
10 ORE => 10 A
1 ORE => 1 B
7 A, 1 B => 1 C
7 A, 1 C => 1 D
7 A, 1 D => 1 E
7 A, 1 E => 1 FUELWszystko
Najnowsze
Archiwum


#programowanie #regex #wyrazeniaregularne
jak do
jak do
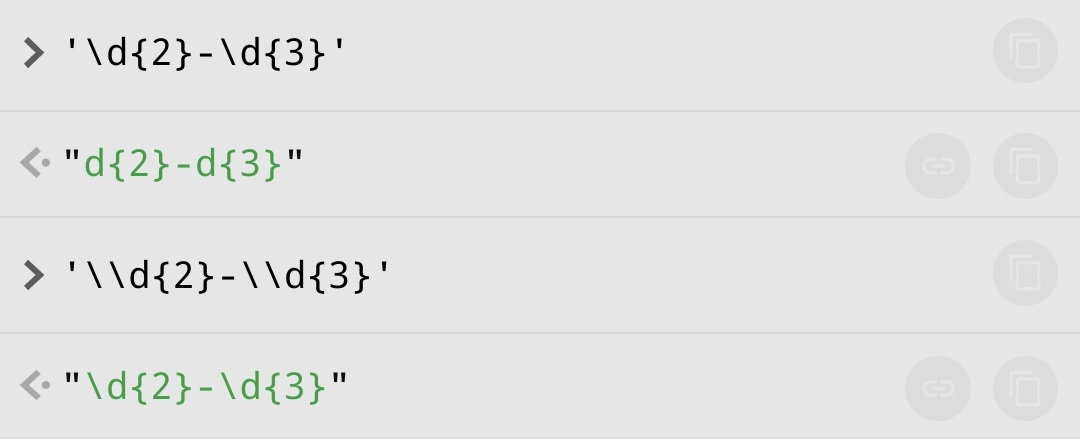
Login1, Loginasdsadf2, Logiasfsdfn, Loginsadfsd1, Loginsdf1, Logsadfsdfin1 dodać @ na początku każdego loginu i usunąć przecinki?


@scorpio18k: Jak po „+” albo „*” dasz znak zapytania to te operatory stają się „leniwe”, tj. próbują zmatchowac minimalną liczbę znaków. W innym wypadku są zachłanne - matchują w opór.
Regex101 z reszta ładnie to tłumaczy:
1st Capturing Group
Regex101 z reszta ładnie to tłumaczy:
1st Capturing Group
RegEx - Strona do nauki, testowania, budowania wyrażeń regularnych.
Wyrażenia regularne są językiem, dzięki któremu za pomocą odpowiednich operatorów możemy dopasować dowolny ciąg znaków spełniający nasze założenia.
z- 5
- #
- #
- #
- #
- #
- #
Jak najłatwiej pobrać nazwę paczkomatu ze stringu:
Paczkomat nr: DGO18M, Adres: Krasińskiego 3, 41-300 Dąbrowa Górnicza
Paczkomat nr: DGO18M Adres: Krasińskiego 3, 41-300 Dąbrowa Górnicza
Czasem po nazwię paczkomatu jest przecinek, a czasem nie ma... jakiś regex?
Paczkomat nr: DGO18M, Adres: Krasińskiego 3, 41-300 Dąbrowa Górnicza
Paczkomat nr: DGO18M Adres: Krasińskiego 3, 41-300 Dąbrowa Górnicza
Czasem po nazwię paczkomatu jest przecinek, a czasem nie ma... jakiś regex?
@Serghio: to w zupełnie innym celu. Po prostu pobieram sobie sprzedaże z allegro, erli, areny do własnego systemu, przez który sobie automatycznie tworze etykiety do wydruku przez api inpostu, a tam trzeba podać nazwę paczkomatu. Allegro czy erli zwracają wybrany paczkomat w poprawnym formacie, niestety arena wyświetla całość jako komentarz do zamówienia, dlatego musiałem to jakoś obejść.
Cześć, czy ktos potrafi mi pomóc i odpowiedzieć na pytanie czemu ten regex w angularze (typescript) nie działa poprawnie dla kodu pocztowego?
Otóz mam taka sytuacje :
w Form builderze tworze pole :
postalCode: [
'',
Otóz mam taka sytuacje :
w Form builderze tworze pole :
postalCode: [
'',
konto usunięte via Wykop Mobilny (Android)
@FortresMaximus ja bym kombinował tak:
- być może backslash trzeba dodatkowo wyescapować bo znajduje się w stringu
- Validators.pattern przyjmuje też regexp, także przekazanie pełnego regexpa może rozwiązać problem
- być może backslash trzeba dodatkowo wyescapować bo znajduje się w stringu
- Validators.pattern przyjmuje też regexp, także przekazanie pełnego regexpa może rozwiązać problem
źródło: comment_1630740990x36CJ8ERSj11nqAeh1R3Tr.jpg
Pobierz@aloucie dziękuję, wczoraj udało mi się to rozwiązać na sam wieczór
Hej,
W jaki sposób mogę przeparsować argumenty w określonym wywołaniu funkcji?
Przykładowo mam takie wywołanie(zawsze wiem z iloma argumentami będzie wywoływane)
obj.call("a1", "a2", "a3")
W jaki sposób mogę przeparsować argumenty w określonym wywołaniu funkcji?
Przykładowo mam takie wywołanie(zawsze wiem z iloma argumentami będzie wywoływane)
obj.call("a1", "a2", "a3")

@qarmin: Takich rzeczy raczej nie robi się regexami, większość języków z którymi miałem styczność miała jakieś narzędzia do manipulacji kodu, na przykład przy JSie możesz używać Babel albo API kompilatora TypeScriptu, kod przerabiany jest na AST (Abstract Syntax Tree) i tam możesz łatwo robić co chcesz

@qarmin: napisz własną gramatykę przy użyciu np tego
https://github.com/yhirose/cpp-peglib . Jak header only nie pasuje to możesz napisać coś takiego samemu. Iterujesz się po każdym znaku. Dla każdego typu nawiasów trzymasz licznik, który odpowiednio zwiekszasz/zmniejszasz gdy napotkasz nawias otwierający/zamykający. Jak napotkasz przycinek to sprawdzasz licznik nawiasów: jak wszystkie są na 0 (nie liczymy tego głównego) to masz granicę pomiędzy argumentami
https://github.com/yhirose/cpp-peglib . Jak header only nie pasuje to możesz napisać coś takiego samemu. Iterujesz się po każdym znaku. Dla każdego typu nawiasów trzymasz licznik, który odpowiednio zwiekszasz/zmniejszasz gdy napotkasz nawias otwierający/zamykający. Jak napotkasz przycinek to sprawdzasz licznik nawiasów: jak wszystkie są na 0 (nie liczymy tego głównego) to masz granicę pomiędzy argumentami

@mamniciwszystko: za 50 zł ci napiszę w sumie xd

Naklepałem sobie regexa który matchuje mi stringa z dwoma datami przedzielonymi znakiem /
Dla przykładu: 07-03-2020/08-03-2020
Czy można ogarnąć tego regexa tak żeby nie powtarzać go dwa razy, przed znakiem / i po znaku / ?
(?:0[1-9]|2[0-9]|3[0-1])-(?:0[1-9]|1[1-2])-\d{4}/(?:0[1-9]|2[0-9]|3[0-1])-(?:0[1-9]|1[1-2])-\d{4}
Dla przykładu: 07-03-2020/08-03-2020
Czy można ogarnąć tego regexa tak żeby nie powtarzać go dwa razy, przed znakiem / i po znaku / ?
(?:0[1-9]|2[0-9]|3[0-1])-(?:0[1-9]|1[1-2])-\d{4}/(?:0[1-9]|2[0-9]|3[0-1])-(?:0[1-9]|1[1-2])-\d{4}
@Tacocat: To nie jest poprawny regex do tego problemu. Pozwala na brak znaku / po środku
Ale zajebistego regexa napisałem, i działa!
(.{3,5}\/XYZ\/(?:0[1-9]|1[012])\/\d{4})
#chwalesie #regex #programowanie
(.{3,5}\/XYZ\/(?:0[1-9]|1[012])\/\d{4})
#chwalesie #regex #programowanie

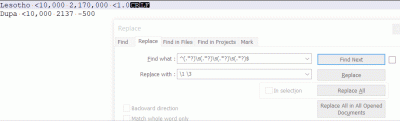
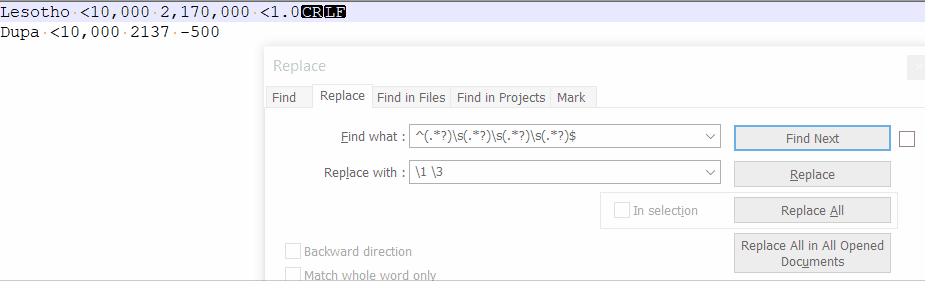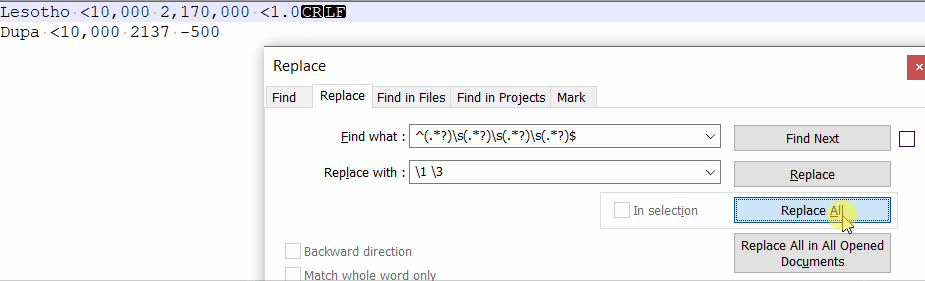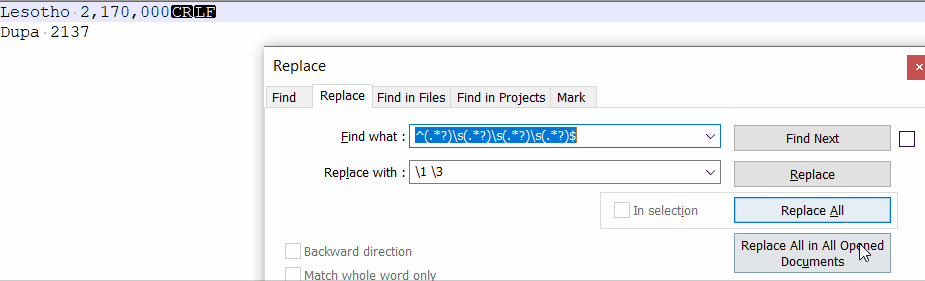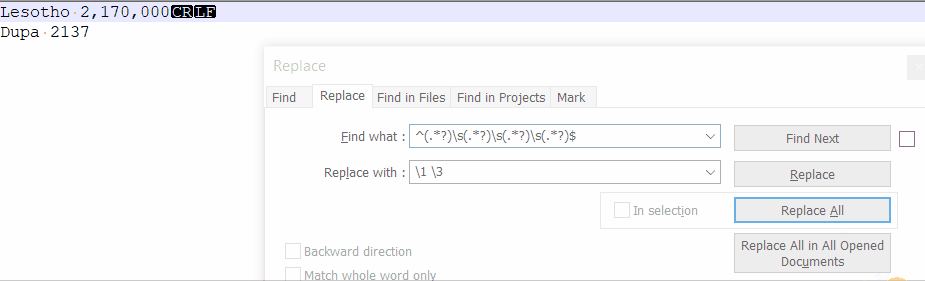
jak #regex em usuwać z każdej linii np. drugi i czwarty wyraz
jeśli to coś ułatwi zawsze usuwamy ostatni
możemy założyć, że znaki jakie tam będą to cyfry, znak mniejszości i kropka
np. z takiego
Lesotho <10,000 2,170,000 <1.0
jeśli to coś ułatwi zawsze usuwamy ostatni
możemy założyć, że znaki jakie tam będą to cyfry, znak mniejszości i kropka
np. z takiego
Lesotho <10,000 2,170,000 <1.0
@deadIift: skopiuj i wklej do gsheets :)
wciśnij i trzymaj lewy ctrl, potem kursorem zaznacz sobie od rogu tabeli (jednej komórki) i przeciągnij myszkę po przekątnej do konca tabeli, legancko sobie zaznaczysz wszystko, potem ctrl+c i w gsheets ctrl-v.
Tam już jest łatwiej usunąć kolumny niż bawić się z notatnikiem
wciśnij i trzymaj lewy ctrl, potem kursorem zaznacz sobie od rogu tabeli (jednej komórki) i przeciągnij myszkę po przekątnej do konca tabeli, legancko sobie zaznaczysz wszystko, potem ctrl+c i w gsheets ctrl-v.
Tam już jest łatwiej usunąć kolumny niż bawić się z notatnikiem
@deadIift:
Ale łatwiej jest zwyczajnie zrobić splita jak człowiek. Oddajesz konto na Codecademy a nie potrafisz napisać skryptu na wybranie pierwszego i trzeciego wyrazu? ( ͡° ͜ʖ ͡°)
Ale łatwiej jest zwyczajnie zrobić splita jak człowiek. Oddajesz konto na Codecademy a nie potrafisz napisać skryptu na wybranie pierwszego i trzeciego wyrazu? ( ͡° ͜ʖ ͡°)
źródło: comment_1618738509iWYlOUOYOKMnTjq8lCKcjo.gif
Pobierz
Jak ktoś nie umie regexów to pewnie mu się przyda:
https://github.com/pemistahl/grex
#regex #programowanie
https://github.com/pemistahl/grex
#regex #programowanie
Mirasy, co polecacie do nauki #regex ? Coraz częściej potrzebuję, a męczące jest ciągłe kombinowanie, szukanie i cudowanie ( ͡° ʖ̯ ͡°) Szukam dobrego źródła, zarówno pod kątem #php jak i #javascript
#programowanie
#programowanie
@Dikoo: to regexa da się nauczyć? Ja się go uczę za każdym razem na nowo, a tydzień później i tak już nic nie pamiętam :P

Ja się uczyłem w momencie, gdy potrzebowałem jakiegoś konkretnego regex metodą prób i błędów za pomocą https://regex101.com/
Tam na żywo masz informację, co będzie wynikiem, a obok masz jakiś taki "słowniczek" selektorów/tokenów (czy jak to się tam nazywa).
Tam na żywo masz informację, co będzie wynikiem, a obok masz jakiś taki "słowniczek" selektorów/tokenów (czy jak to się tam nazywa).
Pytanie z kategorii regex: W jaki sposob mozna skomponowac wyrazenie, ktore matchuje np. wszystkie adresy url, poza jakimis wyjatkami, np. z domeny amazona?
#programowanie #naukaprogramowania #wyrazeniaregularne #regex #regexp
#programowanie #naukaprogramowania #wyrazeniaregularne #regex #regexp
@UberRam: https://stackoverflow.com/a/1240293/4638604 , tyle, że jak zachodzi konieczność na look-ahead/look-behind, to lepiej rozwiązać problem w inny sposób np. dwa regexy: jeden sprawdza czy przepuścić a drugi, czy odrzucić

@UberRam: Lepiej użyć gotowego parsera url-i.

Poleci ktoś jakiś poradnik do #regex
Najlepsza była by nie za duża ksiąka w formie przykładów użycia, bez zbędnej teorii póki co.
#programowanie
Najlepsza była by nie za duża ksiąka w formie przykładów użycia, bez zbędnej teorii póki co.
#programowanie
@Zeronader: Wyrażenia regularne. Wprowadzenie - krótka książka + dzień ćwiczeń

Dałoby radę spiąć te wszystkie warunki w jednym wyrażeniu, czy muszę zrobić pare wyrażeń do dopasowania?
#regex #programowanie
#regex #programowanie

źródło: comment_16102686973CXUAgdoW4nd7BXJ8MiiMx.jpg
Pobierz
@zoomer21_: jedli możesz, unikaj regexów. Zdecydowanie lepiej i łatwiej jest to zrobić pętlą i
ifami niż wpychać regexpa.@zoomer21_: więc skoro to jest mały projekt na zaliczenie, to tym bardziej - zamiast krótkiej pętelki i dwóch
ifów używasz całej rozbudowanej niedeterministycznej maszyny stanowej (bo skoro masz look back, to nie są to wyrażenia regularne) i jeszcze musisz się pytać na forum jak to rozwiązać. To ma być prostsze rozwiązanie? Serio? To pokazuje w jak złym stanie jest nauczanie programowania teraz.
#regexp #regex #programowanie
Czy jest tu jakiś spec od regexów?
Dla stringa
Czy jest tu jakiś spec od regexów?
(?:(?!\1))(\d)\1\bDla stringa
888 mam full match 88, ale z tego, co rozumiem, to (?:(?!\1)) powinien eliminować ósemkę na początku i nie dać matcha. Zresztą jak zamieniam \1 na 8, to tak rzeczywiście jest. To ja już nie wiem, jak zrobić, żeby tej pierwszej grupy (w tym przypadku pojedynczej ósemki) nie brał. Rzecz w tym, że to
@zwei: nie pamiętam dokładnej nazwy, ale to ma chyba związek z wyszukiwaniem wstecznym. Normalnie regex jest maszyną stanów, która przetwarza tekst tylko wprzód. Tutaj masz backmatching. Rzucam tylko wskazówkę, powinieneś znaleźć odpowiednią flagę

@zwei: To
(?!...) (negative lookahead) działa w odniesieniu do aktualnej pozycji (w twoim przypadku początek), więc to nic nie robi - znaczy match będzie się opierał tylko na powtórzonych ostatnich cyfrach, bo na początku sprawdzasz czy po tym co już dopasowałeś (jeszcze nic) jest coś innego niż to co będzie następne. Dlatego też non-capture nie potrzebny, bo to nie jest nawet dopasowywany ciąg tylko założenie dotyczące tego z czym "sąsiaduje".
{kind=link}
{kind=link}
{kind=link}
Ktoś pomoże z regexem? Chodzi o to, że nie łapie tego ostatniego key:value pair, bo nie ma white-space żadnego, a nie wiem jak to zrobić, regexy są dla mnie jak czarna magia ( ͡° ʖ̯ ͡°)
Link: https://regex101.com/r/bKnD9I/1
#programowanie #regex
Link: https://regex101.com/r/bKnD9I/1
#programowanie #regex
@spaduwa_mam_robote: Cieszę się, że mogłem pomóc.
#regex
dawno dawno temu korzystałem delikatnie z regexów i teraz mi są turbo potrzebne xD
Mam string "X/0/12/34/5678/9" i muszę z niego wyciągnąć "12", totalnie nie mam pomysłu jak to zrobić, szczególnie, że pierwszy i drugi segment ("0" i "12") czasem jest jedno a czasem dwucyfrowy (zawsze liczba, nigdy znak).
Pewnie to banał ale nie pamiętam tego za cholere xD
#javascript
A co do wykorzystania to jestem ameba z js, ostatnio coś pisałem w 2016 xD także będę tryhardował