
Jak regexy się lubią z polskimi znakami? czy jestem w stanie napisać takie wyrażenie, które przyjmie mi zarówno „
#informatyka #programowanie #regexp
żółw", jak i „zolw"?#informatyka #programowanie #regexp
Wszystko
Najnowsze
Archiwum
żółw", jak i „zolw"?"\{ARGS" + QString("(?:[(\d+),(\w+)?\])?").repeated(64) + "\}"{ARGS[2,1][10,D][2,255][10,wykop]}
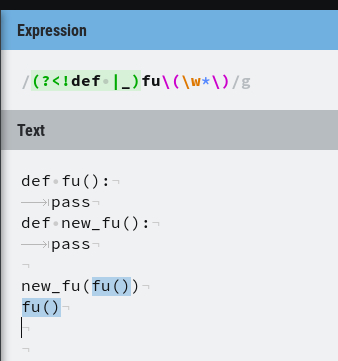
(?>[([0-9]+)\,([0-9,a-z,A-Z]+)\]) i dał do tego if(x.startsWith("{ARGS") && x.endsWith("}")). W ten sposób łapie to o co chodzi i jest eszcze szybkie. Możnaby sprawdzać w 1 regexpie ale masz dodatkowe grupy i wydajność szlag trafi.(?)(.*?)(?=<\/tag_name>) - wyszukaj wszystkie wartosci w tagu tag_name(?<!def |_)fu\(.*\)(?<!def |_)fu\(\w*\)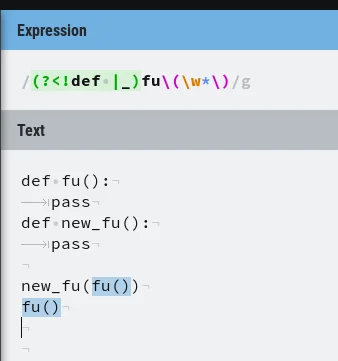
źródło: comment_1580906583ekKf2c0Z6iKHGFHquRPBQS.jpg
Pobierz$ php test.phpArray( [0] => Tekst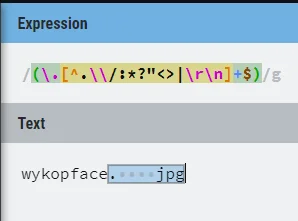
źródło: comment_TfqcDUl2r56S9Hd4Snlf6717KJttKu3R.jpg
Pobierzr_et.push_back(r_et[i]);push_back\([^\n]+[ nie jest zbyt optymalny, bo wykrywa 583 rekordy, z których może 10 będzie przydatnych.B->A pushback A
a takie wyrażenie nie należy do gramatyki regularnej tylko do bezkontekstowej.

źródło: comment_H5oUm54Uv0c2F0nWKVdphT17vEMkDdPx.jpg
Pobierz/^[\p{Lu}][\p{Ll}]*$/u, który przepuszcza tylko 1 wyraz z wielkiej litery, dla wszystkich możliwych znaków. Wszystko działa na Operze i Chrome, jednak Firefox nie obsługuje tego \p{}.
Wyrażenia regularne w BGP czyli REGEXP - regular expressions. Analiza atrybutu AS-PATH. Jak znaleźć AS tranzytowy? Jakie prefiksy są osiągalne przez AS?
z(https|http):\/\/(www\.)?(\b(?!mail\b)\w+.)google\.(com|([a-z]{2})).*.replace(/\s/g, "")START_LINE
RegEx czyli wyrażenia regularne to potężne narzędzie pozwalające na zaawansowaną pracę z tekstem. Najczęściej spotkamy się z nimi, przy walidacji danych wprowadzanych przez użytkowników. Jednak nie jest to ich jedyne zastosowanie, za ich pomocą możemy odnaleźć wzorzec w tekście, pociąć...
z























{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mam np. "KOLOR Ekstra Zielony"
Chce dostać tylko Ekstra Zielony
#programowanie #regex #regexp