Aktywne Wpisy

taka_sobie_ +113
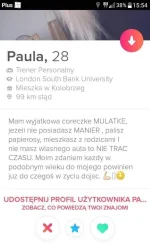
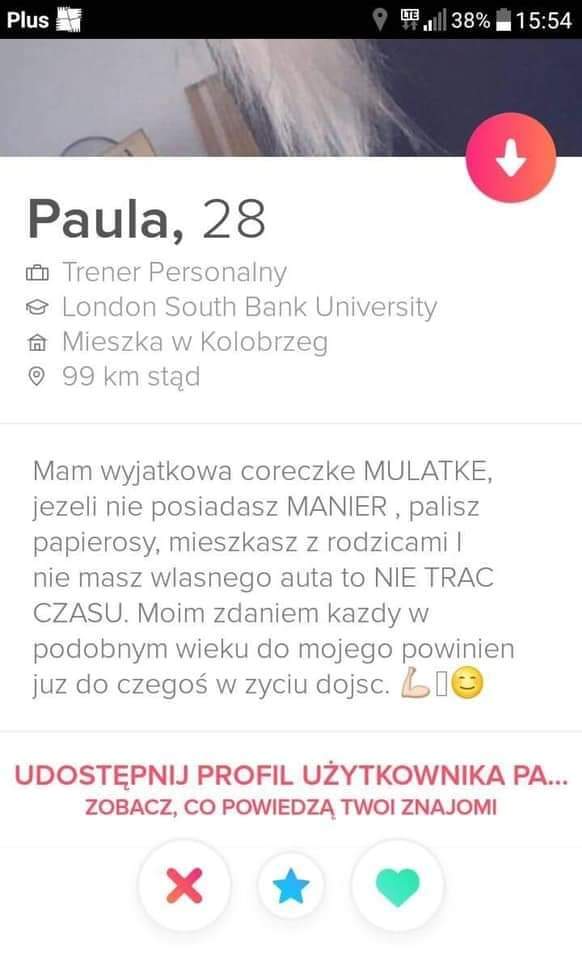
Nie byłabym z tatusiem mającym już guwniaka choćby był 10/10 albo ostatnim facetem na ziemi. Dlaczego? Kilka z brzegu powodów:
- na dzień dobry jestem na drugim miejscu
- wiecznie musi mieć kontakt z byłą, jeżdżąc do dziecka widzi się z nią, pije kawkę i #!$%@? wie co jeszcze tam robią jak dzieciak pójdzie na drzemkę, ale ja oczywiście pewnie miałabym zakaz kontaktu z byłymi xD
- wieczne wtrącanie się byłej w
- na dzień dobry jestem na drugim miejscu
- wiecznie musi mieć kontakt z byłą, jeżdżąc do dziecka widzi się z nią, pije kawkę i #!$%@? wie co jeszcze tam robią jak dzieciak pójdzie na drzemkę, ale ja oczywiście pewnie miałabym zakaz kontaktu z byłymi xD
- wieczne wtrącanie się byłej w

atrax15 +214
źródło: temp_file6917772698856058183
Pobierz


{kind=link}
źródło: 125284523_3803893073008252_2051120019638410523_n
Pobierz@e-stark: właśnie nie. Commituje się małe zmiany ale przynoszące wartość
@m4kb0l: *Ja patrzący na 400 zmienionych plików po małych refaktoryzacjach, które zrobiłem przy okazji dodawania nowego przycisku*
Squash należy robić tylko w sytuacji
https://www.aleksandrhovhannisyan.com/blog/atomic-git-commits/
Może Ty. Pisz za siebie.
@Krolik tak, tak. Twój kod nie zostawia żadnego długu technologicznego i jest czysty jak łza xD Weź nie opowiadaj takich głupot bo ktoś mniej doświadczony to przeczyta i w to uwierzy.
@Krolik Ja nie wiem czy ja piszę po chińsku czy Ty czegoś nie rozumiesz. Szkoda mi jednak czasu na dyskusje bo widać
A co do commitów to problem polega na tym że Ty się odwołujesz do jakiegoś subiektywnego
A tak na marginesie, co do
A dokumentacja oczywiście tak jak najbardziej musi być i jest bardzo ważna. Ale w