Wszystko
Najnowsze
Archiwum
sed 's%tekst%innyTesks%g'

Mireczki, mam do zrobienia takie zadanie:
"Z wyników zwracanych przez polecenie ifconfig wybierz informacje o adresie IP oraz adresie
MAC wszystkich aktywnych kart sieciowych. Informacje te zapisz do pliku interfaces.txt,
który powinien zawierać trzy kolumny: intname, ipaddress, mac_address a

Komentarz usunięty przez autora Wpisu
Poproszę o pomoc z windowsowym (gnuwin32) awk/gawk/sed lub alternatywą pod windowsem.
Pliki z danymi wejściowymi mają format (przykładowy wiersz)
yzz-0000001000-v1000,"54,76","54,76",0,"54,76","54,76"
Chcę otrzymać
{gsub(/,(?=(?:[^"]*"[^"]*")*[^"]*$)/,"aaaaA");}1
aktualnie nie działa :-(

@uhu8
podsuniecie mi pomysl w jaki sposob moge uzyskac zamierzony efekt?
Dla uproszczonego testu mam sobie plik text.txt
START_LINEW pliku sa transakcje, w roznych sekcjach znajduja sie puste linie, wiec to nie moze byc punkt odniesienia.
Jesli wiec transakcja ma swoj specyficzny poczatek to potrzebuje ja cala wylapac. Na samym dole (5 i 6) znajduje sie linia adresowa, gdzie w zaleznosci od miejsca moze byc inna :)
W skrocie - gdy zaczyna sie od STARTLINE, chce wylapac wszystko do 6. 6

sed żeby zmieniać sobie config firefoxa z linii komend. sed -i 's^user_pref("'$1'",.*);^user_pref("'$1'",'$2');^' user.jsroot@92d87ffbe423:~/.mozilla/firefox/egtw4p6p.default# ./ffset.sh general.useragent.override '"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.37"'
sed: -e expression #1, char 103: unterminated `s' commandJak tylko napotka na spację w argumencie to wywala mi takim błędem. Co zrobiłem nie tak?
sed -i '^userpref("'$1'",.*);^userpref("'$1'",'$2');^' user.js
@KosmicznaKluska: Yh. Teraz wywala na tym delimiterze
sed: -e expression #1, char 1: unknown command: ^'`sed -i 's^user_pref("'$1'",.*);^user_pref("'$1'",'"$2"');^' user.jsDzięki za wskazówkę :)

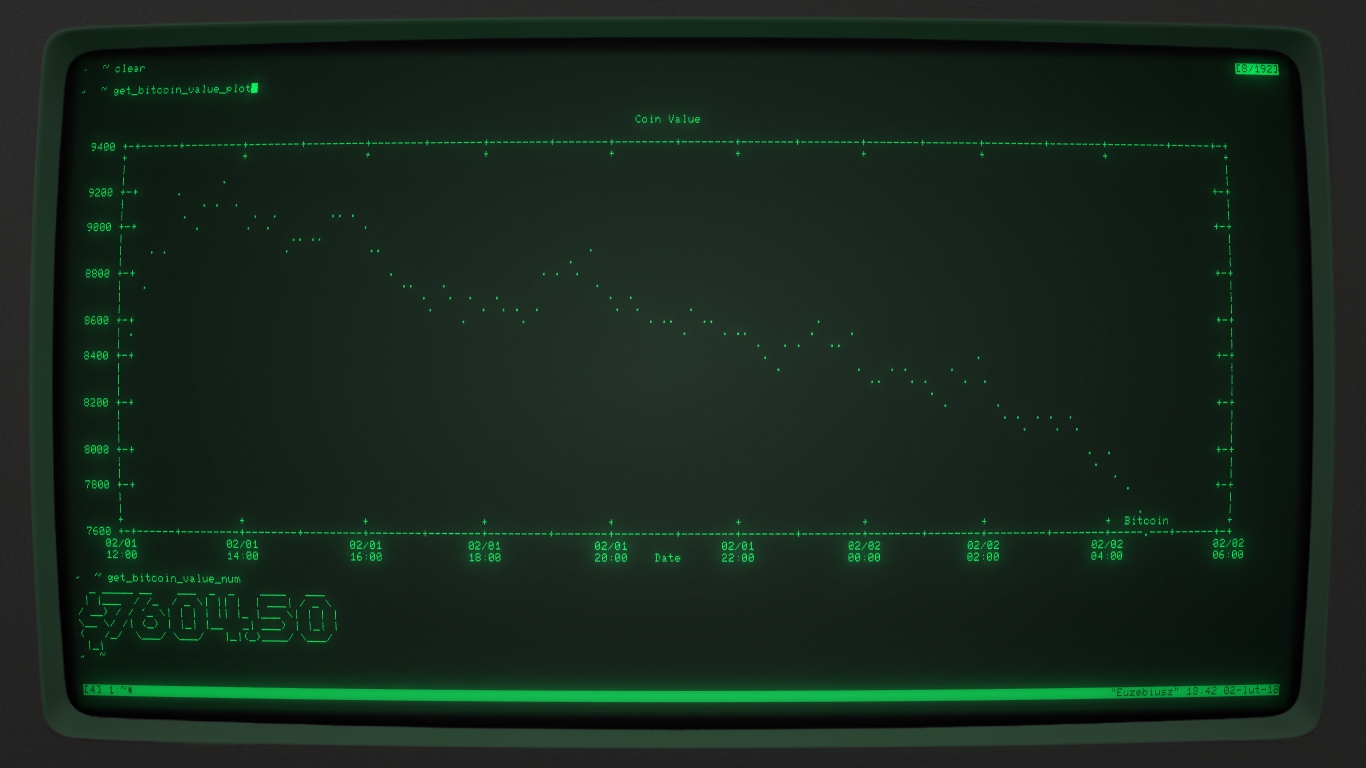
bash <(curl -sS [https://raw.githubusercontent.com/dzaczek/blogscripts/master/bcplot.sh)](https://raw.githubusercontent.com/dzaczek/blogscripts/master/bcplot.sh))wymaganiia #gnuplot #bash #awk #sed #linux :)
źródło: comment_KbwbYlJrDMJpaVZuqF1kCMLCHCK4N7lj.jpg
Pobierz
#sed #bash #skryptowanie #linux



pany, jak odstawić taką sztukę: wyszukuję sobie pliku sedem + regexem potrzebny ciąg. konkretnie chodzi o kwotę, np: 1 234.56 (tu spoko) i chcę ją zastąpić tym samym, ale bez spacji. czyli 1234,56 (i tutaj już gorzej) Jak, bo mi się już głowa gotuje :}

echo "1 234.56" |perl -p -e 's#((\d{1,3})\s)*(\d{3})\.(\d{2})#$2$3.$4#g'
Niestety spadek prędkości był o 50% na odczycie i zapisie sekwencyjnym. I ponad 10x razy wolniej na 4k-64thrd.
Po małym research-u okazało się że ten SSD wspiera standard Opal 2.0. Czyli SED - "Self-Encrypting Drive", czyli samo szyfrujące się dyski.
sed -en '1,5s/Faculty/School/gp;1,5s/Faculties/School/gp' d.txt
i wyskakuje
sed:
https://www.youtube.com/playlist?list=PLcUid3OP_4OW-rwv_mBHzx9MmE5TxvvcQ
#linux #shell #sed #mozebyloamozenie #terminaltopotega


tzn. jak w pliku wystąpi cyfra 20 to ma zostać zamieniona na [[20]]?
sed 's/[0-9]*/[[0-9]]/g' zamienia mi wszystko na [[]] :/
#linux #sed #kiciochpyta

$ echo '/dev/sda6: UUID="785b1416-ffbf-43e2-8a5c-052"' | awk -F: '{print $1}'
/dev/sda6
$

echo '/dev/sda6: UUID="785b1416-ffbf-43e2-8a5c-052"' | awk -F"[/:]" '{print $3}'sda6

{kind=link}
Dyspozytorka została ukarana za zbyt ścisłe trzymanie się procedur.

Uff obawiałem się, że nie doczekam tej chwili, kiedy w Polsce będzie ważniejszy cel wprowadzenia prawa od jego litery :-) Dyrektor pogotowia ratunkowego uważa wręcz, że w tej sytuacji prawo powinno być złamane aby uratować życie ludzkie.
z- 62
- #
- #
- #
- #
- #
- #
- #
- #
Kółko i krzyżyk pod seda
Jak ktoś się uparł pozostać przy terminalu na rejestrach przesuwnych...
z- 0
- #
- #
- #
- #
- #
- #
- #
- #
- #
Tetris w SEDzie
Powłoka systemowa taka jak Bash zazwyczaj służy do wykonywania poleceń systemowych, administracji serwerem. A co robić w wolnym czasie jeśli dostęp mamy tylko do konsoli? Można pograć w starą grę Tetris. A zwłaszcza jeśli została ona napisana w sedzie. Skrypt ten dostępny jest w pliku sedtris.sed, a jego autorem jest Julia Jomantaite.
z- 0
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ewolucja języków przez wieki

Ewolucja języków przez wieki
z- 7
- #
- #
- #
- #
- #
- #
- #
tak myślę że teraz nauka takich rzeczy jak #sed lub #awk co i tak nie były jakoś często używane no ale zdarzało się w świecie Linuksa to teraz w dobie AI już w ogóle nie ma sensu, modele są w stanie odgadnąć rozwiązanie w większości przypadków i nie ma sensu nad tym ręcznie siedzieć. Jakie to będzie mieć konsekwencje na przyszłość to już inny temat.
Owszem AI pisze regexy jak szalone, ale nadal z tyłu głowy musisz mieć co chcesz mniej więcej użyć i jak.
https://www.npmjs.com/package/is-even ( ͡° ͜ʖ ͡°)