od kogoś kto ogarnia sql. Mam mały projekt i nie umiem zbytnio napisać selecta w bazie. Oczywiście odwdzięczę się ;) Proszę priv, jak ktoś się zna to robota na 5 min.
#sql #mssql #bazydanych #pomocy #programowanie #programista15k
#sql #mssql #bazydanych #pomocy #programowanie #programista15k

@JesMan: wrzuć co trzeba zrobić
Koliedzy, jaką bazę byście użyli do zapisywania notowań giełdowych z aplikacji streamującej, a jakiej do przechowywanie portfela klienta?
W 1 przypadku będziemy mieli:
timestamp, kod instrumentu finansowego, kod waluty, cenę
W 2 przypadku:
W 1 przypadku będziemy mieli:
timestamp, kod instrumentu finansowego, kod waluty, cenę
W 2 przypadku:
@r4do5: nie dostałem tylko doliczyłem bony na święta, owoce, kursy i premię

@programista5k2: Ogólnie ja bym szedł w TimescaleDB, bo to "tylko" rozszerzenie Postgresa, więc masz wszystko co w Postgresie + TSDB, czyli w 99.9% przypadków wystarcza do wszystkiego.
#sql #programowanie #programista15k #bazydanych #mssql #tsql
Pytanie do lokalnych ekspertów.
Mam taką sytuację, że:
Mam listę zleceń,
Pytanie do lokalnych ekspertów.
Mam taką sytuację, że:
Mam listę zleceń,
@daloma lepszym rozwiązaniem byłoby wykonanie procedury i zapis do tabeli?

@automatykwformie: baza raczej nawet nie w pierdnie chyba że jest tego na prawdę dużo.
Jak dużo to widok indeksowany j/w albo wyliczanie tego do tabeli na boku przy użyciu trigerow create update delete
Jak dużo to widok indeksowany j/w albo wyliczanie tego do tabeli na boku przy użyciu trigerow create update delete
mam kilka calkiem sporych #bazydanych jakosci powietrza z jednego roku kalendarzowego i chcialbym zrobic analize zeby te dane porownac. potrafie troche w #powerbi troche w #python mniej w #R baza ma pomiary wykonywane co godzine w kilkuset roznych lokalizacjai w polsce. jakie fajne zestawienia mozna zrobic zeby jak najwiecej rzeczy wykazac? dopiero sie ucze wiec #naukaprogramowania

@rosso_corsa: najlepiej wizualizacje zmian na mapie (plamki) w czasie?
Zależy głównie co chcesz pokazać.
Zależy głównie co chcesz pokazać.
@rosso_corsa: Zrób zmienność jakości w czasie dla danej lokalizacji, zobacz czy ludzie dzielą to czym palą na wsad dzienny (czystszy) i nocny (brudny). Narzuć na to też dane o temperaturze i siłę wiatru. Postaraj się przewidzieć na podstawie takich danych jaka będzie jakość jutro oraz co ma największy wpływ - godzina, temperatura, wiatr?

Czołem Mirki i Mirabelki
Dziś nowy kurs z tematyki #bazydanych #oracle i #sql dla średniozaawansowanych jak i początkujących:
Tabela zorganizowana według indexu (ang. Index-Organized Tables)
W kursie:
* Opisuję czym są IOT
* Przedstawiam ich struktórę i porównuję ją do zwykłego indexu B-tree oraz tabeli
Dziś nowy kurs z tematyki #bazydanych #oracle i #sql dla średniozaawansowanych jak i początkujących:
Tabela zorganizowana według indexu (ang. Index-Organized Tables)
W kursie:
* Opisuję czym są IOT
* Przedstawiam ich struktórę i porównuję ją do zwykłego indexu B-tree oraz tabeli

Treść przeznaczona dla osób powyżej 18 roku życia...
@programista5k2: wirtualka z linuxem i cassandra w dockerze to jedna komenda leniu ty :p
Koliedzy jak nazwać profesjonalnie tabele w której będę przechowywać logi ze zmian tej tabeli oraz logi odczytów?
changeLog i readLog? logChange i logRead? logsChange i logsRead? ...
ech
#programowanie #bazydanych
changeLog i readLog? logChange i logRead? logsChange i logsRead? ...
ech
#programowanie #bazydanych
@programista5k2:
read_logs, change_logs@programista5k2: Po pierwsze załóż bazę Configuration, która będzie przechowywać zmiany, logi, i wszelkie dane, które nie podlegają dosłownej integracji a są np z góry ustalone, zidentyfikowane. Następnie w tej bazie stwórz schematy typu log, data, dics itd itd. Nie pytaj się o nazwę tylko pomyśl jak miałaby wyglądać cała struktura tak aby Tobie to ułatwiło pracę.

Potrzebuję zrobić #hurtowniedanych w #sqlserver ale jako narzędzie do #etl służy mi #spark, a konkretnie #pyspark
Macie może jakieś dobre materiały albo przykładowe kody, żeby podejrzeć jakieś dobre praktyki?
Jak ogarnąć slow changing dimension? Metadane itp.?
Macie może jakieś dobre materiały albo przykładowe kody, żeby podejrzeć jakieś dobre praktyki?
Jak ogarnąć slow changing dimension? Metadane itp.?
@inny_89: Z doświadczenia to całe zasilanie powinno się odbywać w dwóch krokach Source - Extract, Extract - Stage. Oczywiście mówię o hurtowni zasilanej raz na dobę nocną porą.
1. Source - Extract - truncate docelowych tabel i zasilenie ze źródła. Tak jest najszybciej. Nawet jak masz tabele do 100 mln rekordów. Z produkcji zasilamy dane tak szybko jak to jest możliwe.
2. Extract - Stage - zasilenie przyrostowe. I tu już można
1. Source - Extract - truncate docelowych tabel i zasilenie ze źródła. Tak jest najszybciej. Nawet jak masz tabele do 100 mln rekordów. Z produkcji zasilamy dane tak szybko jak to jest możliwe.
2. Extract - Stage - zasilenie przyrostowe. I tu już można
@inny_89: https://stackoverflow.com/questions/38487667/overwrite-specific-partitions-in-spark-dataframe-write-method
Ustawia się to jedną linijką w configu:
Ustawia się to jedną linijką w configu:
spark.conf.set("spark.sql.sources.partitionOverwriteMode","dynamic")Wybacz też wysoki poziom abstrakcji przy opisywaniu

#anonimowemirkowyznania
#sql #pomocy #porada
Cześć,
muszę napisać z anonima, żeby mnie nikt nie skojarzył.
Obecnie skończyłem inżyniera z mechaniki. Studia fajne, ale nie umiem nic ciekawego sobie znaleźć. Pracuję obecnie w firmie, zajmuję się specyfikacjami technicznymi urządzeń i kontaktem z klientem (zagranica). Robota niby całkiem okej, ale brak nowych wyzwań powoduje u mnie nudę.
Chciałbym się z czegoś przeszkolić, poszukać sobie innego zajęcia, które spowoduje, że znajdę
#sql #pomocy #porada
Cześć,
muszę napisać z anonima, żeby mnie nikt nie skojarzył.
Obecnie skończyłem inżyniera z mechaniki. Studia fajne, ale nie umiem nic ciekawego sobie znaleźć. Pracuję obecnie w firmie, zajmuję się specyfikacjami technicznymi urządzeń i kontaktem z klientem (zagranica). Robota niby całkiem okej, ale brak nowych wyzwań powoduje u mnie nudę.
Chciałbym się z czegoś przeszkolić, poszukać sobie innego zajęcia, które spowoduje, że znajdę

@AnonimoweMirkoWyznania: Obie drogi jakie rozważasz mogą być potencjalnie tak samo nudne jak to co teraz robisz. Sam robie w bazadanych ale jakoś administrator/helpdesk i tu jest jeszcze jakaś rozrywka bo nigdy nie wiesz na co klient wpadnie.
W mechanice może warto abyś rozejrzał się za jakimś projektowaniem - znajomy pracował w Instytucie lotnictwa w centrum projektowym dla GE i co kilka mce wyjazdy albo Anglia albo RPA(mieli kontrakty na instalacje
W mechanice może warto abyś rozejrzał się za jakimś projektowaniem - znajomy pracował w Instytucie lotnictwa w centrum projektowym dla GE i co kilka mce wyjazdy albo Anglia albo RPA(mieli kontrakty na instalacje
jak sie robi integracje danych w wiekszych systemach, sa do tego jakies narzedzia czy sie robi dedykowane rozwiazania? #bazydanych #naukaprogramowania

{kind=link}
{kind=link}
{kind=link}
{kind=link}
@rosso_corsa: jak Warehouse obsługuje ten sam typ bazy danych to można próbować bez narzędzi, ale jak masz różne to pisanie narzędzia na nowo jest bez sensu. Wybierz jakieś gotowe
Treść przeznaczona dla osób powyżej 18 roku życia...
jakimi sposobami mozna pobrac #bazydanych mssql np do pliku csv? korzystalem tylko z ssms #naukaprogramowania
baza danych do csv? Musisz exportować każdą tabelę osobno.
@rosso_corsa: bulk export?
- Hurtownie danych. Od przetwarzania analitycznego do raportowania
- Modelowanie danych
- Korporacyjne jezioro danych. Wykorzystaj potencjał big data w swojej organizacji
#hurtowniedanych #bazydanych #sql #it