

#programowanie #bazydanych #java #spring
tl;dr: jak zrobić produkcyjnie rective relacyjną bazę w Javie/Springu?
Żeby na froncie dane był pokazywane na żywo (a nie odświeżane np. co sekundę) to stosuje się Websockety (komunikacja pomiędzy frontem a backendem).
A
tl;dr: jak zrobić produkcyjnie rective relacyjną bazę w Javie/Springu?
Żeby na froncie dane był pokazywane na żywo (a nie odświeżane np. co sekundę) to stosuje się Websockety (komunikacja pomiędzy frontem a backendem).
A








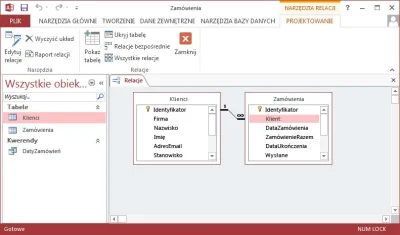

















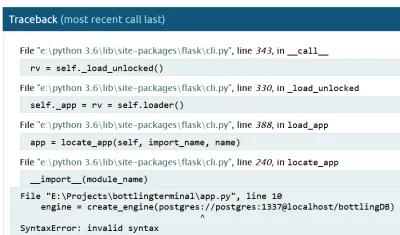



{kind=link}
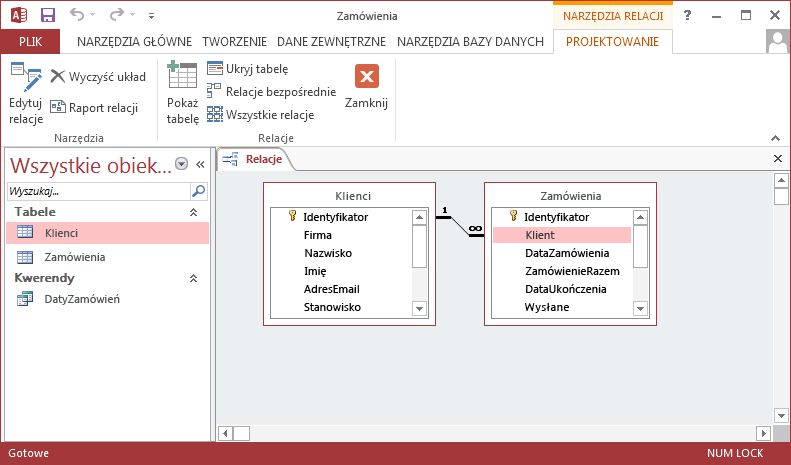{kind=link}
{kind=link}
( ͡°( ͡° ͜ʖ( ͡° ͜ʖ ͡°)ʖ ͡°) ͡°)
Wiadomo, że spółka wchodzi w skład #big4 i jest to #korposwiat ale zdecydowanie na co dzień atmosfera, specyfika projektów godne polecenia, no i dobre hajsy
źródło: comment_ZxsevX1rm06UfbmXMn4Rw9qWWypUsi5k.jpg
Pobierz