Aktywne Wpisy

Lolenson1888 +138
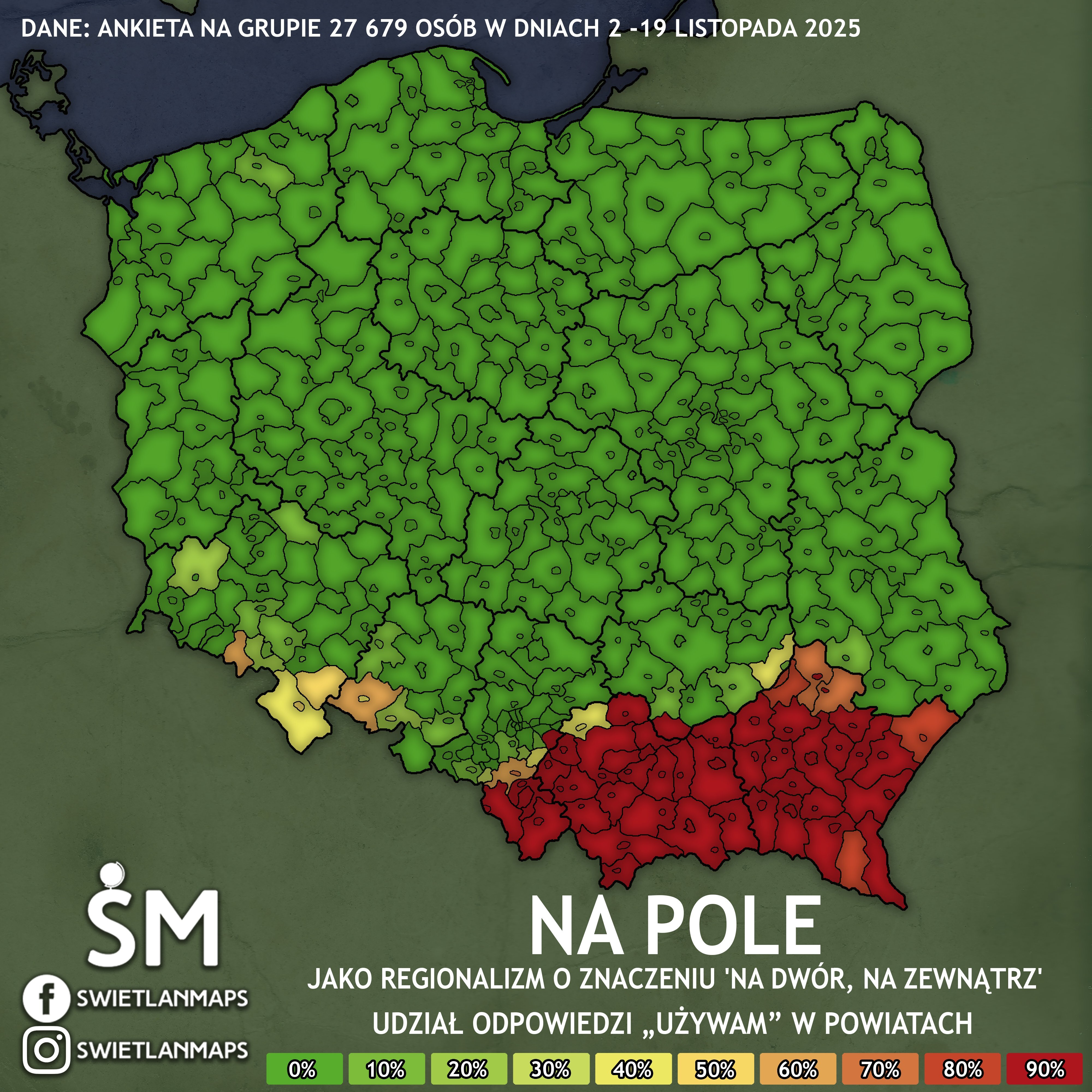
Niesamowite jest to jak ostry, wyraźny, bez strefy przejściowej jest ten podział gdzie się mówi „wychodzę na dwór”, a gdzie się mówi „wychodzę na pole”. Niemal równo z granicami województw małopolskiego i podkarpackiego, co jest przecież nietypowe jak na Polskę. Niby rysuje się granica Galicji, ale nie do końca, bo są wyjątki (Kazimierza Wielka, Miechów, Proszowice). Jedziesz na zakupy z Sandomierza do Tarnobrzega i już jesteś w zupełnie innej strefie językowej xD

źródło: 035645EB-B0C2-4590-9E2E-1FA2D7CE8200
Pobierz
czy zdarza wam się skrobać przednią szybę od środka przy minusowych temperaturach? Obecnie w tych okolicach zera widzę sporo wilgoci/niemalze wody, a im dalej w zimę, tym będzie gorzej. Nie wiem, jak temu przeciwdziałać, skad tyle tej wilgoci. Jakieś woreczki z ryżem czy te takie pochłaniacze allegrowe nic nie dają ( ͡° ʖ̯ ͡°)
#kiciochpyta #samochody
#kiciochpyta #samochody





{kind=link}
Nie mogę się doszukać tego na benchmarkach, a ostatnimi czasy ten model zrobił na mnie wrażenie w swojej bazowej bezpłatnej formie - rozważam przerzucenie się z o3.
[cele czysto edukacyjne, benchmarki typu 'science']
Ew. jeśli ktoś testował gemini 2.5/o3 i porównywał z grokiem 4 bazowym to też może dać znać.
#sztucznainteligencja #gemini #gpt #ai #programowanie15k #grok
Podłącze się trochę do wątku z pytaniem który "chat" warto kupić?
Zastanawiam się nad subskrypcją na próbę na kilka mcy ale nie wiem w co pójść.
Z moje strony potrzebuję czegoś do programowania glownie python i ogólnych rozważań inżynierskich włączając obliczenia.
Macie jakiś faworytów?
@solid959
Tu możecie sam chat sobie potestować na różnych modelach za FREE: https://lmarena.ai/?mode=direct
Wystarczy tam na górze wybrać model.
@KryptonZ: IMO:
Nie są to otwarte modele, aby ktoś sobie na ich podstawie stworzył jakieś lżejsze wersje i je udostępniał na LMArena.
- Zatem albo zamiast tych modeli to są wykorzystywane tam jakieś inne modele.
- Albo Twoja ocena nie jest miarodajna
Tak samo widzę to, że o3 zwyczajnie krócej myśli niż u chataGPT - ale to akurat mało rzetelna informacja ze względu na to, że nie wiem czy różni się szybkość przy tokenach i przy przeglądarce/aplikacji z subskrypcji
No, ciekawa sprawa. Też jestem ciekaw wytłumaczenia, jak istnieje inne niż losowość, że czasami te modele odpowiadają lepiej a czasami gorzej, i akurat na LMArena trafić się mogły serie tych gorszych odpowiedzi.
1. Najnowszy model gemini ma zdecydowanie tryliard razy lepszej jakości dane, aktualniejsze niż o3 w większości przypadków.
2. o3 ma lepsze rozumowanie, ale gorszą bazę danych - przez co sumarycznie gorzej wypada w szerokopojętej kategorii "science"
Info z piątnicy.
Bezkonkurencyjnie, serio, gemini wygrywa w mojej, em, domenie/niszy (nie mówię o programowaniu, bo zwyczajnie tego nie uprawiam)
Grok 4 przegrał. XD