
Mirki, prosta sprawa a mnie przerosła. Baza w formacie .bak z SQLa 2019 musi zostać przekonwertowana do 2016. Macie jakieś pomysły?
Wygenerowalem skrypt pod 2016, odpalam i wyrzuca errory...
Są jakieś zewnętrzne softy co mogą to ogarnąć?
#sql #programowanie #bazydanych
Wygenerowalem skrypt pod 2016, odpalam i wyrzuca errory...
Są jakieś zewnętrzne softy co mogą to ogarnąć?
#sql #programowanie #bazydanych






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
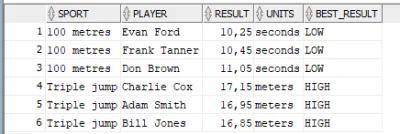
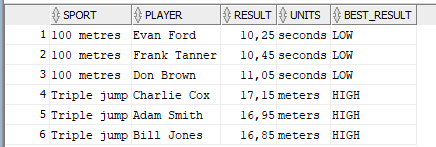
mireczki problem jest, mam taki kod: jdoodle.com/ia/icH
wszystkie opcje działają poza tą gdzie oba inputy są NULL, wtedy nie zwraca niczego. dlaczego tak się dzieję? ten sam wycinek kodu działa poza tą funkcją więc jest dobrze napisany... :/
IF (@srsNumber IS NULL)
gdzie w środku masz WHERE tblAuthor.AuthorName LIKE '%' + @authName + '%' a @authName też jest NULL
Czy te warunki to raczej tak nie powinny wyglądać? https://www.jdoodle.com/ia/icK