Aktywne Wpisy

kikiton +108
#1670 #seriale #netflix #humorobrazkowy #humor
Z kabaretów się śmiejecie że wasi starzy oglądają a to dziadostwo jest na podobnym poziomie choć wydaje mi się że nawet niższym XD
Z kabaretów się śmiejecie że wasi starzy oglądają a to dziadostwo jest na podobnym poziomie choć wydaje mi się że nawet niższym XD

źródło: temp_file3150676690150196813
Pobierz
zajsty +408
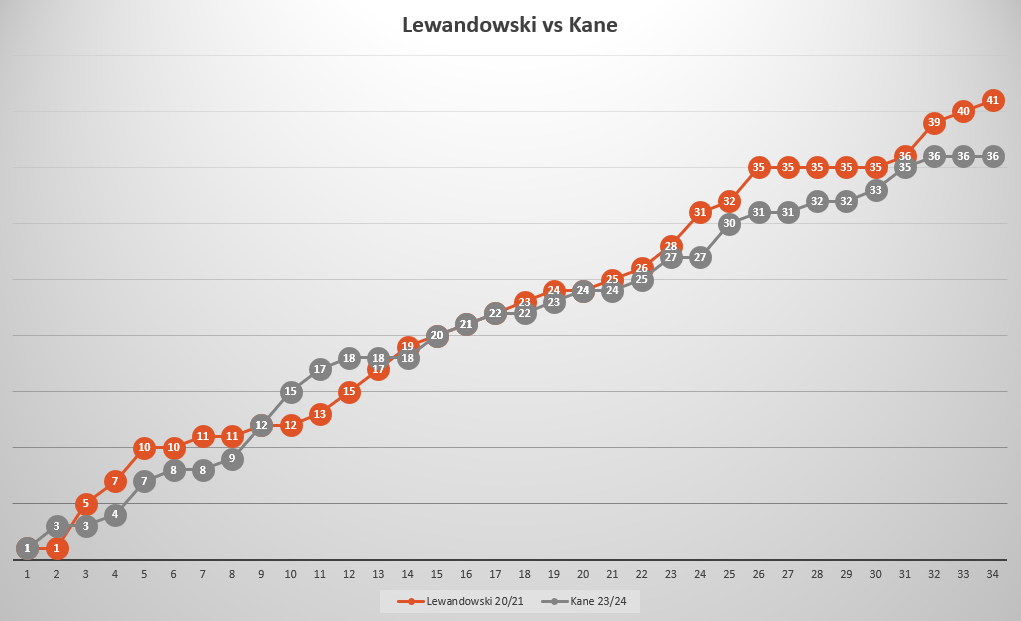
W 34 kolejce Harry Kane poza składem meczowym z powodu kontuzji pleców.
Anglik kończy sezon ligowy 23/24 z wynikiem 36 goli w 32 spotkaniach.
W komentarzach bonusy - wykres z S.Guirassy oraz z G.Müllerem.
Wspaniały to był sezon, nie zapomnę go nigdy.
Dzięki za uwagę i wspólną zabawę.
#bundesliga #pilkanozna #mecz #torjagerkanone2024
Anglik kończy sezon ligowy 23/24 z wynikiem 36 goli w 32 spotkaniach.
W komentarzach bonusy - wykres z S.Guirassy oraz z G.Müllerem.
Wspaniały to był sezon, nie zapomnę go nigdy.
Dzięki za uwagę i wspólną zabawę.
#bundesliga #pilkanozna #mecz #torjagerkanone2024

źródło: LK34
Pobierz




{kind=link}
{kind=link}
#sed #bash #skryptowanie #linux
awk -F';' -v i=1 'NR>1 && $i!=p { print "" }{ p=$i } 1'
tylko musiałem w sumie walnąć taki kawał tekstu:
cat calosc.txt | sed -n 's/\(^[0-9]\)/\1;/p' | awk -F';' -v i=1 'NR>1 && $i!=p { print "" }{ p=$i } 1' | sed 's/\(^[0-9]\);\([0-9]\{3\}\)/\1\2/' > calosc_ok.txt
żeby to zadziałało jak potrzebuję. No ale działa :)
FILE='test.file'
while read LINE
do
if [ "$LINE" = "" ]
then
continue
fi
FIRSTL="$(echo $LINE | head -c 1)"
echo $LINE >> $FIRSTL'.txt'
if [ "$FIRSTL" != "$OLDL" ]
then
echo
fi
OLDL=$FIRSTL
done < $FILE
Spóźniłem się :)