Mam taki use case:
- wpada sobie plik (CSV)
- na pliku wykonuje X reguł (powiedzmy takie formuły excelowe)
- wynik trafia do bazy/pliku (no to akurat chyba najmniej problemowe)
I problemy:
- wpada sobie plik (CSV)
- na pliku wykonuje X reguł (powiedzmy takie formuły excelowe)
- wynik trafia do bazy/pliku (no to akurat chyba najmniej problemowe)
I problemy:










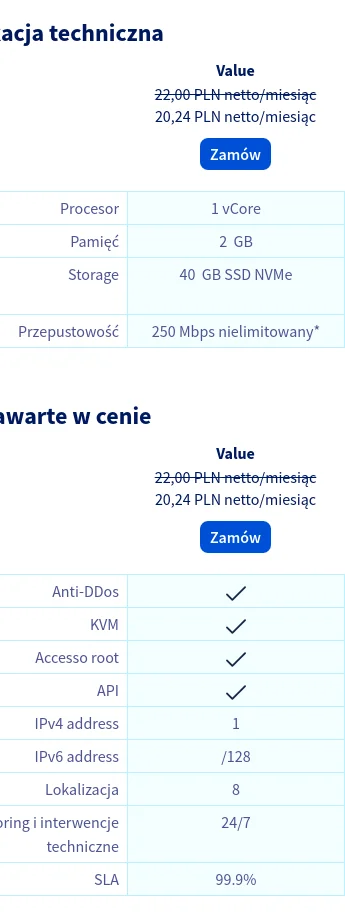









{kind=link}
{kind=link}
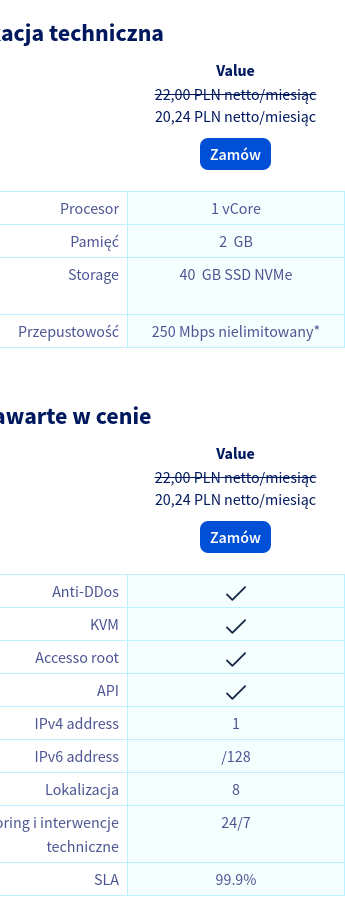{kind=link}
{kind=link}
{kind=link}
Dane będą ustrukturyzowane, około 10-15 kolumn przy czym tylko w jednej będzie tekst użytkownika (wiec może to być cokolwiek). Miesięcznie 50-100 mln rekordów. Nie znam się zupełnie, ale musiałbym wiedzieć mniej więcej co będzie potrzebne. Pytania, co lepiej sql, no sql? Jeżeli no sql to co, żeby była w miare user friendly dla osób, które będą te dane przetwarzać. Musi być w miare szybka do
Przypadek: brak slave/repliki
Nawet goły PostgreSQL z dobrą konfigurajcą na mocnym sprzęcie przyjmie na klatę taką ilość danych.
A jak komuś się nie chce po prostu skonfigurować odpowiednio postgresql i zakupić odpowiednio mocny serwer to problem w zależności od rodzaju danych został rozwiązany już wielokrotnie, Citus, Timescale, Greenplum, Amazon RDS for PostgreSQL, Cloud SQL for PostgreSQL - take your