Aktywne Wpisy

mirko_anonim +8
✨️ Obserwuj #mirkoanonim
mirki potrzebuje porady prawnej. #prawo
otoz #!$%@? rozwalilem 3 lusterka i mnie zlapali, teraz mam sprawe w sadzie. szkody na ~10k bo #leasing. czy moge sie jakos dogadac z tymi ludzmi?
prokurator mowi ze dostane za to odrobki 8msc po 20h.
Problem polega na tym ze nie stac mnie na zaplate tego, czy da sie dogadac z tymi ludzmi zeby zaplacic mniej za te lusterka? to az tyle
mirki potrzebuje porady prawnej. #prawo
otoz #!$%@? rozwalilem 3 lusterka i mnie zlapali, teraz mam sprawe w sadzie. szkody na ~10k bo #leasing. czy moge sie jakos dogadac z tymi ludzmi?
prokurator mowi ze dostane za to odrobki 8msc po 20h.
Problem polega na tym ze nie stac mnie na zaplate tego, czy da sie dogadac z tymi ludzmi zeby zaplacic mniej za te lusterka? to az tyle

WielkiNos +103
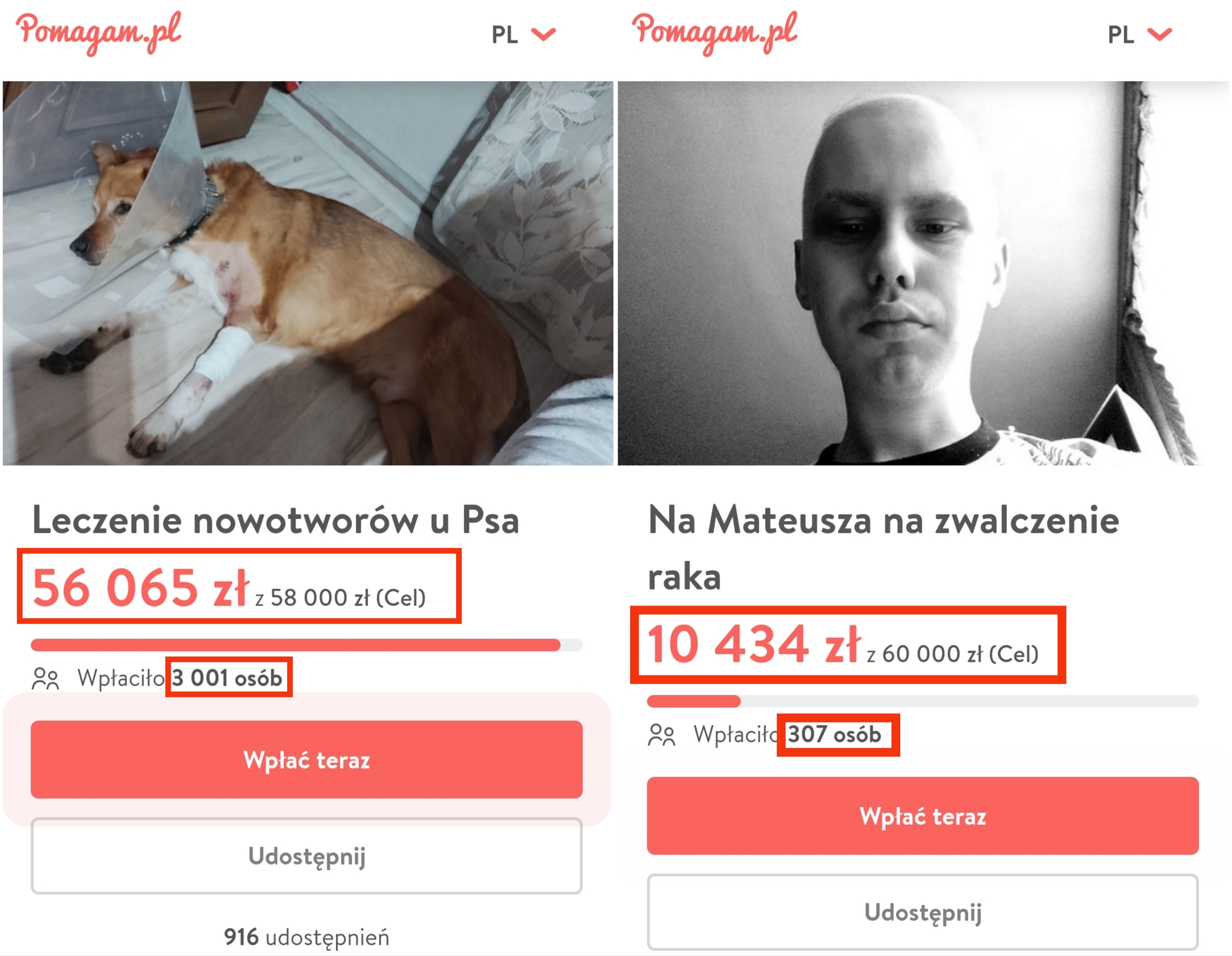
Współczesny świat. Po lewej stary 14 letni pies z rakiem, który pewnie za rok albo pół i tak umrze. Kwota mimo to prawie uzbierana. Wpłaciło ponad 3000 osób.
Po prawej młody chłopak, który miał całe życie przed sobą. Podobna kwota, uzbierana tylko mała część. Wpłaciło 2700 osób mniej niż na psa. Tego człowieka już z nami nie ma.
#psiarze #bekazpodludzi #dogpill #takaprawda #pomagajzwykopem
Po prawej młody chłopak, który miał całe życie przed sobą. Podobna kwota, uzbierana tylko mała część. Wpłaciło 2700 osób mniej niż na psa. Tego człowieka już z nami nie ma.
#psiarze #bekazpodludzi #dogpill #takaprawda #pomagajzwykopem
źródło: temp_file5281614846557045684
Pobierz




{kind=link}
#java #programowanie
Gdyby to był tak po prostu antywzorzec to byś nie implemtowal nawet listy dwukierunkowej, albo drzew z referencja do węzła, a to podstawowe i powszechnie używane struktury.
Po prostu używaj tego z głową i nie nadużywaj.
@markaron: użycie ORMów jak Hibernate/NHibernate samo jest antywzorcem :P