
Treść przeznaczona dla osób powyżej 18 roku życia...
Wszystko
Najnowsze
Archiwum

@Wykopaliskasz: Dziękujemy za zgłoszenie. Zalecamy, żebyś zastąpił to słowo innym. Obecnie to jedyne rozwiązanie.

@allegro_pl: a jakie proponujecie w zamian? xD

polecacie jakies fajne narzedzie do narysowania kilku grafow? #algorytmy #informatyka

@heater: graphviz
@ZdeformowanyKreciRyj: no widze, ze wyglada to jak pisane do linuxa, znalazlem jakis inny bieda programik online

jak zrobić taki algorytym w jednym zapytaniu. Mam 2 listy, muszę sprawdzić czy lista zawiera 2 elementy, w tym jeden jest obligatoryjny.
przykład w kodzie:
https://paste.ofcode.org/9cfLpPspAZGpUPw2KDzEnP
#java #programowanie #algorytmy
przykład w kodzie:
https://paste.ofcode.org/9cfLpPspAZGpUPw2KDzEnP
#java #programowanie #algorytmy

Mireczki potrzebuje algorytm, który realizuje takie zadanie. Na przykład mam trzy liczby: 5, 10, 15. Dla liczby 37 będę dostawał kombinacje jak te:5x8, 15x2+10, 15x2+5x2, 10x3+5x2, 10x4. Dla 13 będzie podobnie: 15x1, 5x3, 10x1+5. Jak szukać takiego algorytm? Rozumiem, że to jakaś forma optymalizacji, rozkład na czynniki przy zadanych czynnikach czy coś w tym stylu? #programowanie #informatyka #algorytmy #matematyka

(nie)szybki sposób na szybkie i wydajne wpisywanie bitów do pliku/pamięci.
Szybkie i wydajne wpisywanie bitów do pamięci w C. Coś w podobie Memcpy, tylko że do bitów, a nie do bajtów. Zamiast kopiować bit po bicie, kopiujemy informacje nieco większymi garściami.
z- 15
- #
- #
- #
- #

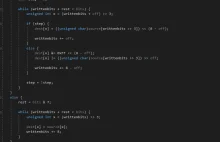
Mógłby ktoś wytłumaczyć jak zachowują się elementy stosu x=pop(), y=pop() i push(x+y) w tym przykładzie
#informatyka #algorytmy #programowanie #studbaza
#informatyka #algorytmy #programowanie #studbaza

źródło: comment_1591028139wQPnaZNpQfNtwCFi4lzHNF.jpg
Pobierz
@DMiros: najlepiej porobić jeszcze sobie kilka przykładów, sam się niedawno tego uczyłem :) ale wejdzie w krew, najważniejsze to pamiętać, że ostatnie to co weszło pierwsze wychodzi, tzw. LIFO

@DMiros: najważniejsze to pamiętać o kolejnosci. Wyobraź sobie rzeczywisty stos np. książek - żeby dostać się do książki na samym dole, musisz zdjąć ze stosu wszystkie te, które są nad nią. Analogicznie rzecz wygląda tutaj :)
Drugą bardzo popularną strukturą danych jest kolejka, czyli FIFO, first in, first out, która działa dokładnie tak jak kolejka w sklepie.
Drugą bardzo popularną strukturą danych jest kolejka, czyli FIFO, first in, first out, która działa dokładnie tak jak kolejka w sklepie.
Potrafiłby mi ktoś wytłumaczyć/rozpisać prosto jak to się rozwiązuje?
I pytanie czy det2 jest dobrze policzone bo mi wychodzi inaczej
#matematyka #algorytmy #informatyka #studbaza
I pytanie czy det2 jest dobrze policzone bo mi wychodzi inaczej
#matematyka #algorytmy #informatyka #studbaza

źródło: comment_1591007880suNYjUzrrDD06HvVjJdS0L.jpg
Pobierz@DMiros: tutaj też sam do końca nie rozumiem w jaki sposób jest to liczone. Wiem tylko, że wyliczany jest współczynnik dla odcinka AB i CD - gdzie na odcinku znajduje się punkt przecięcia i dla AB wygląda to tak:
- wartość ujemna współczynnika - punkt leży przed punktem A - czyli na prostej ale poza odcinkiem
- wartość z zakresu 0-1 - punkt leży na odcinku (proporcjonalnie do odległości pomiędzy
- wartość ujemna współczynnika - punkt leży przed punktem A - czyli na prostej ale poza odcinkiem
- wartość z zakresu 0-1 - punkt leży na odcinku (proporcjonalnie do odległości pomiędzy
@DMiros: https://www.geeksforgeeks.org/check-if-two-given-line-segments-intersect/ tutaj jest to też ładnie opisane ale brakuje tego ostatniego etapu, bo tam jest tylko sprawdzane czy przecinają się proste na których leżą odcinki a nie same odcinki.
jak rozumiec fragment po sredniku, jak to zapisac w kodzie? #naukaprogramowania #algorytmy

źródło: comment_1590917281fD0JPsvRozpHHQTZHajOpJ.jpg
Pobierz
@heater: wszystkie kroki po warunku w == maxW są chyba opcjonalne i możesz wrzucić je w ifa a po ifie lecisz z kolejnymi krokami

@heater: @piterus90: @StvStv: @StvStv: tutaj na tej stronie jest już jasne, że to tylko objaśnienie
https://eduinf.waw.pl/inf/utils/018_2017/2020.php
https://eduinf.waw.pl/inf/utils/018_2017/2020.php

jak tworzycie projekt programistyczny? Na własne potrzeby chcę napisać skrypt w #python współpracujący z skryptami #bash na #rasberrypi
Brakuje mi narzędzi aby szczątkowy, niepokudłany pomysł w systematyczny sposób opisać, zaplanować i zintegrować.
To co planuję:
-parę skryptów bash typu czytanie i zapisywanie temp, monitowanie połączenia z siecią, sprawdzanie update itd.
Brakuje mi narzędzi aby szczątkowy, niepokudłany pomysł w systematyczny sposób opisać, zaplanować i zintegrować.
To co planuję:
-parę skryptów bash typu czytanie i zapisywanie temp, monitowanie połączenia z siecią, sprawdzanie update itd.

@aHmuX:
- Postaraj się rozbić ten duży system jaki chcesz napisać na małe komponenty i pisać te komponenty tak żeby były na tyle niezależne od siebie żeby można ich też było użyć w innych projektach - np. skrypt w Pythonie do wysyłania e-maili może przyjmować kilka parametrów typu --to, --subject etc. i dzięki temu być re-używalny. Jak będziesz pisał dużo różnych rzeczy to po jakimś czasie będziesz mieć dużo takich
- Postaraj się rozbić ten duży system jaki chcesz napisać na małe komponenty i pisać te komponenty tak żeby były na tyle niezależne od siebie żeby można ich też było użyć w innych projektach - np. skrypt w Pythonie do wysyłania e-maili może przyjmować kilka parametrów typu --to, --subject etc. i dzięki temu być re-używalny. Jak będziesz pisał dużo różnych rzeczy to po jakimś czasie będziesz mieć dużo takich


Jak podejść do problemu wykrywania podobieństw profili osobowych jakiegoś zbioru ludzi.
Załóżmy, że jakaś liczba osób wypełnia ankietę odpowiadając na pytania dotyczące cech charakteru, czy np. preferencji odnośnie spędzania wolnego czasu. Każda z tych odpowiedzi ma jakąś wagę. Jak najoptymalniej dobrać takie osoby w grupę? Czy są do tego jakieś podejścia, algorytmy?
Uprzedzając pytania - pytam z czystej ciekawości gdyż to całkowicie nie moja działka :)
#programowanie #machinelearning
Załóżmy, że jakaś liczba osób wypełnia ankietę odpowiadając na pytania dotyczące cech charakteru, czy np. preferencji odnośnie spędzania wolnego czasu. Każda z tych odpowiedzi ma jakąś wagę. Jak najoptymalniej dobrać takie osoby w grupę? Czy są do tego jakieś podejścia, algorytmy?
Uprzedzając pytania - pytam z czystej ciekawości gdyż to całkowicie nie moja działka :)
#programowanie #machinelearning

@pepepanpatryk: Pewnie po standaryzacji itd najprostszym wyjściem wydaje się knn albo coś clasteryzującego np k-means, ale sporo zależy od danych, bo może to wymagać innego podejścia

@pepepanpatryk: ten sam algorytm stosowany w innym przypadku "biznesowym"
https://www.sqlservercentral.com/articles/the-products-often-purchased-together-problem-solved-in-r
https://www.sqlservercentral.com/articles/the-products-often-purchased-together-problem-solved-in-r
Zna ktoś stronkę albo coś takiego, na której można zwizualizować działanie algorytmu?
coś jak tu: https://pl.wikipedia.org/wiki/Sortowanie_przez_wstawianie#/media/Plik:Insertion-sort-example-300px.gif
#algorytmy #pytanie #pytaniedoeksperta
coś jak tu: https://pl.wikipedia.org/wiki/Sortowanie_przez_wstawianie#/media/Plik:Insertion-sort-example-300px.gif
#algorytmy #pytanie #pytaniedoeksperta
@lol3pdg: stronki nie znam ale w Pythonie w jakimś matplotlibie czy czymś podobnym klepniesz to w 15min
@lol3pdg: https://nrsyed.com/2018/09/27/visualizing-sorting-algorithms-and-time-complexity-with-matplotlib/
Tu ktoś robił coś podobnego tylko, że słupki się przesuwają zamiast kropek
Tu ktoś robił coś podobnego tylko, że słupki się przesuwają zamiast kropek
W jaki sposób najlepiej poradzić sobie z różnymi odmianami jednego słowa w języku angielskim?
Szukam jakiegoś niezbyt skomplikowanego algorytmu stemmingu lub lemantyzacji który pozwoli mi lepiej analizować słowa w mailach
#programowanie #algorytmy
Szukam jakiegoś niezbyt skomplikowanego algorytmu stemmingu lub lemantyzacji który pozwoli mi lepiej analizować słowa w mailach
#programowanie #algorytmy
@antagonista1111: Czemu nie jakiś word2vec albo coś podobnego?
@antagonista1111: no generalnie word2vec zamienia Ci słowa w wektory o takiej własności, że te o podobnym znaczeniu są bliżej siebie. Po obrobieniu tych wektorów możesz ich dalej używać jako featurow do jakiegokolwiek dalszego modelu. Zobacz sobie też np doc2vec. Może nie są to jakieś najnowsze metody w nlp ale działają przyzwoicie i są dobrze opisane


Siema, w algorytmie kukułki, w pewnym momencie musimy wygenerować nowe położenie gniazda używając wzoru (1), gdzie s (2) to liczba wylosowana z rozkładu Levyego. Reszta wzorów dalej na zdjęciu. Teraz tak: niech lambda=1.5, alfa=0.01, U=−1.1162901164220411, V=0.972371725706869 czyli s=−1.137336206259357 i wychodzi, że L(s, lambda) jest zespolona, a wypadałoby, żeby była rzeczywista. xD Coś źle zrozumiałem czy o co tutaj chodzi? :( Źródło, z którego korzystam: Xin-She Yang, Nature-Inspired Optimization Algorithms Second Edition [2014]

źródło: comment_1588114167hYd2wugg3TfwvpPPJPQbXK.jpg
Pobierz
@Hurd: dalem Ci plusa, bo kiedys tez lubilem matematyke.
Treść przeznaczona dla osób powyżej 18 roku życia...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@lorazepant: poka
@koostosh: na pw wysłałem : v
Komentarz usunięty przez moderatora
@Mireniu: sprawdź na libgen.lc
Czy #10YearsChallenge powstał, aby uczyć algorytmy rozpoznawania twarzy?

Jeżeli zaglądałeś na media społecznościowe w ciągu ostatnich dni to wiesz, że obecnie sieć podbija #10YearsChallange, wyzwanie polegające na wrzucaniu swoich zdjęć sprzed dziesięciu lat i porównanie ich z aktualnymi.
z- 3
- #
- #
- #
- #
- #
- #
#programowanie #algorytmy
Cześć, mam do zaprojektowania automat DFA, który ma akceptować wszystkie słowa kończące się na 'a' nad alfabetem [a,b], czy w takim przypadku stan początkowy może być stanem akceptującym(czy jest błędna bo w automat zaakcepuje zarówno a i b)?
Cześć, mam do zaprojektowania automat DFA, który ma akceptować wszystkie słowa kończące się na 'a' nad alfabetem [a,b], czy w takim przypadku stan początkowy może być stanem akceptującym(czy jest błędna bo w automat zaakcepuje zarówno a i b)?
źródło: comment_1592910345UoZwGKl8yxTkauhfvvpqfp.jpg
PobierzKomentarz usunięty przez autora
Mamy drzewa proporcjonalnych rozmiarów,
Przyjmujemy rozkłady jednostajne (i.e. każdy wierzchołek z przedziału ma takie samo prawdopodobieństwo)
Dzielimy zbiór S na dwa