
#prawo #informatyka #it #cyberbezpieczenstwo #webscraping
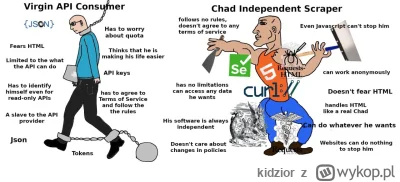
Mam scrapper który zbiera publicznie dostępne dane (dostępne bez żadnej autoryzacji). Jednak strona internetowa, z której pochodzą te dane, zabrania w regulaminie korzystania z botów do ściągania danych. Dodatkowo, udostępnia płatne API na te dane.
Czy w świetle prawa korzystanie z tego scrappera do ściągania danych, które potem są wykorzystywane w celach komercyjnych jest nielegalne?
Mam scrapper który zbiera publicznie dostępne dane (dostępne bez żadnej autoryzacji). Jednak strona internetowa, z której pochodzą te dane, zabrania w regulaminie korzystania z botów do ściągania danych. Dodatkowo, udostępnia płatne API na te dane.
Czy w świetle prawa korzystanie z tego scrappera do ściągania danych, które potem są wykorzystywane w celach komercyjnych jest nielegalne?





















{kind=link}
{kind=link}
{kind=link}
Cześć Wykopowicze 👋
Jeśli interesujecie się web scrapingiem, automatyzacją zbierania danych lub analizą danych z sieci, to mamy coś dla Was!
Firma