
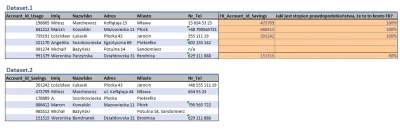
W pracy mam projekt gdzie pracujemy na Hadoop, Hive, Apache NiFi, Pysparku i Tableau. Mam pewien task do zrobienia: odpalać shellowy skrypt jeżeli tabela w bazie danych zostanie zaktualizowana. Jest jakiś processor w nifi który nasłuchuje i sprawdza czy wpadły nowe rekordy do tabeli? Nie wiem jak to zrobić, nie chce odpalać zapytania sql co minutę i sprawdzać ilość rekordów. Czy jest coś lepszego co mogę użyć?
#programowanie #bigdata
#programowanie #bigdata













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#datascience
#dataengineering
#programowanie
Komentarz usunięty przez autora