Aktywne Wpisy
mookie +19
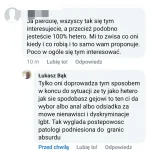
Bierzcie kredyty szybko po kule, zwolnienia w IT przyspieszają ale na pewno akurat was to nie będzie dotyczyło, w końcu taki #programista15k nie może być bezrobotny, bo przez ostatnie 15 lat tak było.
LinkedIn zwalnia 700 pracowników: https://businessinsider.com.pl/technologie/linkedin-w-trudnej-sytuacji-zwolnienia-mimo-wysokich-przychodow/cr4c4qn
Nokia zwalnia 14 000 pracowników: https://www.rp.pl/biznes/art39291851-gigantyczne-zwolnienia-w-nokii-mocny-spadek-sprzedazy
BNP zwalnia 900 pracowników: https://www.money.pl/banki/masowe-zwolnienia-w-duzym-banku-setki-osob-straca-prace-6953094924827584a.html
To tylko newsy z tego tygodnia. Dodatkowo jeszcze Fiskus zaczął ścigać informatyków za nadużycia przy podatkach.
#nieruchomosci #finanse #pracbaza #ekonomia #gospodarka
LinkedIn zwalnia 700 pracowników: https://businessinsider.com.pl/technologie/linkedin-w-trudnej-sytuacji-zwolnienia-mimo-wysokich-przychodow/cr4c4qn
Nokia zwalnia 14 000 pracowników: https://www.rp.pl/biznes/art39291851-gigantyczne-zwolnienia-w-nokii-mocny-spadek-sprzedazy
BNP zwalnia 900 pracowników: https://www.money.pl/banki/masowe-zwolnienia-w-duzym-banku-setki-osob-straca-prace-6953094924827584a.html
To tylko newsy z tego tygodnia. Dodatkowo jeszcze Fiskus zaczął ścigać informatyków za nadużycia przy podatkach.
#nieruchomosci #finanse #pracbaza #ekonomia #gospodarka

wankstain +480
{kind=link}
Aktywne Znaleziska





Dane będą ustrukturyzowane, około 10-15 kolumn przy czym tylko w jednej będzie tekst użytkownika (wiec może to być cokolwiek). Miesięcznie 50-100 mln rekordów. Nie znam się zupełnie, ale musiałbym wiedzieć mniej więcej co będzie potrzebne. Pytania, co lepiej sql, no sql? Jeżeli no sql to co, żeby była w miare user friendly dla osób, które będą te dane przetwarzać. Musi być w miare szybka do querowania i updatowania.
Jeżeli to zbyt ogólny opis to co warto jeszcze zaznaczyć? Jeżeli odpowiedz to „to zależy” to w co wy byście poszli bazując na doświadczeniu. Z tego co czytam baza sql by się na to pisała, ale jak będzie gdy rekordów okaże się więcej i trzeba będzie dodać mocy.
Co myślicie Mireczki?
#sql #nosql #programista15k #python #aws
@Rollines: na to to musisz odpowiedzieć sobie sam. My Ci nie pomożemy bo każde z tych ma swoje plusy i minusy więc musisz nam podać:
- jakiego typu tam będziesz miał dane
- jak bardzo będzie Cię bolała utrata pojedynczych rekordów
- jak bardzo będzie Cię bolała utrata np. 1/3 rekordów
- czy potrzebujesz ACID na bazie
Bez tych informacji nikt z poważnym doświadczeniem nie
100 mln/mc to *jest* sporo. Przy MySQL/PostgreSQL bez partycjonowania się nie obejdzie. Chyba że struktura będzie faktycznie prosta i będą potem proste zapytania leciały. Ale to nadal będzie sporo i jedynymi sensownymi kandydatami będą tu MS SQL Server lub Oracle. Czy da się osiągnąć to na PostgreSQL i MySQL? No da się, ale będzie to kosztować prawdopodobnie dodatkowe cudowanie po stronie aplikacji.
Ale
Pytam, bo design to jedno a potem trzeba to produkcyjnie utrzymać, jakieś zarządzanie, konfigurowanie itp
Jeśli jakieś proste kolumny to poczytałbym o Cassandrze, jest wersja darmowa, jest też na wypasie płatna z wsparciem i dodatkami
Dane to głównie text, daty lub inty do 20 znaków max (za wyjątkiem jednej kolumny)
A rekordów niestety nie mogę stracić żadnych + ACID compliant.
@Rollines: no więc opcją jest jedynie SQL.
To zostaje Ci:
- MS SQL Server za kupę hajsu - jeśli jesteś w środowisku Microsoftowym (typu C# czy .NET to pewnie to jedyna opcja dla Ciebie)
- Oracle za kupę hajsu - jeśli jesteś w środowisko Enterprise Linuksowym lub Microsoftowym
- PostgreSQL z hackami architektonicznymi; firmy ostatnio idą jednak w niego żeby odciąć
Aplikacja jest webowa napisana w pythonie
Tu wspominają o tym samym co ja - partycjonowanie.
Aczkolwiek w Postgresie jest to prostsze niż w MySQL bo Postgres może partycje robić pod spodem, a wystawiać użytkownikowi już widok z zagregowanymi partycjami.
Niby nie dużo, ale jeśli nie możesz utracić ani jednego wiersza to jest to równoznaczne z robieniem synca przy każdym zapisie bo jest jednak obciażającą operacją na dysku. No i trzeba pamiętać, że to średnia arysmetyczna co znaczy, że w szczycie może być 200 czy nawet 1000 insertów/s.
W MySQL-u stosowałem hacki typu "rób synca co sekundę" - wtedy
Czy z ciekawości (jak i dla przyszłych pokoleń googlujacych ten temat) napisałbyś jakby to wyglądało, gdyby nie było transakcji i ACID nie byłby wymogiem?
Przypadek z 1/3: każda NoSQL którą ktoś źle skonfigurował i zrobił shardy które nie mają replik ( ͡° ͜ʖ ͡°)
Przypadek z pojedynczymi: każda która nie syncuje danych przy zapisie tylko chwilę później. Przy niektórych trzeba w aplikacji wymuszać sync danych.
Przypadek: brak slave/repliki
Nie wiem czemu jesteś taki czepliwy.
Nawet goły PostgreSQL z dobrą konfigurajcą na mocnym sprzęcie przyjmie na klatę taką ilość danych.
A jak komuś się nie chce po prostu skonfigurować odpowiednio postgresql i zakupić odpowiednio mocny serwer to problem w zależności od rodzaju danych został rozwiązany już wielokrotnie, Citus, Timescale, Greenplum, Amazon RDS for PostgreSQL, Cloud SQL for PostgreSQL - take your pick.
A tak serio, bazy danych to nie jest mój konik, ale z racji pracy chcąc czy nie chcąc muszę ich dotykać i jakąś-tam wiedzę z nich mam. Z naciskiem na "jakąś-tam" ( ͡° ͜ʖ ͡°). Optymalizować ich za bardzo
Napisałeś:
A ja napisałem:
oraz:
@morsik: O tak napisałeś, proszę spojrzeć. To jest ta nieprawda. A szkalowania faktycznie nie ma, no trudno :D