Aktywne Wpisy

rosen +7

{kind=link}
Mateo353 +22
Macie oficjalny statement Wonzia. Nie strimuje, bo obrażacie mnie i moje gry, w które lubię grać. Wonziu maluje obraz jakby ludzie przychodzili i jechali go od k---w, a najwyżej co to było pytanie, czy będzie coś dzisiaj innego oprócz kart albo Star Citizena albo oznajmienie, że Star Citizen to wychodzą. Wonziu uznał to za mega toksyczną atmosfere i jak typowy płatek śniegu to jest to dla niego za dużo. #wonziu

źródło: image
Pobierz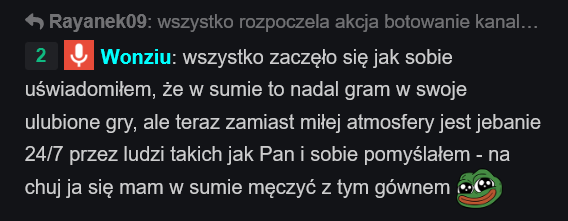{kind=link}
Aktywne Znaleziska





Mam taką odpowiedź z bazy (już sparsowana do słownika):
[{grupa1='wartosc1', grupa2='wartosc1', coś1='wartosc', coś2='wartosc', coś3='wartosc', xxx{n}},
{grupa1='wartosc1', grupa2='wartosc2', coś1='wartosc', coś2='wartosc', coś3='wartosc', xxx{n}},
{grupa1='wartosc2', grupa2='wartosc3', coś1='wartosc', coś2='wartosc', coś3='wartosc', xxx{n}},
{grupa1='wartosc2', grupa2='wartosc4', coś1='wartosc', coś2='wartosc', coś3='wartosc', xxx{n}},
{itp}
]
Jak teraz za pomocą
pandaszrobić z tego jsona w postaci:['grupa1': [
'grupa2': {
'coś1': wartość,
itp
},
'grupa2': {
'coś1': wartość,
itp
}
],
'inna_grupa1': [
'inna_grupa2': {
'coś1': wartość,
itp
},
'inna_grupa2': {
'coś1': wartość,
itp
}
]
]
Chodzi mi jak dokładnie użyć
dataframe.groupby( ͡° ʖ̯ ͡°)Próbuję
dataframe.groupby(['grupa1','grupa2'])ale dostaję jsona z tyloma obiektami ile jest wierszy (czyli nie pogrupowane)https://pastebin.com/ZztTSa4V