
100zł dla pięknego kawalera (lub kawalerki) którego wylosuję jutro po południu.
Wysyłka do paczkomatu (nadawca, sam Michał B) lub blik ewentualnie.
Standardowo, losowanko z plusów+komć, zielonki out. W niedzielę po obiedzie.
Nie, nie jest to scam, ostatnio rozdajo wygrała @Siik czy @Alprazolam i może potwierdzić, więc mi tu nie trujcie gitary, że to skam.
#rozdajo
Wysyłka do paczkomatu (nadawca, sam Michał B) lub blik ewentualnie.
Standardowo, losowanko z plusów+komć, zielonki out. W niedzielę po obiedzie.
Nie, nie jest to scam, ostatnio rozdajo wygrała @Siik czy @Alprazolam i może potwierdzić, więc mi tu nie trujcie gitary, że to skam.
#rozdajo



























































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
• [1] Zwiększanie efektywności LLM poprzez oceny na każdym kroku "rozumowania"
Google Deep Mind opublikowało artykuł "Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning" dotyczący usprawniania LLM-ów w rozwiązywaniu problemów poprzez przekazywanie im informacji zwrotnych w każdym kroku (PRM), a nie tylko informowanie ich na końcu (ORM), czy mają rację, czy nie. Autorzy pokazują, że takie podejście, wykorzystujące model pomocniczy do śledzenia postępów, znacznie poprawia efektywność i dokładność zarówno
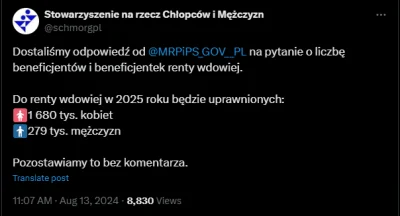
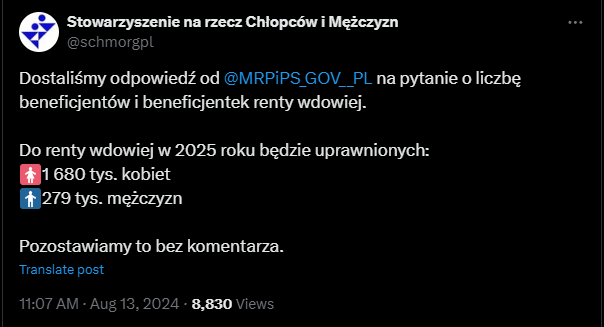
źródło: sref 1837465215 GY9zTy6XoAAfrWU
Pobierzhttps://streamable.com/t19n0f