Aktywne Wpisy

Lekarz_7k +106
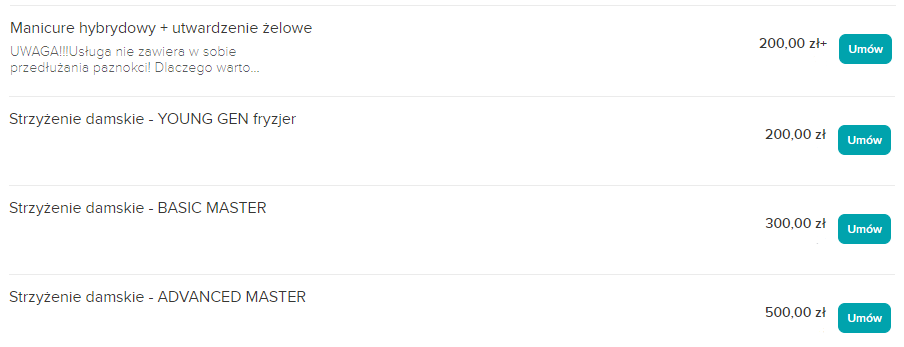
Jakoś tak mnie ostatnio naszła taka rozkmina. Dlaczego wykopkom przeszkadza to, że chirurg który kształcił się 10+ lat żeby wykonywać swój zawód bierze 200 czy 300zł za konsultacje, a w tym samym czasie nie przeszkadza im to, że jedna czy druga fryzjerka czy inna karyna bez szkoły bierze 200zł za paznokcie albo 500zł za strzyżenie. To przepraszam bardzo skoro tak są w------e ceny takich usług to ile ten lekarz specjalista ma według

źródło: image
Pobierz
BlackpillMonster +234





{kind=link}
{kind=link}
#chatgpt #sztucznainteligencja #datascience #programista15k
potem patrzysz że jednak stare dobre drzewa wygrały, to informujesz kierownictwo że wprowadzasz ver 2 systemu opartą na AI a w środku xgboost :)
@JamesJoyce: ja który pierwszy raz słyszę takie pojęcie
źródło: dd0
Pobierz@JamesJoyce:
no to piszcie tam, ale co macie? jakiś pretrained dostaliście? wsparcie od google albo microsoft?
jak to ma wyglądać?
podsuń im to dla porównania ile powinna kosztować twoja praca :)
Powiedz że się da, ale to nie jest tania robota.