
#programowanie #programowanie15k #bazydanych
Cześć Mirki, polecicie jakieś ciekawe książki, źródła wiedzy o bazach danych? Chodzi mi o bardziej zaawansowane koncepty, nie podstawowe SQL'ki. Fajnie by było jakby obejmowało również nierelacyjne bazy danych, ale wiadomo, że wszystkiego mieć nie można. ( ͡° ʖ̯ ͡°)
Cześć Mirki, polecicie jakieś ciekawe książki, źródła wiedzy o bazach danych? Chodzi mi o bardziej zaawansowane koncepty, nie podstawowe SQL'ki. Fajnie by było jakby obejmowało również nierelacyjne bazy danych, ale wiadomo, że wszystkiego mieć nie można. ( ͡° ʖ̯ ͡°)


















![tomaszs - Hej, do 31.08.20 trwa propozycja GRYFNO TYTA! [Drugi tytuł 50% taniej] na k...](https://wykop.pl/cdn/c3201142/comment_1598335543iRAWlJNjxqUkj099r3JI6Q,w400.jpg)








{kind=link}
{kind=link}
{kind=link}
{kind=link}
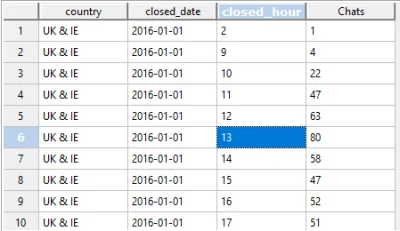
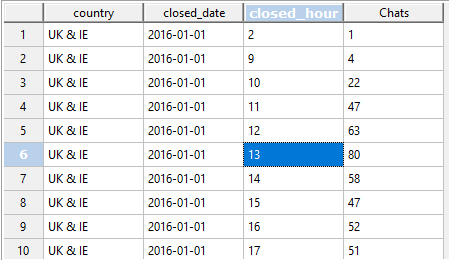
#postgresql #bazydanych
źródło: comment_1599636036FDE94Ix5HDJiW7K0by6NrG.jpg
Pobierz