michal-dyl
Może ktoś mi pomóc z MySQL? Bo jakimś cudem nagle nie mogę zakończyć polecenia średnikiem. #mysql #bazydanych


0anon
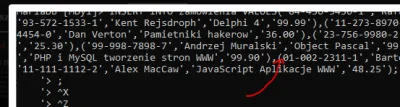
@michal-dyl: IMO masz gdzieś niezamknięte 'ciapki' - czyli zgubiłeś gdzieś znak '
- michal-dyl

Sapzzz
- Supaplex
- michal-dyl
- MienciuskiPajonk






























{kind=link}
{kind=link}