
#codzienneainews
• [1] Zwiększanie efektywności LLM poprzez oceny na każdym kroku "rozumowania"
Google Deep Mind opublikowało artykuł "Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning" dotyczący usprawniania LLM-ów w rozwiązywaniu problemów poprzez przekazywanie im informacji zwrotnych w każdym kroku (PRM), a nie tylko informowanie ich na końcu (ORM), czy mają rację, czy nie. Autorzy pokazują, że takie podejście, wykorzystujące model pomocniczy do śledzenia postępów, znacznie poprawia efektywność i dokładność zarówno
• [1] Zwiększanie efektywności LLM poprzez oceny na każdym kroku "rozumowania"
Google Deep Mind opublikowało artykuł "Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning" dotyczący usprawniania LLM-ów w rozwiązywaniu problemów poprzez przekazywanie im informacji zwrotnych w każdym kroku (PRM), a nie tylko informowanie ich na końcu (ORM), czy mają rację, czy nie. Autorzy pokazują, że takie podejście, wykorzystujące model pomocniczy do śledzenia postępów, znacznie poprawia efektywność i dokładność zarówno
![PeterWeiss - #codzienneainews
• [1] Zwiększanie efektywności LLM poprzez oceny na każ...](https://wykop.pl/cdn/c3201142/c578a3d069188fa629d95907ac09d215400731b537e2dd6c1954f5e378b1581b,w400.jpg)













![PeterWeiss - Odnośniki:
[1]
https://github.com/souzatharsis/podcastfy-demo
[ demo: ] ...](https://wykop.pl/cdn/c3201142/d7d86a98a7784692b1b578747b2e18ec12f03a1bb8a7d6e4fcc9011fb42548c4,w400.jpg)













![PeterWeiss - #codzienneainews
• **[1] Dziennikarz hiszpańskiego El Pais przeprowadził...](https://wykop.pl/cdn/c3201142/e7ab43b385b2cd2c0b246d999465962fc81d35fc96da388eaf5634176a327bf1,w400.jpg)




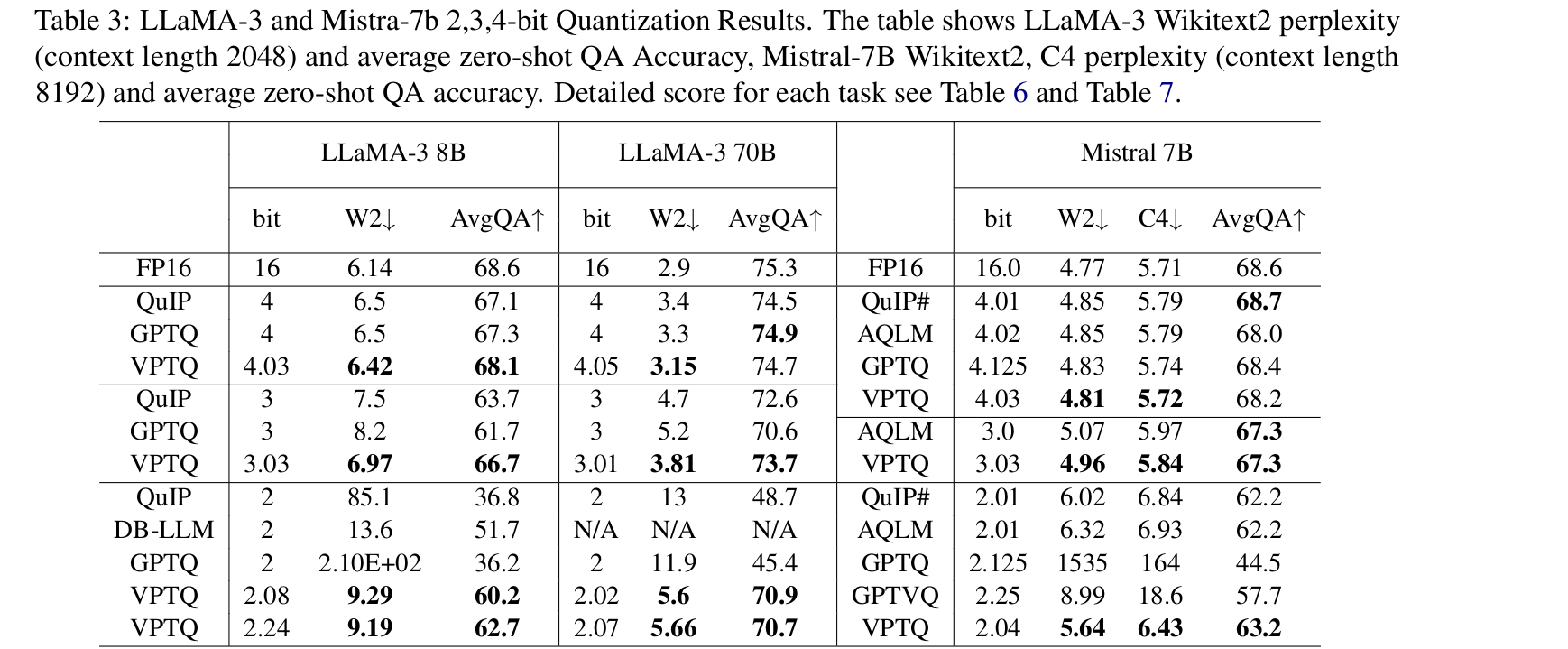
![PeterWeiss - Tabelka do newsa nr 2 (kompresor VPTQ) i odnośniki:
[1]
https://llava-vl...](https://wykop.pl/cdn/c3201142/919bcdb8acd54cd305a99009cb24feb811b5a82a3239db6c33e37696fa418fa5,w400.png)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#spacex
https://wykop.pl/wpis/78536067/spacex-starship-piaty-start-starshipa-bedzie-lapan